 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-LLaVA: Causal Disentanglement for Mitigating Hallucination in Multimodal Large Language Models
May 26, 2025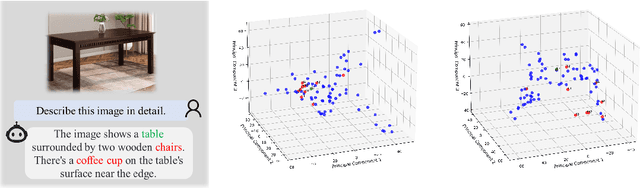
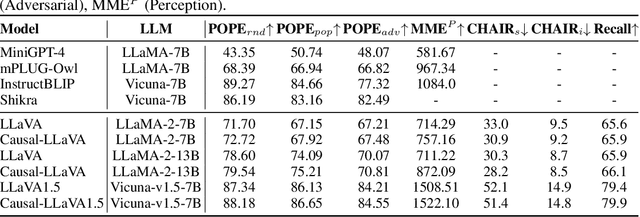
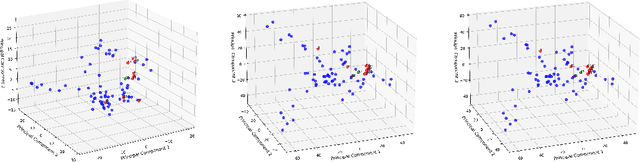
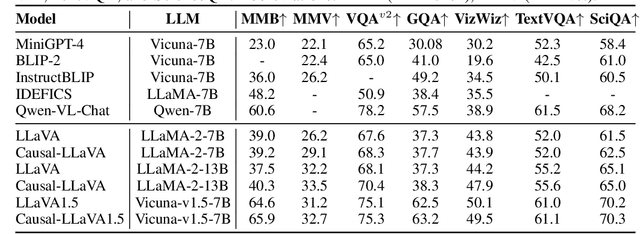
Multimodal Large Language Models (MLLMs) have demonstrated strong performance in visual understanding tasks, yet they often suffer from object hallucinations--generating descriptions of objects that are inconsistent with or entirely absent from the input. This issue is closely related to dataset biases, where frequent co-occurrences of objects lead to entangled semantic representations across modalities. As a result, models may erroneously activate object representations that are commonly associated with the input but not actually present. To address this, we propose a causality-driven disentanglement framework that mitigates hallucinations through causal intervention. Our approach includes a Causal-Driven Projector in the visual pathway and a Causal Intervention Module integrated into the final transformer layer of the language model. These components work together to reduce spurious correlations caused by biased training data. Experimental results show that our method significantly reduces hallucinations while maintaining strong performance on multiple multimodal benchmarks. Visualization analyses further confirm improved separability of object representations. The code is available at: https://github.com/IgniSavium/Causal-LLaVA
FocusedAD: Character-centric Movie Audio Description
Apr 16, 2025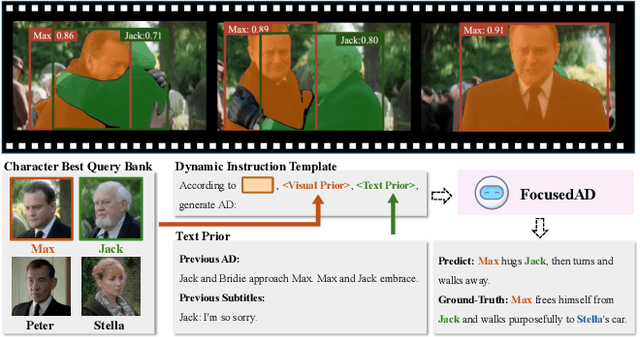
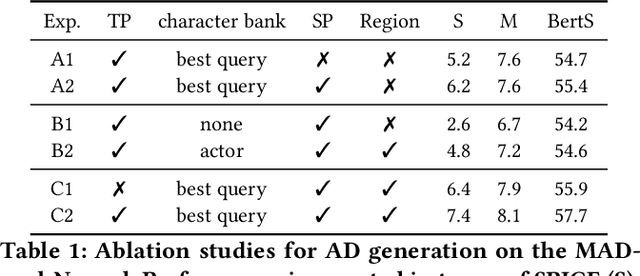
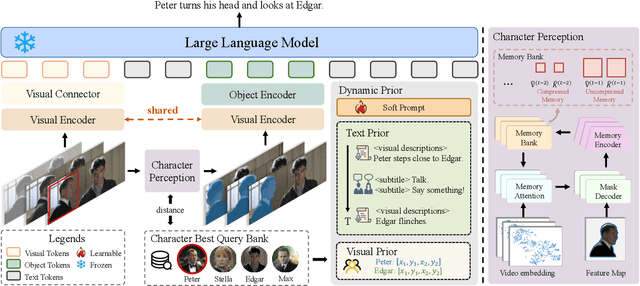
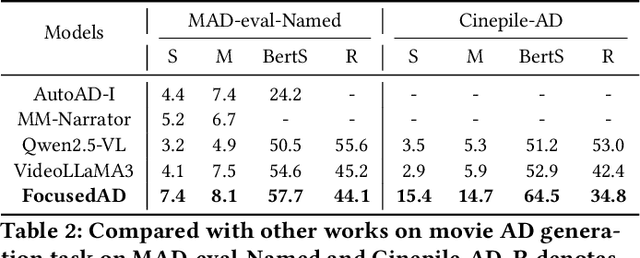
Movie Audio Description (AD) aims to narrate visual content during dialogue-free segments, particularly benefiting blind and visually impaired (BVI) audiences. Compared with general video captioning, AD demands plot-relevant narration with explicit character name references, posing unique challenges in movie understanding.To identify active main characters and focus on storyline-relevant regions, we propose FocusedAD, a novel framework that delivers character-centric movie audio descriptions. It includes: (i) a Character Perception Module(CPM) for tracking character regions and linking them to names; (ii) a Dynamic Prior Module(DPM) that injects contextual cues from prior ADs and subtitles via learnable soft prompts; and (iii) a Focused Caption Module(FCM) that generates narrations enriched with plot-relevant details and named characters. To overcome limitations in character identification, we also introduce an automated pipeline for building character query banks. FocusedAD achieves state-of-the-art performance on multiple benchmarks, including strong zero-shot results on MAD-eval-Named and our newly proposed Cinepile-AD dataset. Code and data will be released at https://github.com/Thorin215/FocusedAD .
ProcessPainter: Learn Painting Process from Sequence Data
Jun 10, 2024The painting process of artists is inherently stepwise and varies significantly among different painters and styles. Generating detailed, step-by-step painting processes is essential for art education and research, yet remains largely underexplored. Traditional stroke-based rendering methods break down images into sequences of brushstrokes, yet they fall short of replicating the authentic processes of artists, with limitations confined to basic brushstroke modifications. Text-to-image models utilizing diffusion processes generate images through iterative denoising, also diverge substantially from artists' painting process. To address these challenges, we introduce ProcessPainter, a text-to-video model that is initially pre-trained on synthetic data and subsequently fine-tuned with a select set of artists' painting sequences using the LoRA model. This approach successfully generates painting processes from text prompts for the first time. Furthermore, we introduce an Artwork Replication Network capable of accepting arbitrary-frame input, which facilitates the controlled generation of painting processes, decomposing images into painting sequences, and completing semi-finished artworks. This paper offers new perspectives and tools for advancing art education and image generation technology.
Idea-2-3D: Collaborative LMM Agents Enable 3D Model Generation from Interleaved Multimodal Inputs
Apr 05, 2024In this paper, we pursue a novel 3D AIGC setting: generating 3D content from IDEAs. The definition of an IDEA is the composition of multimodal inputs including text, image, and 3D models. To our knowledge, this challenging and appealing 3D AIGC setting has not been studied before. We propose the novel framework called Idea-2-3D to achieve this goal, which consists of three agents based upon large multimodel models (LMMs) and several existing algorithmic tools for them to invoke. Specifically, these three LMM-based agents are prompted to do the jobs of prompt generation, model selection and feedback reflection. They work in a cycle that involves both mutual collaboration and criticism. Note that this cycle is done in a fully automatic manner, without any human intervention. The framework then outputs a text prompt to generate 3D models that well align with input IDEAs. We show impressive 3D AIGC results that are beyond any previous methods can achieve. For quantitative comparisons, we construct caption-based baselines using a whole bunch of state-of-the-art 3D AIGC models and demonstrate Idea-2-3D out-performs significantly. In 94.2% of cases, Idea-2-3D meets users' requirements, marking a degree of match between IDEA and 3D models that is 2.3 times higher than baselines. Moreover, in 93.5% of the cases, users agreed that Idea-2-3D was better than baselines. Codes, data and models will made publicly available.
Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail
Mar 18, 20243D human body reconstruction has been a challenge in the field of computer vision. Previous methods are often time-consuming and difficult to capture the detailed appearance of the human body. In this paper, we propose a new method called \emph{Ultraman} for fast reconstruction of textured 3D human models from a single image. Compared to existing techniques, \emph{Ultraman} greatly improves the reconstruction speed and accuracy while preserving high-quality texture details. We present a set of new frameworks for human reconstruction consisting of three parts, geometric reconstruction, texture generation and texture mapping. Firstly, a mesh reconstruction framework is used, which accurately extracts 3D human shapes from a single image. At the same time, we propose a method to generate a multi-view consistent image of the human body based on a single image. This is finally combined with a novel texture mapping method to optimize texture details and ensure color consistency during reconstruction. Through extensive experiments and evaluations, we demonstrate the superior performance of \emph{Ultraman} on various standard datasets. In addition, \emph{Ultraman} outperforms state-of-the-art methods in terms of human rendering quality and speed. Upon acceptance of the article, we will make the code and data publicly available.
Network Embedding with Completely-imbalanced Labels
Jul 07, 2020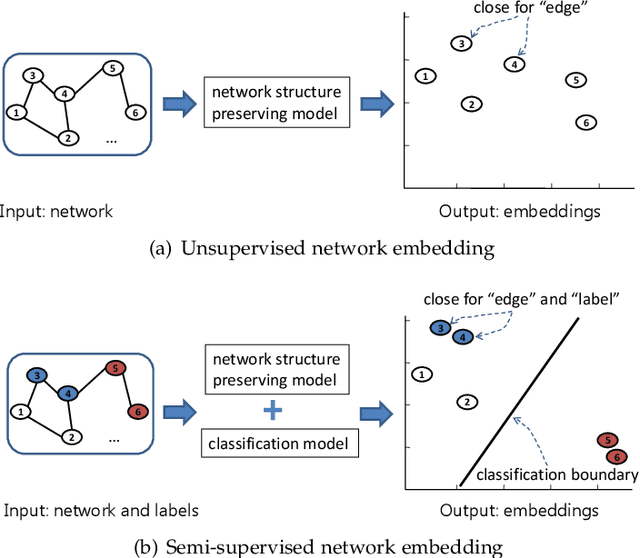
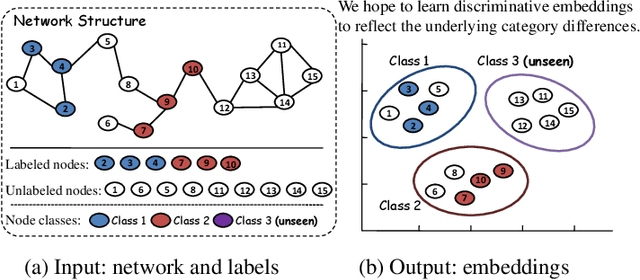


Network embedding, aiming to project a network into a low-dimensional space, is increasingly becoming a focus of network research. Semi-supervised network embedding takes advantage of labeled data, and has shown promising performance. However, existing semi-supervised methods would get unappealing results in the completely-imbalanced label setting where some classes have no labeled nodes at all. To alleviate this, we propose two novel semi-supervised network embedding methods. The first one is a shallow method named RSDNE. Specifically, to benefit from the completely-imbalanced labels, RSDNE guarantees both intra-class similarity and inter-class dissimilarity in an approximate way. The other method is RECT which is a new class of graph neural networks. Different from RSDNE, to benefit from the completely-imbalanced labels, RECT explores the class-semantic knowledge. This enables RECT to handle networks with node features and multi-label setting. Experimental results on several real-world datasets demonstrate the superiority of the proposed methods.
Zero-shot Feature Selection via Exploiting Semantic Knowledge
Aug 09, 2019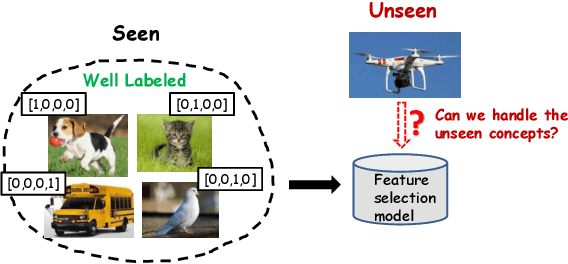
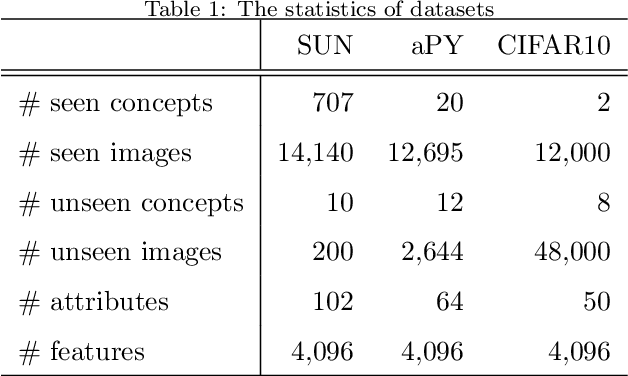
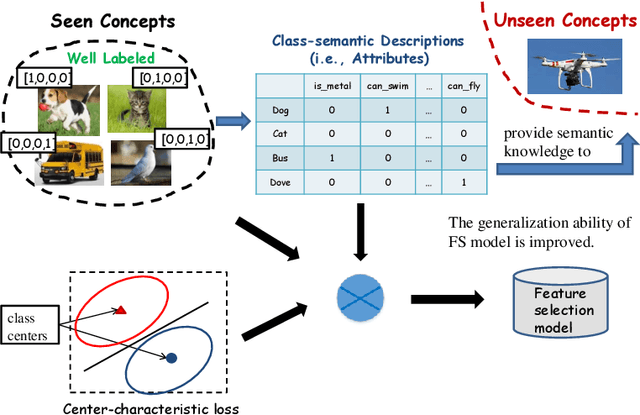
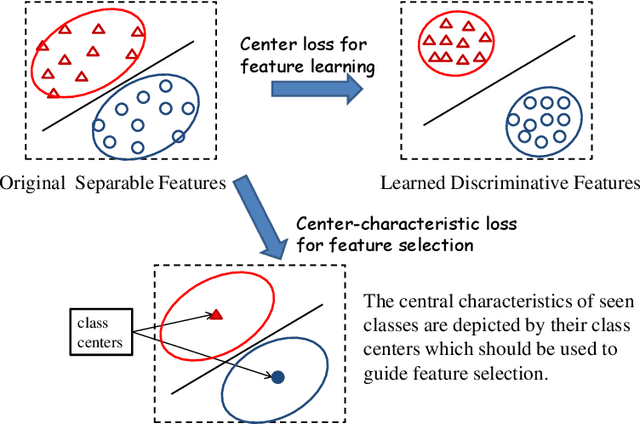
Feature selection plays an important role in pattern recognition and machine learning systems. Supervised knowledge can significantly improve the performance. However, confronted with the rapid growth of newly-emerging concepts, existing supervised methods may easily suffer from the scarcity of labeled data for training. Therefore, this paper studies the problem of Zero-Shot Feature Selection, i.e., building a feature selection model that generalizes well to "unseen" concepts with limited training data of "seen" concepts. To address this, inspired by zero-shot learning, we use class-semantic descriptions (i.e., attributes) which provide additional semantic information about unseen concepts as supervision. In addition, to seek for more reliable discriminative features, we further propose a novel loss function (named center-characteristic loss) which encourages the selected features to capture the central characteristics of seen concepts. Experimental results on three benchmarks demonstrate the superiority of the proposed method.
Equivalence between LINE and Matrix Factorization
Nov 08, 2017LINE [1], as an efficient network embedding method, has shown its effectiveness in dealing with large-scale undirected, directed, and/or weighted networks. Particularly, it proposes to preserve both the local structure (represented by First-order Proximity) and global structure (represented by Second-order Proximity) of the network. In this study, we prove that LINE with these two proximities (LINE(1st) and LINE(2nd)) are actually factoring two different matrices separately. Specifically, LINE(1st) is factoring a matrix M (1), whose entries are the doubled Pointwise Mutual Information (PMI) of vertex pairs in undirected networks, shifted by a constant. LINE(2nd) is factoring a matrix M (2), whose entries are the PMI of vertex and context pairs in directed networks, shifted by a constant. We hope this finding would provide a basis for further extensions and generalizations of LINE.