 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopKGAT: A Top-K Objective-Driven Architecture for Recommendation
Jan 26, 2026Recommendation systems (RS) aim to retrieve the top-K items most relevant to users, with metrics such as Precision@K and Recall@K commonly used to assess effectiveness. The architecture of an RS model acts as an inductive bias, shaping the patterns the model is inclined to learn. In recent years, numerous recommendation architectures have emerged, spanning traditional matrix factorization, deep neural networks, and graph neural networks. However, their designs are often not explicitly aligned with the top-K objective, thereby limiting their effectiveness. To address this limitation, we propose TopKGAT, a novel recommendation architecture directly derived from a differentiable approximation of top-K metrics. The forward computation of a single TopKGAT layer is intrinsically aligned with the gradient ascent dynamics of the Precision@K metric, enabling the model to naturally improve top-K recommendation accuracy. Structurally, TopKGAT resembles a graph attention network and can be implemented efficiently. Extensive experiments on four benchmark datasets demonstrate that TopKGAT consistently outperforms state-of-the-art baselines. The code is available at https://github.com/StupidThree/TopKGAT.
Timeliness-Oriented Scheduling and Resource Allocation in Multi-Region Collaborative Perception
Jan 08, 2026Collaborative perception (CP) is a critical technology in applications like autonomous driving and smart cities. It involves the sharing and fusion of information among sensors to overcome the limitations of individual perception, such as blind spots and range limitations. However, CP faces two primary challenges. First, due to the dynamic nature of the environment, the timeliness of the transmitted information is critical to perception performance. Second, with limited computational power at the sensors and constrained wireless bandwidth, the communication volume must be carefully designed to ensure feature representations are both effective and sufficient. This work studies the dynamic scheduling problem in a multi-region CP scenario, and presents a Timeliness-Aware Multi-region Prioritized (TAMP) scheduling algorithm to trade-off perception accuracy and communication resource usage. Timeliness reflects the utility of information that decays as time elapses, which is manifested by the perception performance in CP tasks. We propose an empirical penalty function that maps the joint impact of Age of Information (AoI) and communication volume to perception performance. Aiming to minimize this timeliness-oriented penalty in the long-term, and recognizing that scheduling decisions have a cumulative effect on subsequent system states, we propose the TAMP scheduling algorithm. TAMP is a Lyapunov-based optimization policy that decomposes the long-term average objective into a per-slot prioritization problem, balancing the scheduling worth against resource cost. We validate our algorithm in both intersection and corridor scenarios with the real-world Roadside Cooperative perception (RCooper) dataset. Extensive simulations demonstrate that TAMP outperforms the best-performing baseline, achieving an Average Precision (AP) improvement of up to 27% across various configurations.
ProBench: Benchmarking GUI Agents with Accurate Process Information
Nov 12, 2025With the deep integration of artificial intelligence and interactive technology, Graphical User Interface (GUI) Agent, as the carrier connecting goal-oriented natural language and real-world devices, has received widespread attention from the community. Contemporary benchmarks aim to evaluate the comprehensive capabilities of GUI agents in GUI operation tasks, generally determining task completion solely by inspecting the final screen state. However, GUI operation tasks consist of multiple chained steps while not all critical information is presented in the final few pages. Although a few research has begun to incorporate intermediate steps into evaluation, accurately and automatically capturing this process information still remains an open challenge. To address this weakness, we introduce ProBench, a comprehensive mobile benchmark with over 200 challenging GUI tasks covering widely-used scenarios. Remaining the traditional State-related Task evaluation, we extend our dataset to include Process-related Task and design a specialized evaluation method. A newly introduced Process Provider automatically supplies accurate process information, enabling presice assessment of agent's performance. Our evaluation of advanced GUI agents reveals significant limitations for real-world GUI scenarios. These shortcomings are prevalent across diverse models, including both large-scale generalist models and smaller, GUI-specific models. A detailed error analysis further exposes several universal problems, outlining concrete directions for future improvements.
UniMM-V2X: MoE-Enhanced Multi-Level Fusion for End-to-End Cooperative Autonomous Driving
Nov 12, 2025Autonomous driving holds transformative potential but remains fundamentally constrained by the limited perception and isolated decision-making with standalone intelligence. While recent multi-agent approaches introduce cooperation, they often focus merely on perception-level tasks, overlooking the alignment with downstream planning and control, or fall short in leveraging the full capacity of the recent emerging end-to-end autonomous driving. In this paper, we present UniMM-V2X, a novel end-to-end multi-agent framework that enables hierarchical cooperation across perception, prediction, and planning. At the core of our framework is a multi-level fusion strategy that unifies perception and prediction cooperation, allowing agents to share queries and reason cooperatively for consistent and safe decision-making. To adapt to diverse downstream tasks and further enhance the quality of multi-level fusion, we incorporate a Mixture-of-Experts (MoE) architecture to dynamically enhance the BEV representations. We further extend MoE into the decoder to better capture diverse motion patterns. Extensive experiments on the DAIR-V2X dataset demonstrate our approach achieves state-of-the-art (SOTA) performance with a 39.7% improvement in perception accuracy, a 7.2% reduction in prediction error, and a 33.2% improvement in planning performance compared with UniV2X, showcasing the strength of our MoE-enhanced multi-level cooperative paradigm.
History-Aware Reasoning for GUI Agents
Nov 12, 2025Advances in Multimodal Large Language Models have significantly enhanced Graphical User Interface (GUI) automation. Equipping GUI agents with reliable episodic reasoning capabilities is essential for bridging the gap between users' concise task descriptions and the complexities of real-world execution. Current methods integrate Reinforcement Learning (RL) with System-2 Chain-of-Thought, yielding notable gains in reasoning enhancement. For long-horizon GUI tasks, historical interactions connect each screen to the goal-oriented episode chain, and effectively leveraging these clues is crucial for the current decision. However, existing native GUI agents exhibit weak short-term memory in their explicit reasoning, interpreting the chained interactions as discrete screen understanding, i.e., unawareness of the historical interactions within the episode. This history-agnostic reasoning challenges their performance in GUI automation. To alleviate this weakness, we propose a History-Aware Reasoning (HAR) framework, which encourages an agent to reflect on its own errors and acquire episodic reasoning knowledge from them via tailored strategies that enhance short-term memory in long-horizon interaction. The framework mainly comprises constructing a reflective learning scenario, synthesizing tailored correction guidelines, and designing a hybrid RL reward function. Using the HAR framework, we develop a native end-to-end model, HAR-GUI-3B, which alters the inherent reasoning mode from history-agnostic to history-aware, equipping the GUI agent with stable short-term memory and reliable perception of screen details. Comprehensive evaluations across a range of GUI-related benchmarks demonstrate the effectiveness and generalization of our method.
Towards Scalable Web Accessibility Audit with MLLMs as Copilots
Nov 05, 2025


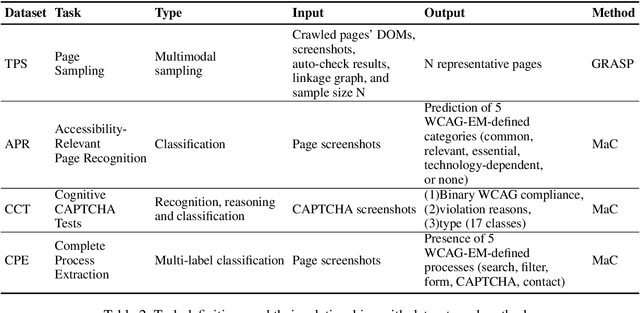
Ensuring web accessibility is crucial for advancing social welfare, justice, and equality in digital spaces, yet the vast majority of website user interfaces remain non-compliant, due in part to the resource-intensive and unscalable nature of current auditing practices. While WCAG-EM offers a structured methodology for site-wise conformance evaluation, it involves great human efforts and lacks practical support for execution at scale. In this work, we present an auditing framework, AAA, which operationalizes WCAG-EM through a human-AI partnership model. AAA is anchored by two key innovations: GRASP, a graph-based multimodal sampling method that ensures representative page coverage via learned embeddings of visual, textual, and relational cues; and MaC, a multimodal large language model-based copilot that supports auditors through cross-modal reasoning and intelligent assistance in high-effort tasks. Together, these components enable scalable, end-to-end web accessibility auditing, empowering human auditors with AI-enhanced assistance for real-world impact. We further contribute four novel datasets designed for benchmarking core stages of the audit pipeline. Extensive experiments demonstrate the effectiveness of our methods, providing insights that small-scale language models can serve as capable experts when fine-tuned.
FedTeddi: Temporal Drift and Divergence Aware Scheduling for Timely Federated Edge Learning
Sep 09, 2025Federated edge learning (FEEL) enables collaborative model training across distributed clients over wireless networks without exposing raw data. While most existing studies assume static datasets, in real-world scenarios clients may continuously collect data with time-varying and non-independent and identically distributed (non-i.i.d.) characteristics. A critical challenge is how to adapt models in a timely yet efficient manner to such evolving data. In this paper, we propose FedTeddi, a temporal-drift-and-divergence-aware scheduling algorithm that facilitates fast convergence of FEEL under dynamic data evolution and communication resource limits. We first quantify the temporal dynamics and non-i.i.d. characteristics of data using temporal drift and collective divergence, respectively, and represent them as the Earth Mover's Distance (EMD) of class distributions for classification tasks. We then propose a novel optimization objective and develop a joint scheduling and bandwidth allocation algorithm, enabling the FEEL system to learn from new data quickly without forgetting previous knowledge. Experimental results show that our algorithm achieves higher test accuracy and faster convergence compared to benchmark methods, improving the rate of convergence by 58.4% on CIFAR-10 and 49.2% on CIFAR-100 compared to random scheduling.
Advancing Loss Functions in Recommender Systems: A Comparative Study with a Rényi Divergence-Based Solution
Jun 18, 2025Loss functions play a pivotal role in optimizing recommendation models. Among various loss functions, Softmax Loss (SL) and Cosine Contrastive Loss (CCL) are particularly effective. Their theoretical connections and differences warrant in-depth exploration. This work conducts comprehensive analyses of these losses, yielding significant insights: 1) Common strengths -- both can be viewed as augmentations of traditional losses with Distributional Robust Optimization (DRO), enhancing robustness to distributional shifts; 2) Respective limitations -- stemming from their use of different distribution distance metrics in DRO optimization, SL exhibits high sensitivity to false negative instances, whereas CCL suffers from low data utilization. To address these limitations, this work proposes a new loss function, DrRL, which generalizes SL and CCL by leveraging R\'enyi-divergence in DRO optimization. DrRL incorporates the advantageous structures of both SL and CCL, and can be demonstrated to effectively mitigate their limitations. Extensive experiments have been conducted to validate the superiority of DrRL on both recommendation accuracy and robustness.
GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies
Jun 17, 2025



The development of high-quality datasets is crucial for benchmarking and advancing research in Graphical User Interface (GUI) agents. Despite their importance, existing datasets are often constructed under idealized conditions, overlooking the diverse anomalies frequently encountered in real-world deployments. To address this limitation, we introduce GUI-Robust, a novel dataset designed for comprehensive GUI agent evaluation, explicitly incorporating seven common types of anomalies observed in everyday GUI interactions. Furthermore, we propose a semi-automated dataset construction paradigm that collects user action sequences from natural interactions via RPA tools and then generate corresponding step and task descriptions for these actions with the assistance of MLLMs. This paradigm significantly reduces annotation time cost by a factor of over 19 times. Finally, we assess state-of-the-art GUI agents using the GUI-Robust dataset, revealing their substantial performance degradation in abnormal scenarios. We anticipate that our work will highlight the importance of robustness in GUI agents and inspires more future research in this direction. The dataset and code are available at https://github.com/chessbean1/GUI-Robust..
FedCGD: Collective Gradient Divergence Optimized Scheduling for Wireless Federated Learning
Jun 09, 2025Federated learning (FL) is a promising paradigm for multiple devices to cooperatively train a model. When applied in wireless networks, two issues consistently affect the performance of FL, i.e., data heterogeneity of devices and limited bandwidth. Many papers have investigated device scheduling strategies considering the two issues. However, most of them recognize data heterogeneity as a property of individual devices. In this paper, we prove that the convergence speed of FL is affected by the sum of device-level and sample-level collective gradient divergence (CGD). The device-level CGD refers to the gradient divergence of the scheduled device group, instead of the sum of the individual device divergence. The sample-level CGD is statistically upper bounded by sampling variance, which is inversely proportional to the total number of samples scheduled for local update. To derive a tractable form of the device-level CGD, we further consider a classification problem and transform it into the weighted earth moving distance (WEMD) between the group distribution and the global distribution. Then we propose FedCGD algorithm to minimize the sum of multi-level CGDs by balancing WEMD and sampling variance, within polynomial time. Simulation shows that the proposed strategy increases classification accuracy on the CIFAR-10 dataset by up to 4.2\% while scheduling 41.8\% fewer devices, and flexibly switches between reducing WEMD and reducing sampling variance.