 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISE-Flow: Workflow-Induced Structured Experience for Self-Evolving Conversational Service Agents
Jan 13, 2026Large language model (LLM)-based agents are widely deployed in user-facing services but remain error-prone in new tasks, tend to repeat the same failure patterns, and show substantial run-to-run variability. Fixing failures via environment-specific training or manual patching is costly and hard to scale. To enable self-evolving agents in user-facing service environments, we propose WISE-Flow, a workflow-centric framework that converts historical service interactions into reusable procedural experience by inducing workflows with prerequisite-augmented action blocks. At deployment, WISE-Flow aligns the agent's execution trajectory to retrieved workflows and performs prerequisite-aware feasibility reasoning to achieve state-grounded next actions. Experiments on ToolSandbox and $τ^2$-bench show consistent improvement across base models.
High-Quality Spatial Reconstruction and Orthoimage Generation Using Efficient 2D Gaussian Splatting
Mar 25, 2025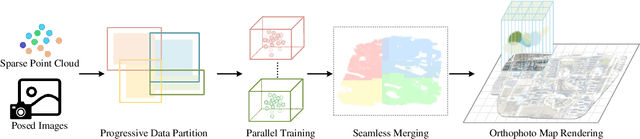
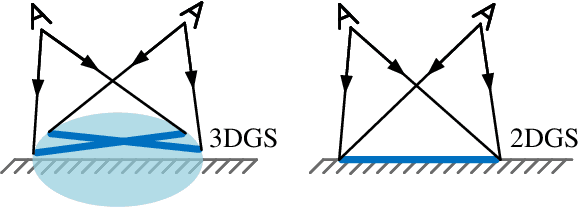
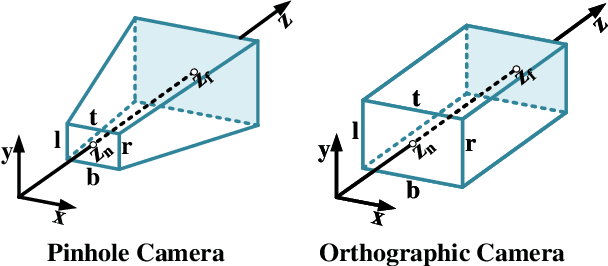
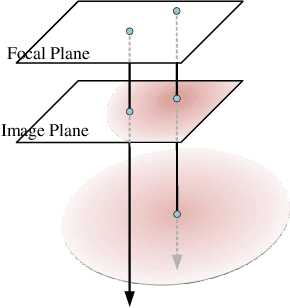
Highly accurate geometric precision and dense image features characterize True Digital Orthophoto Maps (TDOMs), which are in great demand for applications such as urban planning, infrastructure management, and environmental monitoring. Traditional TDOM generation methods need sophisticated processes, such as Digital Surface Models (DSM) and occlusion detection, which are computationally expensive and prone to errors. This work presents an alternative technique rooted in 2D Gaussian Splatting (2DGS), free of explicit DSM and occlusion detection. With depth map generation, spatial information for every pixel within the TDOM is retrieved and can reconstruct the scene with high precision. Divide-and-conquer strategy achieves excellent GS training and rendering with high-resolution TDOMs at a lower resource cost, which preserves higher quality of rendering on complex terrain and thin structure without a decrease in efficiency. Experimental results demonstrate the efficiency of large-scale scene reconstruction and high-precision terrain modeling. This approach provides accurate spatial data, which assists users in better planning and decision-making based on maps.
A Multi-Sensor Fusion Approach for Rapid Orthoimage Generation in Large-Scale UAV Mapping
Mar 05, 2025Rapid generation of large-scale orthoimages from Unmanned Aerial Vehicles (UAVs) has been a long-standing focus of research in the field of aerial mapping. A multi-sensor UAV system, integrating the Global Positioning System (GPS), Inertial Measurement Unit (IMU), 4D millimeter-wave radar and camera, can provide an effective solution to this problem. In this paper, we utilize multi-sensor data to overcome the limitations of conventional orthoimage generation methods in terms of temporal performance, system robustness, and geographic reference accuracy. A prior-pose-optimized feature matching method is introduced to enhance matching speed and accuracy, reducing the number of required features and providing precise references for the Structure from Motion (SfM) process. The proposed method exhibits robustness in low-texture scenes like farmlands, where feature matching is difficult. Experiments show that our approach achieves accurate feature matching orthoimage generation in a short time. The proposed drone system effectively aids in farmland detection and management.
Real-time volumetric free-hand ultrasound imaging for large-sized organs: A study of imaging the whole spine
Nov 25, 2024Three-dimensional (3D) ultrasound imaging can overcome the limitations of conventional two dimensional (2D) ultrasound imaging in structural observation and measurement. However, conducting volumetric ultrasound imaging for large-sized organs still faces difficulties including long acquisition time, inevitable patient movement, and 3D feature recognition. In this study, we proposed a real-time volumetric free-hand ultrasound imaging system optimized for the above issues and applied it to the clinical diagnosis of scoliosis. This study employed an incremental imaging method coupled with algorithmic acceleration to enable real-time processing and visualization of the large amounts of data generated when scanning large-sized organs. Furthermore, to deal with the difficulty of image feature recognition, we proposed two tissue segmentation algorithms to reconstruct and visualize the spinal anatomy in 3D space by approximating the depth at which the bone structures are located and segmenting the ultrasound images at different depths. We validated the adaptability of our system by deploying it to multiple models of ultra-sound equipment and conducting experiments using different types of ultrasound probes. We also conducted experiments on 6 scoliosis patients and 10 normal volunteers to evaluate the performance of our proposed method. Ultrasound imaging of a volunteer spine from shoulder to crotch (more than 500 mm) was performed in 2 minutes, and the 3D imaging results displayed in real-time were compared with the corresponding X-ray images with a correlation coefficient of 0.96 in spinal curvature. Our proposed volumetric ultrasound imaging system might hold the potential to be clinically applied to other large-sized organs.
Efficient Camera Exposure Control for Visual Odometry via Deep Reinforcement Learning
Aug 30, 2024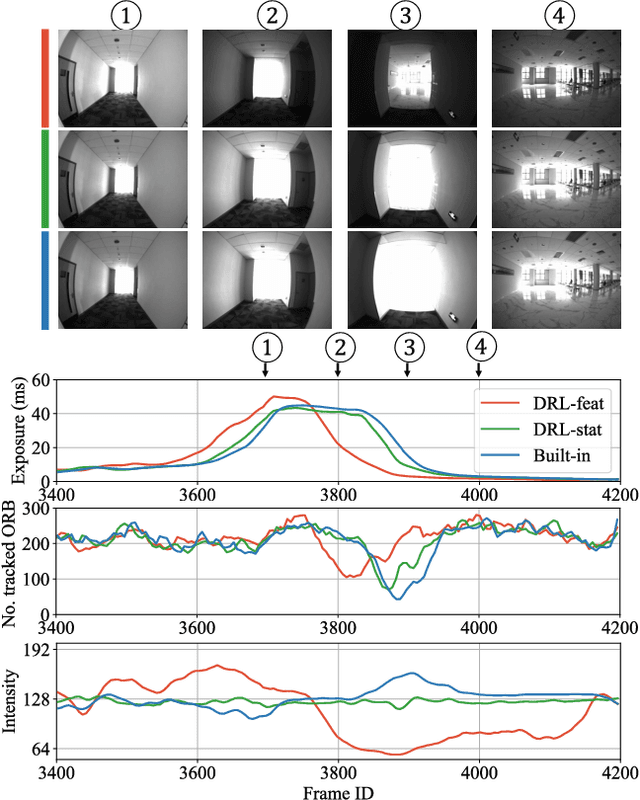
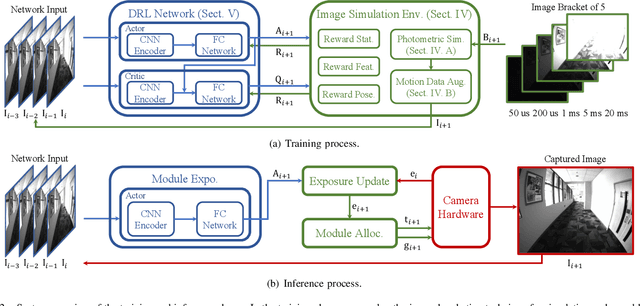
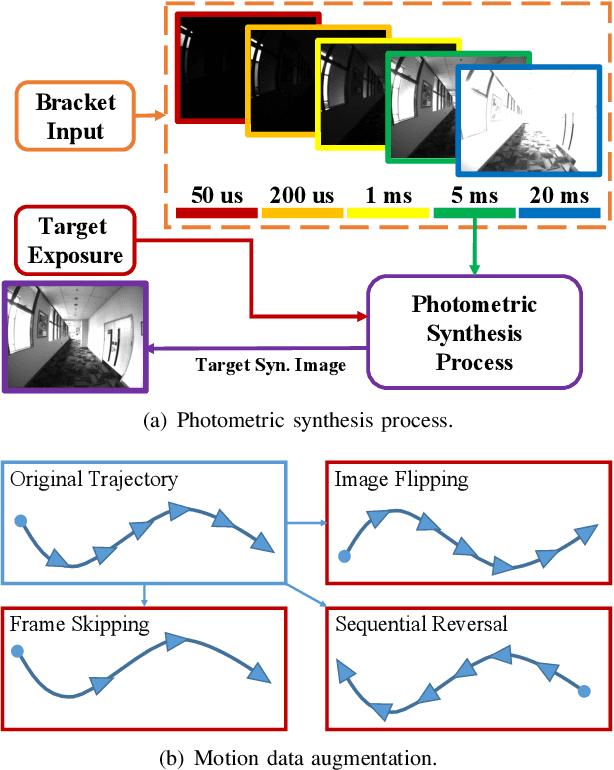

The stability of visual odometry (VO) systems is undermined by degraded image quality, especially in environments with significant illumination changes. This study employs a deep reinforcement learning (DRL) framework to train agents for exposure control, aiming to enhance imaging performance in challenging conditions. A lightweight image simulator is developed to facilitate the training process, enabling the diversification of image exposure and sequence trajectory. This setup enables completely offline training, eliminating the need for direct interaction with camera hardware and the real environments. Different levels of reward functions are crafted to enhance the VO systems, equipping the DRL agents with varying intelligence. Extensive experiments have shown that our exposure control agents achieve superior efficiency-with an average inference duration of 1.58 ms per frame on a CPU-and respond more quickly than traditional feedback control schemes. By choosing an appropriate reward function, agents acquire an intelligent understanding of motion trends and anticipate future illumination changes. This predictive capability allows VO systems to deliver more stable and precise odometry results. The codes and datasets are available at https://github.com/ShuyangUni/drl_exposure_ctrl.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
Resolve Domain Conflicts for Generalizable Remote Physiological Measurement
Apr 11, 2024



Remote photoplethysmography (rPPG) technology has become increasingly popular due to its non-invasive monitoring of various physiological indicators, making it widely applicable in multimedia interaction, healthcare, and emotion analysis. Existing rPPG methods utilize multiple datasets for training to enhance the generalizability of models. However, they often overlook the underlying conflict issues across different datasets, such as (1) label conflict resulting from different phase delays between physiological signal labels and face videos at the instance level, and (2) attribute conflict stemming from distribution shifts caused by head movements, illumination changes, skin types, etc. To address this, we introduce the DOmain-HArmonious framework (DOHA). Specifically, we first propose a harmonious phase strategy to eliminate uncertain phase delays and preserve the temporal variation of physiological signals. Next, we design a harmonious hyperplane optimization that reduces irrelevant attribute shifts and encourages the model's optimization towards a global solution that fits more valid scenarios. Our experiments demonstrate that DOHA significantly improves the performance of existing methods under multiple protocols. Our code is available at https://github.com/SWY666/rPPG-DOHA.
Self-similarity Prior Distillation for Unsupervised Remote Physiological Measurement
Nov 09, 2023Remote photoplethysmography (rPPG) is a noninvasive technique that aims to capture subtle variations in facial pixels caused by changes in blood volume resulting from cardiac activities. Most existing unsupervised methods for rPPG tasks focus on the contrastive learning between samples while neglecting the inherent self-similar prior in physiological signals. In this paper, we propose a Self-Similarity Prior Distillation (SSPD) framework for unsupervised rPPG estimation, which capitalizes on the intrinsic self-similarity of cardiac activities. Specifically, we first introduce a physical-prior embedded augmentation technique to mitigate the effect of various types of noise. Then, we tailor a self-similarity-aware network to extract more reliable self-similar physiological features. Finally, we develop a hierarchical self-distillation paradigm to assist the network in disentangling self-similar physiological patterns from facial videos. Comprehensive experiments demonstrate that the unsupervised SSPD framework achieves comparable or even superior performance compared to the state-of-the-art supervised methods. Meanwhile, SSPD maintains the lowest inference time and computation cost among end-to-end models. The source codes are available at https://github.com/LinXi1C/SSPD.
DACOM: Learning Delay-Aware Communication for Multi-Agent Reinforcement Learning
Dec 03, 2022Communication is supposed to improve multi-agent collaboration and overall performance in cooperative Multi-agent reinforcement learning (MARL). However, such improvements are prevalently limited in practice since most existing communication schemes ignore communication overheads (e.g., communication delays). In this paper, we demonstrate that ignoring communication delays has detrimental effects on collaborations, especially in delay-sensitive tasks such as autonomous driving. To mitigate this impact, we design a delay-aware multi-agent communication model (DACOM) to adapt communication to delays. Specifically, DACOM introduces a component, TimeNet, that is responsible for adjusting the waiting time of an agent to receive messages from other agents such that the uncertainty associated with delay can be addressed. Our experiments reveal that DACOM has a non-negligible performance improvement over other mechanisms by making a better trade-off between the benefits of communication and the costs of waiting for messages.
Bone marrow sparing for cervical cancer radiotherapy on multimodality medical images
Apr 20, 2022
Cervical cancer threatens the health of women seriously. Radiotherapy is one of the main therapy methods but with high risk of acute hematologic toxicity. Delineating the bone marrow (BM) for sparing using computer tomography (CT) images to plan before radiotherapy can effectively avoid this risk. Comparing with magnetic resonance (MR) images, CT lacks the ability to express the activity of BM. Thus, in current clinical practice, medical practitioners manually delineate the BM on CT images by corresponding to MR images. However, the time?consuming delineating BM by hand cannot guarantee the accuracy due to the inconsistency of the CT-MR multimodal images. In this study, we propose a multimodal image oriented automatic registration method for pelvic BM sparing, which consists of three-dimensional bone point cloud reconstruction, a local spherical system iteration closest point registration for marking BM on CT images. Experiments on patient dataset reveal that our proposed method can enhance the multimodal image registration accuracy and efficiency for medical practitioners in sparing BM of cervical cancer radiotherapy. The method proposed in this contribution might also provide references for similar studies in other clinical application.