 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-IAP: Training-Free Visual Token Pruning via Interaction Alignment for Vision-Language-Action Models
Mar 24, 2026Vision-Language-Action (VLA) models have rapidly advanced embodied intelligence, enabling robots to execute complex, instruction-driven tasks. However, as model capacity and visual context length grow, the inference cost of VLA systems becomes a major bottleneck for real-world deployment on resource-constrained platforms. Existing visual token pruning methods mainly rely on semantic saliency or simple temporal cues, overlooking the continuous physical interaction, a fundamental property of VLA tasks. Consequently, current approaches often prune visually sparse yet structurally critical regions that support manipulation, leading to unstable behavior during early task phases. To overcome this, we propose a shift toward an explicit Interaction-First paradigm. Our proposed \textbf{training-free} method, VLA-IAP (Interaction-Aligned Pruning), introduces a geometric prior mechanism to preserve structural anchors and a dynamic scheduling strategy that adapts pruning intensity based on semantic-motion alignment. This enables a conservative-to-aggressive transition, ensuring robustness during early uncertainty and efficiency once interaction is locked. Extensive experiments show that VLA-IAP achieves a \textbf{97.8\% success rate} with a \textbf{$1.25\times$ speedup} on the LIBERO benchmark, and up to \textbf{$1.54\times$ speedup} while maintaining performance \textbf{comparable to the unpruned backbone}. Moreover, the method demonstrates superior and consistent performance across multiple model architectures and three different simulation environments, as well as a real robot platform, validating its strong generalization capability and practical applicability. Our project website is: \href{https://chengjt1999.github.io/VLA-IAP.github.io/}{VLA-IAP.com}.
Invariance on Manifolds: Understanding Robust Visual Representations for Place Recognition
Jan 31, 2026Visual Place Recognition (VPR) demands representations robust to drastic environmental and viewpoint shifts. Current aggregation paradigms, however, either rely on data-hungry supervision or simplistic first-order statistics, often neglecting intrinsic structural correlations. In this work, we propose a Second-Order Geometric Statistics framework that inherently captures geometric stability without training. We conceptualize scenes as covariance descriptors on the Symmetric Positive Definite (SPD) manifold, where perturbations manifest as tractable congruence transformations. By leveraging geometry-aware Riemannian mappings, we project these descriptors into a linearized Euclidean embedding, effectively decoupling signal structure from noise. Our approach introduces a training-free framework built upon fixed, pre-trained backbones, achieving strong zero-shot generalization without parameter updates. Extensive experiments confirm that our method achieves highly competitive performance against state-of-the-art baselines, particularly excelling in challenging zero-shot scenarios.
MetaCD: A Meta Learning Framework for Cognitive Diagnosis based on Continual Learning
Dec 28, 2025Cognitive diagnosis is an essential research topic in intelligent education, aimed at assessing the level of mastery of different skills by students. So far, many research works have used deep learning models to explore the complex interactions between students, questions, and skills. However, the performance of existing method is frequently limited by the long-tailed distribution and dynamic changes in the data. To address these challenges, we propose a meta-learning framework for cognitive diagnosis based on continual learning (MetaCD). This framework can alleviate the long-tailed problem by utilizing meta-learning to learn the optimal initialization state, enabling the model to achieve good accuracy on new tasks with only a small amount of data. In addition, we utilize a continual learning method named parameter protection mechanism to give MetaCD the ability to adapt to new skills or new tasks, in order to adapt to dynamic changes in data. MetaCD can not only improve the plasticity of our model on a single task, but also ensure the stability and generalization of the model on sequential tasks. Comprehensive experiments on five real-world datasets show that MetaCD outperforms other baselines in both accuracy and generalization.
MA-SLAM: Active SLAM in Large-Scale Unknown Environment using Map Aware Deep Reinforcement Learning
Nov 18, 2025Active Simultaneous Localization and Mapping (Active SLAM) involves the strategic planning and precise control of a robotic system's movement in order to construct a highly accurate and comprehensive representation of its surrounding environment, which has garnered significant attention within the research community. While the current methods demonstrate efficacy in small and controlled settings, they face challenges when applied to large-scale and diverse environments, marked by extended periods of exploration and suboptimal paths of discovery. In this paper, we propose MA-SLAM, a Map-Aware Active SLAM system based on Deep Reinforcement Learning (DRL), designed to address the challenge of efficient exploration in large-scale environments. In pursuit of this objective, we put forward a novel structured map representation. By discretizing the spatial data and integrating the boundary points and the historical trajectory, the structured map succinctly and effectively encapsulates the visited regions, thereby serving as input for the deep reinforcement learning based decision module. Instead of sequentially predicting the next action step within the decision module, we have implemented an advanced global planner to optimize the exploration path by leveraging long-range target points. We conducted experiments in three simulation environments and deployed in a real unmanned ground vehicle (UGV), the results demonstrate that our approach significantly reduces both the duration and distance of exploration compared with state-of-the-art methods.
Compose Yourself: Average-Velocity Flow Matching for One-Step Speech Enhancement
Sep 19, 2025Diffusion and flow matching (FM) models have achieved remarkable progress in speech enhancement (SE), yet their dependence on multi-step generation is computationally expensive and vulnerable to discretization errors. Recent advances in one-step generative modeling, particularly MeanFlow, provide a promising alternative by reformulating dynamics through average velocity fields. In this work, we present COSE, a one-step FM framework tailored for SE. To address the high training overhead of Jacobian-vector product (JVP) computations in MeanFlow, we introduce a velocity composition identity to compute average velocity efficiently, eliminating expensive computation while preserving theoretical consistency and achieving competitive enhancement quality. Extensive experiments on standard benchmarks show that COSE delivers up to 5x faster sampling and reduces training cost by 40%, all without compromising speech quality. Code is available at https://github.com/ICDM-UESTC/COSE.
A Pseudo Global Fusion Paradigm-Based Cross-View Network for LiDAR-Based Place Recognition
Aug 12, 2025LiDAR-based Place Recognition (LPR) remains a critical task in Embodied Artificial Intelligence (AI) and Autonomous Driving, primarily addressing localization challenges in GPS-denied environments and supporting loop closure detection. Existing approaches reduce place recognition to a Euclidean distance-based metric learning task, neglecting the feature space's intrinsic structures and intra-class variances. Such Euclidean-centric formulation inherently limits the model's capacity to capture nonlinear data distributions, leading to suboptimal performance in complex environments and temporal-varying scenarios. To address these challenges, we propose a novel cross-view network based on an innovative fusion paradigm. Our framework introduces a pseudo-global information guidance mechanism that coordinates multi-modal branches to perform feature learning within a unified semantic space. Concurrently, we propose a Manifold Adaptation and Pairwise Variance-Locality Learning Metric that constructs a Symmetric Positive Definite (SPD) matrix to compute Mahalanobis distance, superseding traditional Euclidean distance metrics. This geometric formulation enables the model to accurately characterize intrinsic data distributions and capture complex inter-class dependencies within the feature space. Experimental results demonstrate that the proposed algorithm achieves competitive performance, particularly excelling in complex environmental conditions.
Real-Time AIoT for UAV Antenna Interference Detection via Edge-Cloud Collaboration
Dec 04, 2024



In the fifth-generation (5G) era, eliminating communication interference sources is crucial for maintaining network performance. Interference often originates from unauthorized or malfunctioning antennas, and radio monitoring agencies must address numerous sources of such antennas annually. Unmanned aerial vehicles (UAVs) can improve inspection efficiency. However, the data transmission delay in the existing cloud-only (CO) artificial intelligence (AI) mode fails to meet the low latency requirements for real-time performance. Therefore, we propose a computer vision-based AI of Things (AIoT) system to detect antenna interference sources for UAVs. The system adopts an optimized edge-cloud collaboration (ECC+) mode, combining a keyframe selection algorithm (KSA), focusing on reducing end-to-end latency (E2EL) and ensuring reliable data transmission, which aligns with the core principles of ultra-reliable low-latency communication (URLLC). At the core of our approach is an end-to-end antenna localization scheme based on the tracking-by-detection (TBD) paradigm, including a detector (EdgeAnt) and a tracker (AntSort). EdgeAnt achieves state-of-the-art (SOTA) performance with a mean average precision (mAP) of 42.1% on our custom antenna interference source dataset, requiring only 3 million parameters and 14.7 GFLOPs. On the COCO dataset, EdgeAnt achieves 38.9% mAP with 5.4 GFLOPs. We deployed EdgeAnt on Jetson Xavier NX (TRT) and Raspberry Pi 4B (NCNN), achieving real-time inference speeds of 21.1 (1088) and 4.8 (640) frames per second (FPS), respectively. Compared with CO mode, the ECC+ mode reduces E2EL by 88.9%, increases accuracy by 28.2%. Additionally, the system offers excellent scalability for coordinated multiple UAVs inspections. The detector code is publicly available at https://github.com/SCNU-RISLAB/EdgeAnt.
Real-Time Metric-Semantic Mapping for Autonomous Navigation in Outdoor Environments
Nov 30, 2024


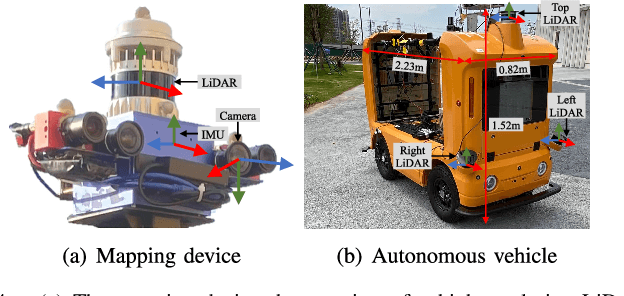
The creation of a metric-semantic map, which encodes human-prior knowledge, represents a high-level abstraction of environments. However, constructing such a map poses challenges related to the fusion of multi-modal sensor data, the attainment of real-time mapping performance, and the preservation of structural and semantic information consistency. In this paper, we introduce an online metric-semantic mapping system that utilizes LiDAR-Visual-Inertial sensing to generate a global metric-semantic mesh map of large-scale outdoor environments. Leveraging GPU acceleration, our mapping process achieves exceptional speed, with frame processing taking less than 7ms, regardless of scenario scale. Furthermore, we seamlessly integrate the resultant map into a real-world navigation system, enabling metric-semantic-based terrain assessment and autonomous point-to-point navigation within a campus environment. Through extensive experiments conducted on both publicly available and self-collected datasets comprising 24 sequences, we demonstrate the effectiveness of our mapping and navigation methodologies. Code has been publicly released: https://github.com/gogojjh/cobra
MapEval: Towards Unified, Robust and Efficient SLAM Map Evaluation Framework
Nov 26, 2024



Evaluating massive-scale point cloud maps in Simultaneous Localization and Mapping (SLAM) remains challenging, primarily due to the absence of unified, robust and efficient evaluation frameworks. We present MapEval, an open-source framework for comprehensive quality assessment of point cloud maps, specifically addressing SLAM scenarios where ground truth map is inherently sparse compared to the mapped environment. Through systematic analysis of existing evaluation metrics in SLAM applications, we identify their fundamental limitations and establish clear guidelines for consistent map quality assessment. Building upon these insights, we propose a novel Gaussian-approximated Wasserstein distance in voxelized space, enabling two complementary metrics under the same error standard: Voxelized Average Wasserstein Distance (AWD) for global geometric accuracy and Spatial Consistency Score (SCS) for local consistency evaluation. This theoretical foundation leads to significant improvements in both robustness against noise and computational efficiency compared to conventional metrics. Extensive experiments on both simulated and real-world datasets demonstrate that MapEval achieves at least \SI{100}{}-\SI{500}{} times faster while maintaining evaluation integrity. The MapEval library\footnote{\texttt{https://github.com/JokerJohn/Cloud\_Map\_Evaluation}} will be publicly available to promote standardized map evaluation practices in the robotics community.
GS-LIVM: Real-Time Photo-Realistic LiDAR-Inertial-Visual Mapping with Gaussian Splatting
Oct 18, 2024
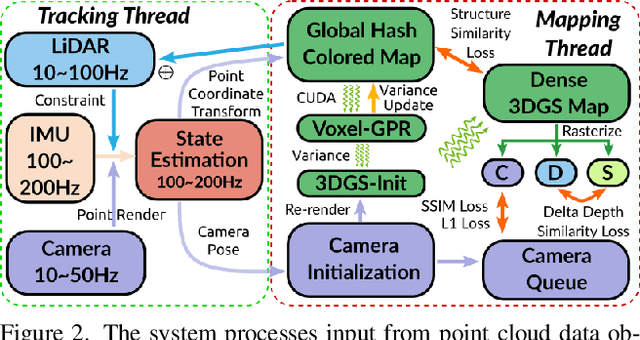
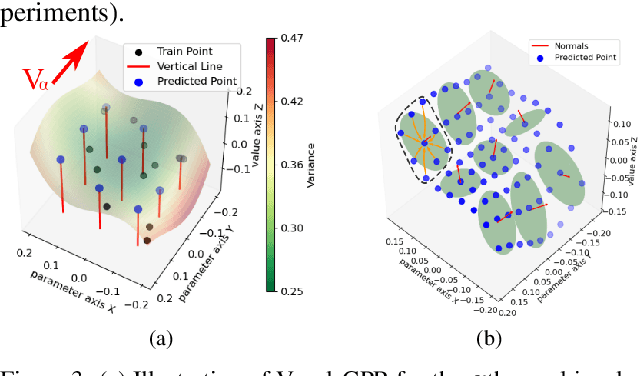
In this paper, we introduce GS-LIVM, a real-time photo-realistic LiDAR-Inertial-Visual mapping framework with Gaussian Splatting tailored for outdoor scenes. Compared to existing methods based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), our approach enables real-time photo-realistic mapping while ensuring high-quality image rendering in large-scale unbounded outdoor environments. In this work, Gaussian Process Regression (GPR) is employed to mitigate the issues resulting from sparse and unevenly distributed LiDAR observations. The voxel-based 3D Gaussians map representation facilitates real-time dense mapping in large outdoor environments with acceleration governed by custom CUDA kernels. Moreover, the overall framework is designed in a covariance-centered manner, where the estimated covariance is used to initialize the scale and rotation of 3D Gaussians, as well as update the parameters of the GPR. We evaluate our algorithm on several outdoor datasets, and the results demonstrate that our method achieves state-of-the-art performance in terms of mapping efficiency and rendering quality. The source code is available on GitHub.