 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyMem: Hybrid Memory Architecture with Dynamic Retrieval Scheduling
Feb 15, 2026Large language model (LLM) agents demonstrate strong performance in short-text contexts but often underperform in extended dialogues due to inefficient memory management. Existing approaches face a fundamental trade-off between efficiency and effectiveness: memory compression risks losing critical details required for complex reasoning, while retaining raw text introduces unnecessary computational overhead for simple queries. The crux lies in the limitations of monolithic memory representations and static retrieval mechanisms, which fail to emulate the flexible and proactive memory scheduling capabilities observed in humans, thus struggling to adapt to diverse problem scenarios. Inspired by the principle of cognitive economy, we propose HyMem, a hybrid memory architecture that enables dynamic on-demand scheduling through multi-granular memory representations. HyMem adopts a dual-granular storage scheme paired with a dynamic two-tier retrieval system: a lightweight module constructs summary-level context for efficient response generation, while an LLM-based deep module is selectively activated only for complex queries, augmented by a reflection mechanism for iterative reasoning refinement. Experiments show that HyMem achieves strong performance on both the LOCOMO and LongMemEval benchmarks, outperforming full-context while reducing computational cost by 92.6\%, establishing a state-of-the-art balance between efficiency and performance in long-term memory management.
Urban Neural Surface Reconstruction from Constrained Sparse Aerial Imagery with 3D SAR Fusion
Jan 29, 2026Neural surface reconstruction (NSR) has recently shown strong potential for urban 3D reconstruction from multi-view aerial imagery. However, existing NSR methods often suffer from geometric ambiguity and instability, particularly under sparse-view conditions. This issue is critical in large-scale urban remote sensing, where aerial image acquisition is limited by flight paths, terrain, and cost. To address this challenge, we present the first urban NSR framework that fuses 3D synthetic aperture radar (SAR) point clouds with aerial imagery for high-fidelity reconstruction under constrained, sparse-view settings. 3D SAR can efficiently capture large-scale geometry even from a single side-looking flight path, providing robust priors that complement photometric cues from images. Our framework integrates radar-derived spatial constraints into an SDF-based NSR backbone, guiding structure-aware ray selection and adaptive sampling for stable and efficient optimization. We also construct the first benchmark dataset with co-registered 3D SAR point clouds and aerial imagery, facilitating systematic evaluation of cross-modal 3D reconstruction. Extensive experiments show that incorporating 3D SAR markedly enhances reconstruction accuracy, completeness, and robustness compared with single-modality baselines under highly sparse and oblique-view conditions, highlighting a viable route toward scalable high-fidelity urban reconstruction with advanced airborne and spaceborne optical-SAR sensing.
Comparison Research of Millimeter-Wave/Infrared Co-aperture Reflector Antenna Systems Based on a Specialized Film
Apr 27, 2025This paper presents a novel co-aperture reflector antenna operating in millimeter-wave (MMW) and infrared (IR) for cloud detection radar. The proposed design combines a back-fed dual-reflector antenna, an IR optical reflection system, and a specialize thin film with IR-reflective/MMW-transmissive properties. Simulations demonstrate a gain exceeding 50 dBi within 94 GHz plush or minus 500 MHz bandwidth, with 0.46{\deg} beamwidth in both azimuth (E-plane) and elevation (H-plane) and sidelobe levels below -25 dB. This co-aperture architecture addresses the limitations of standalone MMW and IR radars, enabling high-resolution cloud microphysical parameter retrieval while minimizing system footprint. The design lays a foundation for airborne/spaceborne multi-mode detection systems.
ProcessPainter: Learn Painting Process from Sequence Data
Jun 10, 2024



The painting process of artists is inherently stepwise and varies significantly among different painters and styles. Generating detailed, step-by-step painting processes is essential for art education and research, yet remains largely underexplored. Traditional stroke-based rendering methods break down images into sequences of brushstrokes, yet they fall short of replicating the authentic processes of artists, with limitations confined to basic brushstroke modifications. Text-to-image models utilizing diffusion processes generate images through iterative denoising, also diverge substantially from artists' painting process. To address these challenges, we introduce ProcessPainter, a text-to-video model that is initially pre-trained on synthetic data and subsequently fine-tuned with a select set of artists' painting sequences using the LoRA model. This approach successfully generates painting processes from text prompts for the first time. Furthermore, we introduce an Artwork Replication Network capable of accepting arbitrary-frame input, which facilitates the controlled generation of painting processes, decomposing images into painting sequences, and completing semi-finished artworks. This paper offers new perspectives and tools for advancing art education and image generation technology.
Are We Ready for Planetary Exploration Robots? The TAIL-Plus Dataset for SLAM in Granular Environments
Apr 21, 2024So far, planetary surface exploration depends on various mobile robot platforms. The autonomous navigation and decision-making of these mobile robots in complex terrains largely rely on their terrain-aware perception, localization and mapping capabilities. In this paper we release the TAIL-Plus dataset, a new challenging dataset in deformable granular environments for planetary exploration robots, which is an extension to our previous work, TAIL (Terrain-Aware multI-modaL) dataset. We conducted field experiments on beaches that are considered as planetary surface analog environments for diverse sandy terrains. In TAIL-Plus dataset, we provide more sequences with multiple loops and expand the scene from day to night. Benefit from our sensor suite with modular design, we use both wheeled and quadruped robots for data collection. The sensors include a 3D LiDAR, three downward RGB-D cameras, a pair of global-shutter color cameras that can be used as a forward-looking stereo camera, an RTK-GPS device and an extra IMU. Our datasets are intended to help researchers developing multi-sensor simultaneous localization and mapping (SLAM) algorithms for robots in unstructured, deformable granular terrains. Our datasets and supplementary materials will be available at \url{https://tailrobot.github.io/}.
TAIL: A Terrain-Aware Multi-Modal SLAM Dataset for Robot Locomotion in Deformable Granular Environments
Mar 25, 2024Terrain-aware perception holds the potential to improve the robustness and accuracy of autonomous robot navigation in the wilds, thereby facilitating effective off-road traversals. However, the lack of multi-modal perception across various motion patterns hinders the solutions of Simultaneous Localization And Mapping (SLAM), especially when confronting non-geometric hazards in demanding landscapes. In this paper, we first propose a Terrain-Aware multI-modaL (TAIL) dataset tailored to deformable and sandy terrains. It incorporates various types of robotic proprioception and distinct ground interactions for the unique challenges and benchmark of multi-sensor fusion SLAM. The versatile sensor suite comprises stereo frame cameras, multiple ground-pointing RGB-D cameras, a rotating 3D LiDAR, an IMU, and an RTK device. This ensemble is hardware-synchronized, well-calibrated, and self-contained. Utilizing both wheeled and quadrupedal locomotion, we efficiently collect comprehensive sequences to capture rich unstructured scenarios. It spans the spectrum of scope, terrain interactions, scene changes, ground-level properties, and dynamic robot characteristics. We benchmark several state-of-the-art SLAM methods against ground truth and provide performance validations. Corresponding challenges and limitations are also reported. All associated resources are accessible upon request at \url{https://tailrobot.github.io/}.
Predict the Rover Mobility over Soft Terrain using Articulated Wheeled Bevameter
Feb 17, 2022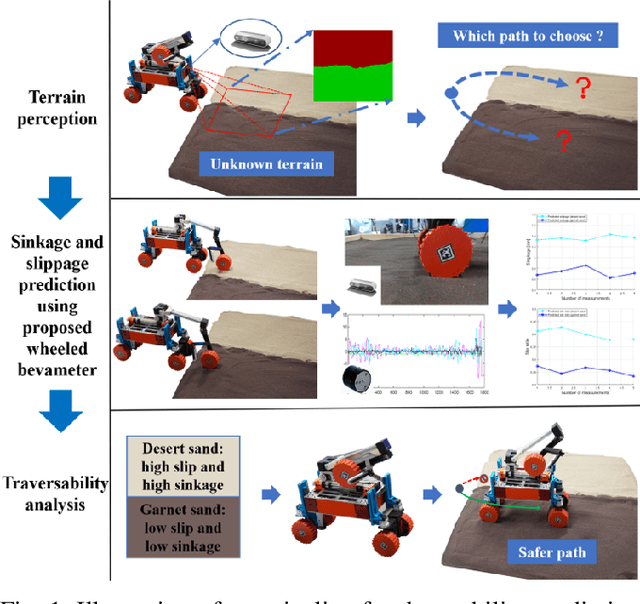
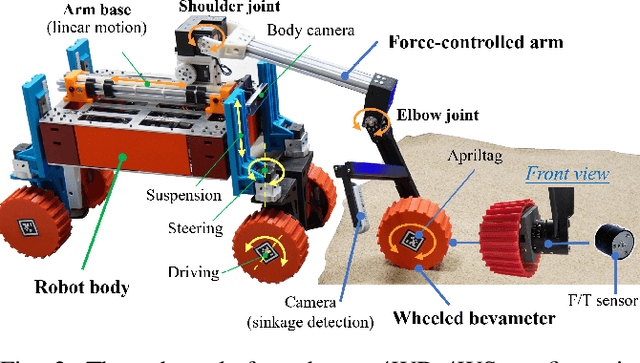
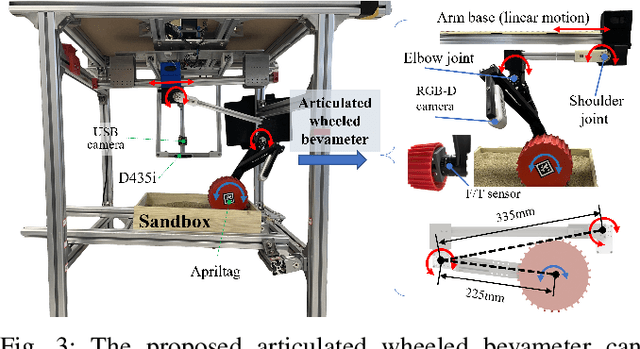

Robot mobility is critical for mission success, especially in soft or deformable terrains, where the complex wheel-soil interaction mechanics often leads to excessive wheel slip and sinkage, causing the eventual mission failure. To improve the success rate, online mobility prediction using vision, infrared imaging, or model-based stochastic methods have been used in the literature. This paper proposes an on-board mobility prediction approach using an articulated wheeled bevameter that consists of a force-controlled arm and an instrumented bevameter (with force and vision sensors) as its end-effector. The proposed bevameter, which emulates the traditional terramechanics tests such as pressure-sinkage and shear experiments, can measure contact parameters ahead of the rover's body in real-time, and predict the slip and sinkage of supporting wheels over the probed region. Based on the predicted mobility, the rover can select a safer path in order to avoid dangerous regions such as those covered with quicksand. Compared to the literature, our proposed method can avoid the complicated terramechanics modeling and time-consuming stochastic prediction; it can also mitigate the inaccuracy issues arising in non-contact vision-based methods. We also conduct multiple experiments to validate the proposed approach.
Machine Learning Applications on Neuroimaging for Diagnosis and Prognosis of Epilepsy: A Review
Feb 05, 2021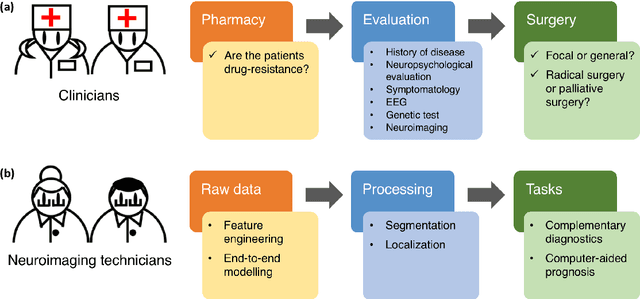

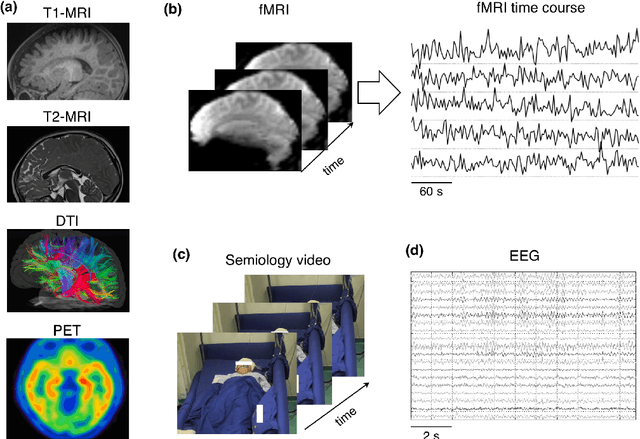
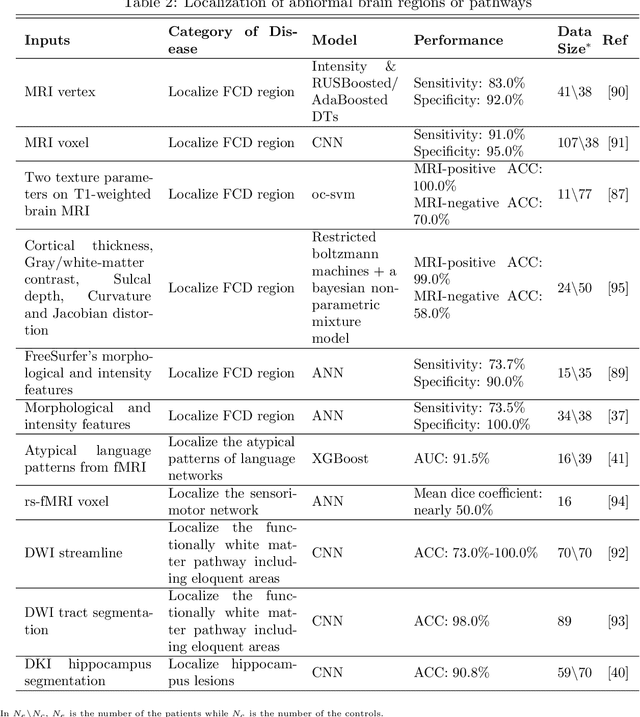
Machine learning is playing an increasing important role in medical image analysis, spawning new advances in neuroimaging clinical applications. However, previous work and reviews were mainly focused on the electrophysiological signals like EEG or SEEG; the potential of neuroimaging in epilepsy research has been largely overlooked despite of its wide use in clinical practices. In this review, we highlight the interactions between neuroimaging and machine learning in the context of the epilepsy diagnosis and prognosis. We firstly outline typical neuroimaging modalities used in epilepsy clinics, \textit{e.g} MRI, DTI, fMRI and PET. We then introduce two approaches to apply machine learning methods to neuroimaging data: the two-step compositional approach which combines feature engineering and machine learning classifier, and the end-to-end approach which is usually toward deep learning. Later a detailed review on the machine learning tasks on epileptic images is presented, such as segmentation, localization and lateralization tasks, as well as the tasks directly related to the diagnosis and prognosis. In the end, we discuss current achievements, challenges, potential future directions in the field, with the hope to pave a way to computer-aided diagnosis and prognosis of epilepsy.
Multi-Sensor State Estimation Fusion on Quadruped Robot Locomotion
Jul 06, 2020

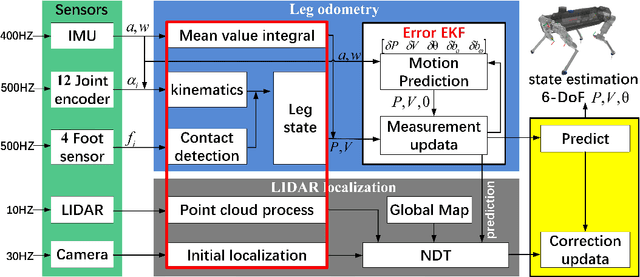
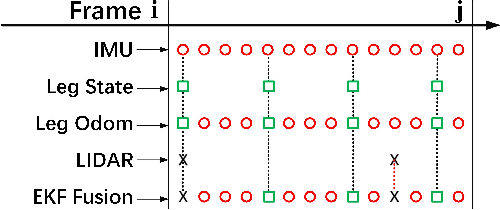
In this paper, we present a effective state estimation algorithm that combined with various sensors information (Inertial measurement unit, joints encoder, camera and LIDAR) to enable balance the different frequency and accuracy for the locomotion of our quadruped robot StarDog. Of specific interest is the approach to preprocess a series of sensors measurement which can obtain robust data information, as well as improve the system performance in terms of time and accuracy. In the IMU-centric leg odometry which fuse the inertial and kinematic data, the detection of foot contact state and lateral slip are considered to further import the accuracy of robot's base-link posiiton and velocity. Before use the NDT registration to align the point clouds, we need to feed the requirement by preprocessing these data and obtaining initial localization in map. Also a modular filtering is proposed which can fuse leg odometry based on the inertial-kinematics state estimator of the quadruped robot and LIDAR-based localization method. This algorithm has been tested from the experimental data at indoor building and the motion capture system is used to evaluate the performance, the experimental results can demonstrate the feasibility of low error and high frequency for our quadruped robot system.