 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDU-CIRCUIT-HW: Evaluating Multimodal Large Language Models on Real-World University-Level STEM Student Handwritten Solutions
Jan 23, 2026Multimodal Large Language Models (MLLMs) hold significant promise for revolutionizing traditional education and reducing teachers' workload. However, accurately interpreting unconstrained STEM student handwritten solutions with intertwined mathematical formulas, diagrams, and textual reasoning poses a significant challenge due to the lack of authentic and domain-specific benchmarks. Additionally, current evaluation paradigms predominantly rely on the outcomes of downstream tasks (e.g., auto-grading), which often probe only a subset of the recognized content, thereby failing to capture the MLLMs' understanding of complex handwritten logic as a whole. To bridge this gap, we release EDU-CIRCUIT-HW, a dataset consisting of 1,300+ authentic student handwritten solutions from a university-level STEM course. Utilizing the expert-verified verbatim transcriptions and grading reports of student solutions, we simultaneously evaluate various MLLMs' upstream recognition fidelity and downstream auto-grading performance. Our evaluation uncovers an astonishing scale of latent failures within MLLM-recognized student handwritten content, highlighting the models' insufficient reliability for auto-grading and other understanding-oriented applications in high-stakes educational settings. In solution, we present a case study demonstrating that leveraging identified error patterns to preemptively detect and rectify recognition errors, with only minimal human intervention (approximately 4% of the total solutions), can significantly enhance the robustness of the deployed AI-enabled grading system on unseen student solutions.
Enhancing Large Language Models for End-to-End Circuit Analysis Problem Solving
Dec 10, 2025Large language models (LLMs) have shown strong performance in data-rich domains such as programming, but their reliability in engineering tasks remains limited. Circuit analysis -- requiring multimodal understanding and precise mathematical reasoning -- highlights these challenges. Although Gemini 2.5 Pro improves diagram interpretation and analog-circuit reasoning, it still struggles to consistently produce correct solutions when given both text and circuit diagrams. At the same time, engineering education needs scalable AI tools capable of generating accurate solutions for tasks such as automated homework feedback and question-answering. This paper presents an enhanced, end-to-end circuit problem solver built on Gemini 2.5 Pro. We first benchmark Gemini on a representative set of undergraduate circuit problems and identify two major failure modes: 1) circuit-recognition hallucinations, particularly incorrect source polarity detection, and 2) reasoning-process hallucinations, such as incorrect current directions. To address recognition errors, we integrate a fine-tuned YOLO detector and OpenCV processing to isolate voltage and current sources, enabling Gemini to re-identify source polarities from cropped images with near-perfect accuracy. To reduce reasoning errors, we introduce an ngspice-based verification loop in which Gemini generates a .cir file, ngspice simulates the circuit, and discrepancies trigger iterative regeneration with optional human-in-the-loop review. Across 83 problems, the proposed pipeline achieves a 97.59% success rate (81 correct solutions), substantially outperforming Gemini 2.5 Pro's original 79.52% accuracy. This system extends LLM capabilities for multimodal engineering problem-solving and supports the creation of high-quality educational datasets and AI-powered instructional tools.
BEEAR: Embedding-based Adversarial Removal of Safety Backdoors in Instruction-tuned Language Models
Jun 24, 2024Safety backdoor attacks in large language models (LLMs) enable the stealthy triggering of unsafe behaviors while evading detection during normal interactions. The high dimensionality of potential triggers in the token space and the diverse range of malicious behaviors make this a critical challenge. We present BEEAR, a mitigation approach leveraging the insight that backdoor triggers induce relatively uniform drifts in the model's embedding space. Our bi-level optimization method identifies universal embedding perturbations that elicit unwanted behaviors and adjusts the model parameters to reinforce safe behaviors against these perturbations. Experiments show BEEAR reduces the success rate of RLHF time backdoor attacks from >95% to <1% and from 47% to 0% for instruction-tuning time backdoors targeting malicious code generation, without compromising model utility. Requiring only defender-defined safe and unwanted behaviors, BEEAR represents a step towards practical defenses against safety backdoors in LLMs, providing a foundation for further advancements in AI safety and security.
Boosting Single Positive Multi-label Classification with Generalized Robust Loss
May 06, 2024



Multi-label learning (MLL) requires comprehensive multi-semantic annotations that is hard to fully obtain, thus often resulting in missing labels scenarios. In this paper, we investigate Single Positive Multi-label Learning (SPML), where each image is associated with merely one positive label. Existing SPML methods only focus on designing losses using mechanisms such as hard pseudo-labeling and robust losses, mostly leading to unacceptable false negatives. To address this issue, we first propose a generalized loss framework based on expected risk minimization to provide soft pseudo labels, and point out that the former losses can be seamlessly converted into our framework. In particular, we design a novel robust loss based on our framework, which enjoys flexible coordination between false positives and false negatives, and can additionally deal with the imbalance between positive and negative samples. Extensive experiments show that our approach can significantly improve SPML performance and outperform the vast majority of state-of-the-art methods on all the four benchmarks.
Resolve Domain Conflicts for Generalizable Remote Physiological Measurement
Apr 11, 2024



Remote photoplethysmography (rPPG) technology has become increasingly popular due to its non-invasive monitoring of various physiological indicators, making it widely applicable in multimedia interaction, healthcare, and emotion analysis. Existing rPPG methods utilize multiple datasets for training to enhance the generalizability of models. However, they often overlook the underlying conflict issues across different datasets, such as (1) label conflict resulting from different phase delays between physiological signal labels and face videos at the instance level, and (2) attribute conflict stemming from distribution shifts caused by head movements, illumination changes, skin types, etc. To address this, we introduce the DOmain-HArmonious framework (DOHA). Specifically, we first propose a harmonious phase strategy to eliminate uncertain phase delays and preserve the temporal variation of physiological signals. Next, we design a harmonious hyperplane optimization that reduces irrelevant attribute shifts and encourages the model's optimization towards a global solution that fits more valid scenarios. Our experiments demonstrate that DOHA significantly improves the performance of existing methods under multiple protocols. Our code is available at https://github.com/SWY666/rPPG-DOHA.
Self-similarity Prior Distillation for Unsupervised Remote Physiological Measurement
Nov 09, 2023Remote photoplethysmography (rPPG) is a noninvasive technique that aims to capture subtle variations in facial pixels caused by changes in blood volume resulting from cardiac activities. Most existing unsupervised methods for rPPG tasks focus on the contrastive learning between samples while neglecting the inherent self-similar prior in physiological signals. In this paper, we propose a Self-Similarity Prior Distillation (SSPD) framework for unsupervised rPPG estimation, which capitalizes on the intrinsic self-similarity of cardiac activities. Specifically, we first introduce a physical-prior embedded augmentation technique to mitigate the effect of various types of noise. Then, we tailor a self-similarity-aware network to extract more reliable self-similar physiological features. Finally, we develop a hierarchical self-distillation paradigm to assist the network in disentangling self-similar physiological patterns from facial videos. Comprehensive experiments demonstrate that the unsupervised SSPD framework achieves comparable or even superior performance compared to the state-of-the-art supervised methods. Meanwhile, SSPD maintains the lowest inference time and computation cost among end-to-end models. The source codes are available at https://github.com/LinXi1C/SSPD.
Tackling the Non-IID Issue in Heterogeneous Federated Learning by Gradient Harmonization
Sep 13, 2023Federated learning (FL) is a privacy-preserving paradigm for collaboratively training a global model from decentralized clients. However, the performance of FL is hindered by non-independent and identically distributed (non-IID) data and device heterogeneity. In this work, we revisit this key challenge through the lens of gradient conflicts on the server side. Specifically, we first investigate the gradient conflict phenomenon among multiple clients and reveal that stronger heterogeneity leads to more severe gradient conflicts. To tackle this issue, we propose FedGH, a simple yet effective method that mitigates local drifts through Gradient Harmonization. This technique projects one gradient vector onto the orthogonal plane of the other within conflicting client pairs. Extensive experiments demonstrate that FedGH consistently enhances multiple state-of-the-art FL baselines across diverse benchmarks and non-IID scenarios. Notably, FedGH yields more significant improvements in scenarios with stronger heterogeneity. As a plug-and-play module, FedGH can be seamlessly integrated into any FL framework without requiring hyperparameter tuning.
WPPG Net: A Non-contact Video Based Heart Rate Extraction Network Framework with Compatible Training Capability
Jul 04, 2022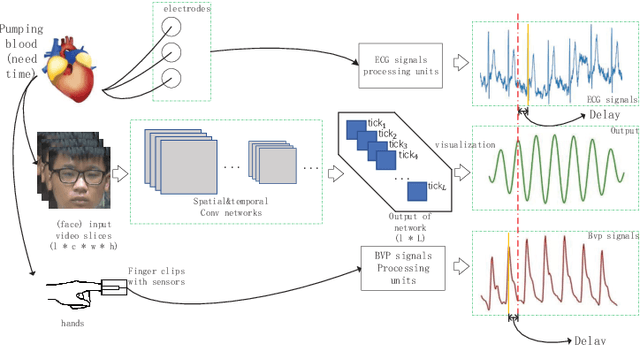
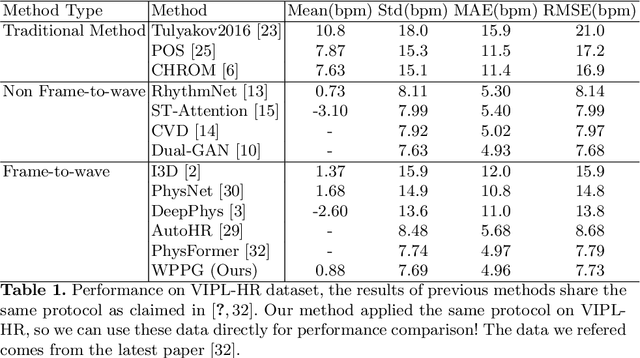
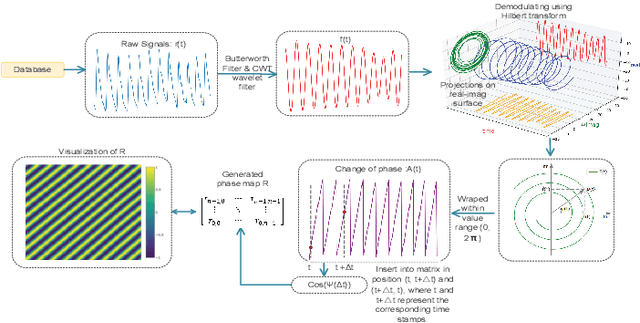
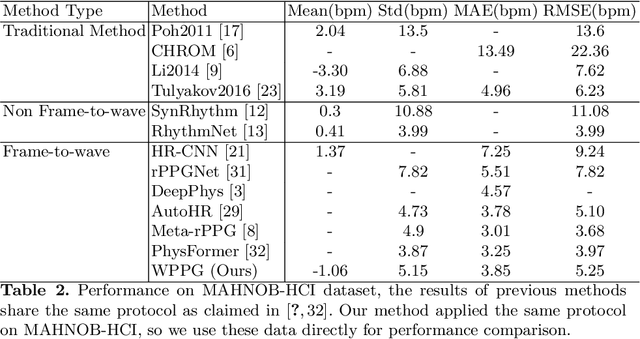
Our facial skin presents subtle color change known as remote Photoplethysmography (rPPG) signal, from which we could extract the heart rate of the subject. Recently many deep learning methods and related datasets on rPPG signal extraction are proposed. However, because of the time consumption blood flowing through our body and other factors, label waves such as BVP signals have uncertain delays with real rPPG signals in some datasets, which results in the difficulty on training of networks which output predicted rPPG waves directly. In this paper, by analyzing the common characteristics on rhythm and periodicity of rPPG signals and label waves, we propose a whole set of training methodology which wraps these networks so that they could remain efficient when be trained at the presence of frequent uncertain delay in datasets and gain more precise and robust heart rate prediction results than other delay-free rPPG extraction methods.