 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Dynamic Embedding for Irregularly Sampled Time Series
Apr 08, 2025In several practical applications, particularly healthcare, clinical data of each patient is individually recorded in a database at irregular intervals as required. This causes a sparse and irregularly sampled time series, which makes it difficult to handle as a structured representation of the prerequisites of neural network models. We therefore propose temporal dynamic embedding (TDE), which enables neural network models to receive data that change the number of variables over time. TDE regards each time series variable as an embedding vector evolving over time, instead of a conventional fixed structured representation, which causes a critical missing problem. For each time step, TDE allows for the selective adoption and aggregation of only observed variable subsets and represents the current status of patient based on current observations. The experiment was conducted on three clinical datasets: PhysioNet 2012, MIMIC-III, and PhysioNet 2019. The TDE model performed competitively or better than the imputation-based baseline and several recent state-of-the-art methods with reduced training runtime.
GainAdaptor: Learning Quadrupedal Locomotion with Dual Actors for Adaptable and Energy-Efficient Walking on Various Terrains
Dec 12, 2024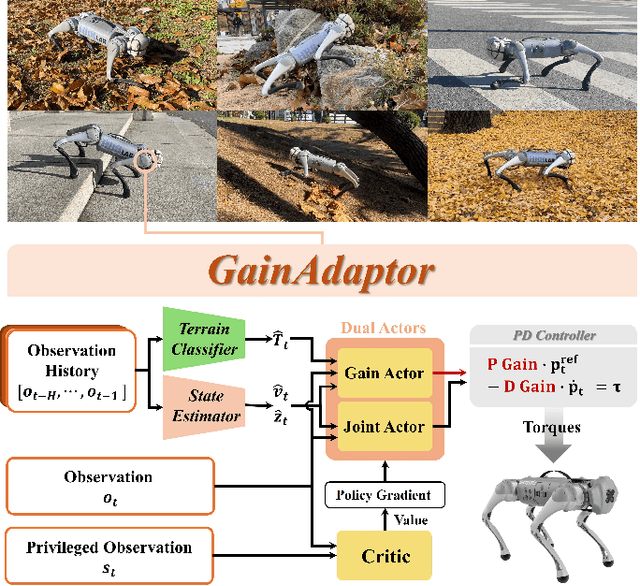


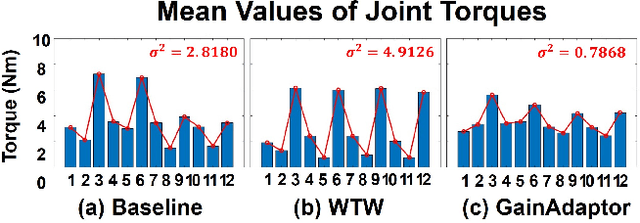
Deep reinforcement learning (DRL) has emerged as an innovative solution for controlling legged robots in challenging environments using minimalist architectures. Traditional control methods for legged robots, such as inverse dynamics, either directly manage joint torques or use proportional-derivative (PD) controllers to regulate joint positions at a higher level. In case of DRL, direct torque control presents significant challenges, leading to a preference for joint position control. However, this approach necessitates careful adjustment of joint PD gains, which can limit both adaptability and efficiency. In this paper, we propose GainAdaptor, an adaptive gain control framework that autonomously tunes joint PD gains to enhance terrain adaptability and energy efficiency. The framework employs a dual-actor algorithm to dynamically adjust the PD gains based on varying ground conditions. By utilizing a divided action space, GainAdaptor efficiently learns stable and energy-efficient locomotion. We validate the effectiveness of the proposed method through experiments conducted on a Unitree Go1 robot, demonstrating improved locomotion performance across diverse terrains.
Learning Quadrupedal Locomotion with Impaired Joints Using Random Joint Masking
Mar 01, 2024
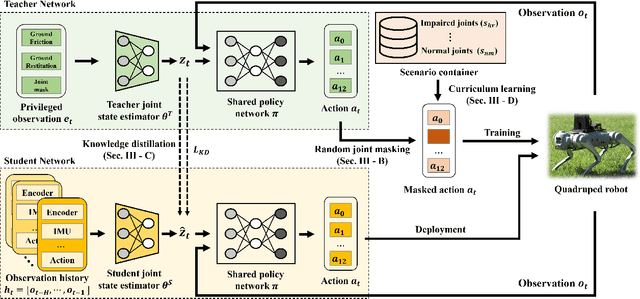
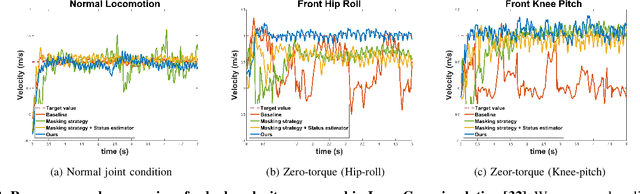

Quadrupedal robots have played a crucial role in various environments, from structured environments to complex harsh terrains, thanks to their agile locomotion ability. However, these robots can easily lose their locomotion functionality if damaged by external accidents or internal malfunctions. In this paper, we propose a novel deep reinforcement learning framework to enable a quadrupedal robot to walk with impaired joints. The proposed framework consists of three components: 1) a random joint masking strategy for simulating impaired joint scenarios, 2) a joint state estimator to predict an implicit status of current joint condition based on past observation history, and 3) progressive curriculum learning to allow a single network to conduct both normal gait and various joint-impaired gaits. We verify that our framework enables the Unitree's Go1 robot to walk under various impaired joint conditions in real-world indoor and outdoor environments.
Differential Spiral Joint Mechanism for Coupled Variable Stiffness Actuation
Jan 22, 2023In this study, we present the Differential Spiral Joint (DSJ) mechanism for variable stiffness actuation in tendon-driven robots. The DSJ mechanism semi-decouples the modulation of position and mechanical stiffness, allowing independent trajectory tracking in different parameter space. Past studies show that increasing the mechanical stiffness achieves the wider range of renderable stiffness, whereas decreasing the mechanical stiffness improves the quality of actuator decoupling and shock absorbance. Therefore, it is often useful to modulate the mechanical stiffness to balance the required level of stiffness and safety. In addition, the DSJ mechanism offers a compact form factor, which is suitable for applications where the size and weight are important. The performance of the DSJ mechanism in various areas is validated through a set of experiments.
SCAPE: Learning Stiffness Control from Augmented Position Control Experiences
Feb 16, 2021

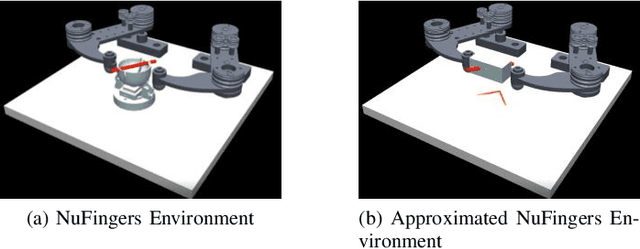
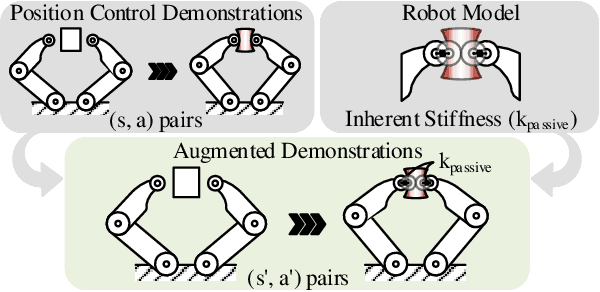
We introduce a sample-efficient method for learning state-dependent stiffness control policies for dexterous manipulation. The ability to control stiffness facilitates safe and reliable manipulation by providing compliance and robustness to uncertainties. So far, most current reinforcement learning approaches to achieve robotic manipulation have exclusively focused on position control, often due to the difficulty of learning high-dimensional stiffness control policies. This difficulty can be partially mitigated via policy guidance such as in imitation learning. However, expert stiffness control demonstrations are often expensive or infeasible to record. Therefore, we present an approach to learn Stiffness Control from Augmented Position control Experiences (SCAPE) that bypasses this difficulty by transforming position control demonstrations into approximate, suboptimal stiffness control demonstrations. Then, the suboptimality of the augmented demonstrations is addressed by using complementary techniques that help the agent safely learn from both the demonstrations and reinforcement learning. By using simulation tools and experiments on a robotic testbed, we show that the proposed approach efficiently learns safe manipulation policies and outperforms learned position control policies and several other baseline learning algorithms.