 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Localization and Power Estimation through RISs: Performance Analysis and Prototype Validations
Dec 12, 2025


This paper investigates the capabilities and effectiveness of backward localization centered on reconfigurable intelligent surfaces (RISs). In the backward sensing paradigm, the region of interest (RoI) is illuminated using a set of diverse radiation patterns. These patterns encode spatial information into a sequence of measurements, which are subsequently processed to reconstruct the RoI. We show that a single RIS can estimate the direction of arrival of incident waves by leveraging configurational diversity, and that the spatial diversity provided by multiple RISs further improves the accuracy of source localization and power estimation. The underlying structure of the sensing operator in the multi-snapshot measurement process is clarified. For single-RIS localization, the sensing operator is decomposed into a product of structured matrices, each corresponding to a specific physical process: wave propagation to and from the RIS, the relative phase offsets of elements with respect to the reference point, and the applied phase configuration of each element. A unified framework for identifying key performance indicators is established by analyzing the conditioning of the sensing operators. In the multi-RIS setting, we derive--via rank analysis--the governing law among the RoI size, the number of elements, and the number of measurements. Upper bounds on the relative error of the least squares reconstruction algorithm are derived. These bounds clarify how key performance indicators affect estimation error and provide valuable guidance for system-level optimization. Numerical experiments confirm that the trend of the relative error is consistent with the theoretical bounds.
Dual Information Speech Language Models for Emotional Conversations
Aug 11, 2025Conversational systems relying on text-based large language models (LLMs) often overlook paralinguistic cues, essential for understanding emotions and intentions. Speech-language models (SLMs), which use speech as input, are emerging as a promising solution. However, SLMs built by extending frozen LLMs struggle to capture paralinguistic information and exhibit reduced context understanding. We identify entangled information and improper training strategies as key issues. To address these issues, we propose two heterogeneous adapters and suggest a weakly supervised training strategy. Our approach disentangles paralinguistic and linguistic information, enabling SLMs to interpret speech through structured representations. It also preserves contextual understanding by avoiding the generation of task-specific vectors through controlled randomness. This approach trains only the adapters on common datasets, ensuring parameter and data efficiency. Experiments demonstrate competitive performance in emotional conversation tasks, showcasing the model's ability to effectively integrate both paralinguistic and linguistic information within contextual settings.
Optimal Transport Regularization for Speech Text Alignment in Spoken Language Models
Aug 11, 2025Spoken Language Models (SLMs), which extend Large Language Models (LLMs) to perceive speech inputs, have gained increasing attention for their potential to advance speech understanding tasks. However, despite recent progress, studies show that SLMs often struggle to generalize across datasets, even for trained languages and tasks, raising concerns about whether they process speech in a text-like manner as intended. A key challenge underlying this limitation is the modality gap between speech and text representations. The high variability in speech embeddings may allow SLMs to achieve strong in-domain performance by exploiting unintended speech variations, ultimately hindering generalization. To mitigate this modality gap, we introduce Optimal Transport Regularization (OTReg), a method that formulates speech-text alignment as an optimal transport problem and derives a regularization loss to improve SLM training. In each training iteration, OTReg first establishes a structured correspondence between speech and transcript embeddings by determining the optimal transport plan, then incorporates the regularization loss based on this transport plan to optimize SLMs in generating speech embeddings that align more effectively with transcript embeddings. OTReg is lightweight, requiring no additional labels or learnable parameters, and integrates seamlessly into existing SLM training procedures. Extensive multilingual ASR experiments demonstrate that OTReg enhances speech-text alignment, mitigates the modality gap, and consequently improves SLM generalization across diverse datasets.
Causal-LLaVA: Causal Disentanglement for Mitigating Hallucination in Multimodal Large Language Models
May 26, 2025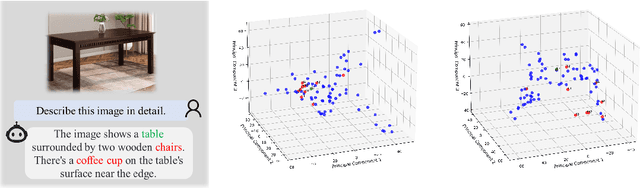
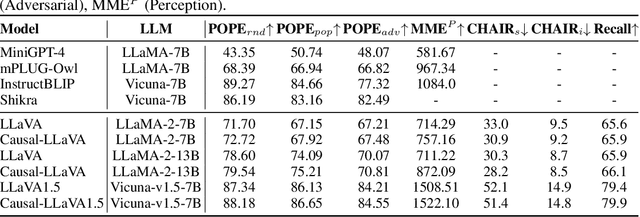
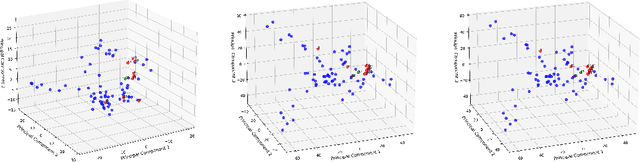
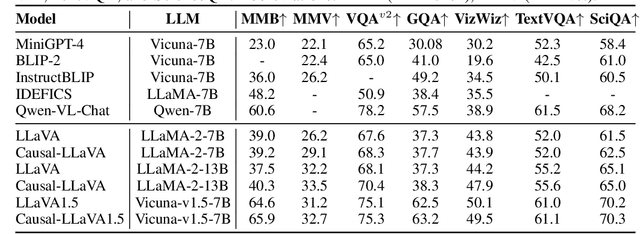
Multimodal Large Language Models (MLLMs) have demonstrated strong performance in visual understanding tasks, yet they often suffer from object hallucinations--generating descriptions of objects that are inconsistent with or entirely absent from the input. This issue is closely related to dataset biases, where frequent co-occurrences of objects lead to entangled semantic representations across modalities. As a result, models may erroneously activate object representations that are commonly associated with the input but not actually present. To address this, we propose a causality-driven disentanglement framework that mitigates hallucinations through causal intervention. Our approach includes a Causal-Driven Projector in the visual pathway and a Causal Intervention Module integrated into the final transformer layer of the language model. These components work together to reduce spurious correlations caused by biased training data. Experimental results show that our method significantly reduces hallucinations while maintaining strong performance on multiple multimodal benchmarks. Visualization analyses further confirm improved separability of object representations. The code is available at: https://github.com/IgniSavium/Causal-LLaVA
GRE Suite: Geo-localization Inference via Fine-Tuned Vision-Language Models and Enhanced Reasoning Chains
May 24, 2025Recent advances in Visual Language Models (VLMs) have demonstrated exceptional performance in visual reasoning tasks. However, geo-localization presents unique challenges, requiring the extraction of multigranular visual cues from images and their integration with external world knowledge for systematic reasoning. Current approaches to geo-localization tasks often lack robust reasoning mechanisms and explainability, limiting their effectiveness. To address these limitations, we propose the Geo Reason Enhancement (GRE) Suite, a novel framework that augments VLMs with structured reasoning chains for accurate and interpretable location inference. The GRE Suite is systematically developed across three key dimensions: dataset, model, and benchmark. First, we introduce GRE30K, a high-quality geo-localization reasoning dataset designed to facilitate fine-grained visual and contextual analysis. Next, we present the GRE model, which employs a multi-stage reasoning strategy to progressively infer scene attributes, local details, and semantic features, thereby narrowing down potential geographic regions with enhanced precision. Finally, we construct the Geo Reason Evaluation Benchmark (GREval-Bench), a comprehensive evaluation framework that assesses VLMs across diverse urban, natural, and landmark scenes to measure both coarse-grained (e.g., country, continent) and fine-grained (e.g., city, street) localization performance. Experimental results demonstrate that GRE significantly outperforms existing methods across all granularities of geo-localization tasks, underscoring the efficacy of reasoning-augmented VLMs in complex geographic inference. Code and data will be released at https://github.com/Thorin215/GRE.
FocusedAD: Character-centric Movie Audio Description
Apr 16, 2025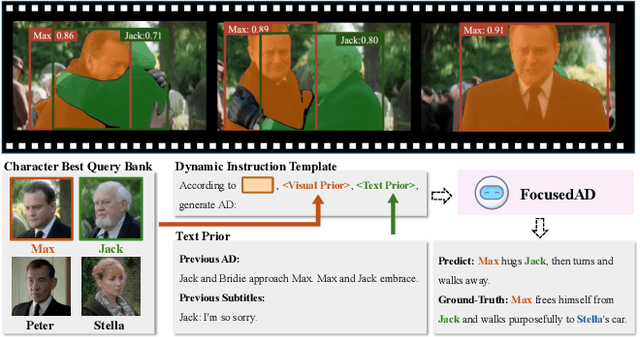
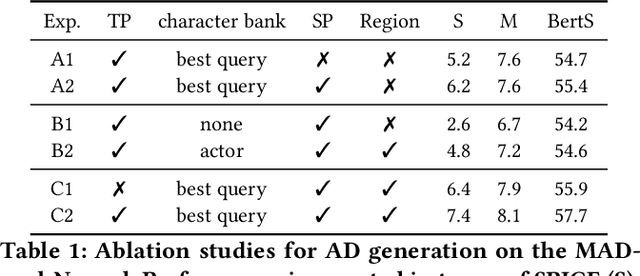
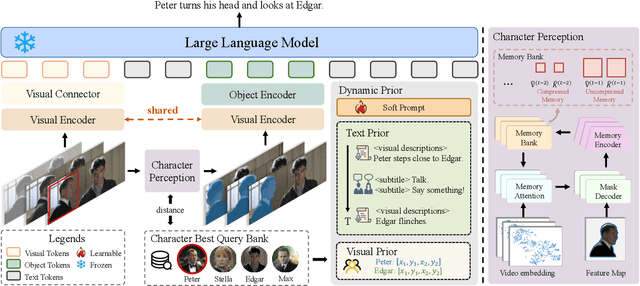
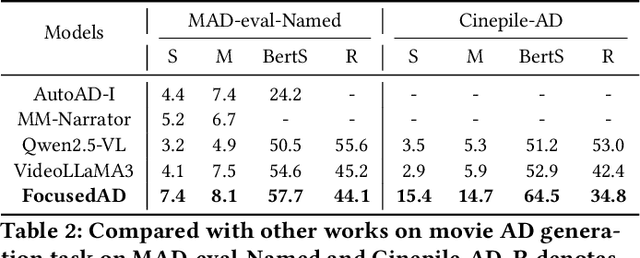
Movie Audio Description (AD) aims to narrate visual content during dialogue-free segments, particularly benefiting blind and visually impaired (BVI) audiences. Compared with general video captioning, AD demands plot-relevant narration with explicit character name references, posing unique challenges in movie understanding.To identify active main characters and focus on storyline-relevant regions, we propose FocusedAD, a novel framework that delivers character-centric movie audio descriptions. It includes: (i) a Character Perception Module(CPM) for tracking character regions and linking them to names; (ii) a Dynamic Prior Module(DPM) that injects contextual cues from prior ADs and subtitles via learnable soft prompts; and (iii) a Focused Caption Module(FCM) that generates narrations enriched with plot-relevant details and named characters. To overcome limitations in character identification, we also introduce an automated pipeline for building character query banks. FocusedAD achieves state-of-the-art performance on multiple benchmarks, including strong zero-shot results on MAD-eval-Named and our newly proposed Cinepile-AD dataset. Code and data will be released at https://github.com/Thorin215/FocusedAD .
Guidance Disentanglement Network for Optics-Guided Thermal UAV Image Super-Resolution
Oct 27, 2024Optics-guided Thermal UAV image Super-Resolution (OTUAV-SR) has attracted significant research interest due to its potential applications in security inspection, agricultural measurement, and object detection. Existing methods often employ single guidance model to generate the guidance features from optical images to assist thermal UAV images super-resolution. However, single guidance models make it difficult to generate effective guidance features under favorable and adverse conditions in UAV scenarios, thus limiting the performance of OTUAV-SR. To address this issue, we propose a novel Guidance Disentanglement network (GDNet), which disentangles the optical image representation according to typical UAV scenario attributes to form guidance features under both favorable and adverse conditions, for robust OTUAV-SR. Moreover, we design an attribute-aware fusion module to combine all attribute-based optical guidance features, which could form a more discriminative representation and fit the attribute-agnostic guidance process. To facilitate OTUAV-SR research in complex UAV scenarios, we introduce VGTSR2.0, a large-scale benchmark dataset containing 3,500 aligned optical-thermal image pairs captured under diverse conditions and scenes. Extensive experiments on VGTSR2.0 demonstrate that GDNet significantly improves OTUAV-SR performance over state-of-the-art methods, especially in the challenging low-light and foggy environments commonly encountered in UAV scenarios. The dataset and code will be publicly available at https://github.com/Jocelyney/GDNet.
Seek and Solve Reasoning for Table Question Answering
Sep 09, 2024Table-based Question Answering (TQA) involves answering questions based on tabular data. The complexity of table structures and question logic makes this task difficult even for Large Language Models (LLMs). This paper improves TQA performance by leveraging LLMs' reasoning capabilities. Inspired by how humans solve TQA tasks, we propose a Seek-and-Solve pipeline that instructs the LLM to first seek relevant information and then answer questions. The two stages are integrated at the reasoning level, and their Chain of Thought (CoT) paths are integrated into a coherent Seek-and-Solve CoT (SS-CoT). Furthermore, we present a compact single-stage TQA-solving prompt distilled from the pipeline. Experiments demonstrate that under In-Context Learning settings, using samples with SS-CoT paths as demonstrations, the TQA-solving prompt can effectively guide the LLM to solve complex TQA tasks, resulting in improved performance and reliability. Our results highlight the importance of properly eliciting LLMs' reasoning capabilities in solving complex TQA tasks.
Toward Wireless Localization Using Multiple Reconfigurable Intelligent Surfaces
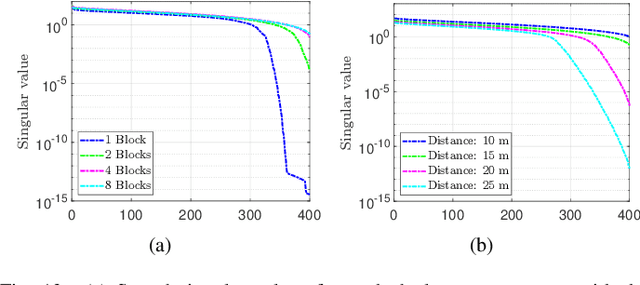
Jul 30, 2024This paper investigates the capabilities and effectiveness of backward sensing centered on reconfigurable intelligent surfaces (RISs). We demonstrate that the direction of arrival (DoA) estimation of incident waves in the far-field regime can be accomplished using a single RIS by leveraging configurational diversity. Furthermore, we identify that the spatial diversity achieved through deploying multiple RISs enables accurate localization of multiple power sources. Physically accurate and mathematically concise models are introduced to characterize forward signal aggregations via RISs. By employing linearized approximations inherent in the far-field region, the measurement process for various configurations can be expressed as a system of linear equations. The mathematical essence of backward sensing lies in solving this system. A theoretical framework for determining key performance indicators is established through condition number analysis of the sensing operators. In the context of localization using multiple RISs, we examine relationships among the rank of sensing operators, the size of the region of interest (RoI), and the number of elements and measurements. For DoA estimations, we provide an upper bound for the relative error of the least squares reconstruction algorithm. These quantitative analyses offer essential insights for system design and optimization. Numerical experiments validate our findings. To demonstrate the practicality of our proposed RIS-centric sensing approach, we develop a proof-of-concept prototype using universal software radio peripherals (USRP) and employ a magnitude-only reconstruction algorithm tailored for this system. To our knowledge, this represents the first trial of its kind.
Dreamer: Dual-RIS-aided Imager in Complementary Modes
Jul 20, 2024Reconfigurable intelligent surfaces (RISs) have emerged as a promising auxiliary technology for radio frequency imaging. However, existing works face challenges of faint and intricate back-scattered waves and the restricted field-of-view (FoV), both resulting from complex target structures and a limited number of antennas. The synergistic benefits of multi-RIS-aided imaging hold promise for addressing these challenges. Here, we propose a dual-RIS-aided imaging system, Dreamer, which operates collaboratively in complementary modes (reflection-mode and transmission-mode). Dreamer significantly expands the FoV and enhances perception by deploying dual-RIS across various spatial and measurement patterns. Specifically, we perform a fine-grained analysis of how radio-frequency (RF) signals encode scene information in the scattered object modeling. Based on this modeling, we design illumination strategies to balance spatial resolution and observation scale, and implement a prototype system in a typical indoor environment. Moreover, we design a novel artificial neural network with a CNN-external-attention mechanism to translate RF signals into high-resolution images of human contours. Our approach achieves an impressive SSIM score exceeding 0.83, validating its effectiveness in broadening perception modes and enhancing imaging capabilities. The code to reproduce our results is available at https://github.com/fuhaiwang/Dreamer.