 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLKD: Inter-Class Relation Learning with Knowledge Distillation for Generalized Category Discovery
Dec 08, 2025Generalized Category Discovery (GCD) faces the challenge of categorizing unlabeled data containing both known and novel classes, given only labels for known classes. Previous studies often treat each class independently, neglecting the inherent inter-class relations. Obtaining such inter-class relations directly presents a significant challenge in real-world scenarios. To address this issue, we propose ReLKD, an end-to-end framework that effectively exploits implicit inter-class relations and leverages this knowledge to enhance the classification of novel classes. ReLKD comprises three key modules: a target-grained module for learning discriminative representations, a coarse-grained module for capturing hierarchical class relations, and a distillation module for transferring knowledge from the coarse-grained module to refine the target-grained module's representation learning. Extensive experiments on four datasets demonstrate the effectiveness of ReLKD, particularly in scenarios with limited labeled data. The code for ReLKD is available at https://github.com/ZhouF-ECNU/ReLKD.
Projection Embedded Diffusion Bridge for CT Reconstruction from Incomplete Data
Oct 26, 2025Reconstructing CT images from incomplete projection data remains challenging due to the ill-posed nature of the problem. Diffusion bridge models have recently shown promise in restoring clean images from their corresponding Filtered Back Projection (FBP) reconstructions, but incorporating data consistency into these models remains largely underexplored. Incorporating data consistency can improve reconstruction fidelity by aligning the reconstructed image with the observed projection data, and can enhance detail recovery by integrating structural information contained in the projections. In this work, we propose the Projection Embedded Diffusion Bridge (PEDB). PEDB introduces a novel reverse stochastic differential equation (SDE) to sample from the distribution of clean images conditioned on both the FBP reconstruction and the incomplete projection data. By explicitly conditioning on the projection data in sampling the clean images, PEDB naturally incorporates data consistency. We embed the projection data into the score function of the reverse SDE. Under certain assumptions, we derive a tractable expression for the posterior score. In addition, we introduce a free parameter to control the level of stochasticity in the reverse process. We also design a discretization scheme for the reverse SDE to mitigate discretization error. Extensive experiments demonstrate that PEDB achieves strong performance in CT reconstruction from three types of incomplete data, including sparse-view, limited-angle, and truncated projections. For each of these types, PEDB outperforms evaluated state-of-the-art diffusion bridge models across standard, noisy, and domain-shift evaluations.
REF-VLM: Triplet-Based Referring Paradigm for Unified Visual Decoding
Mar 10, 2025
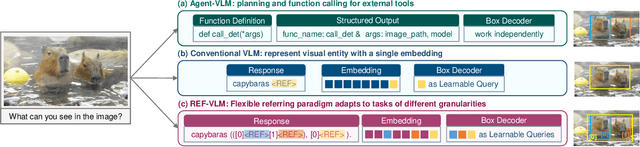

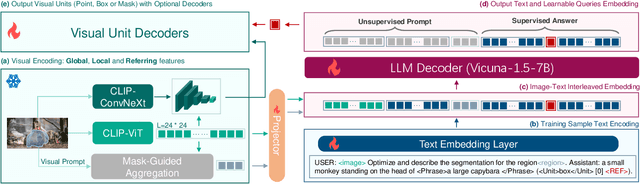
Multimodal Large Language Models (MLLMs) demonstrate robust zero-shot capabilities across diverse vision-language tasks after training on mega-scale datasets. However, dense prediction tasks, such as semantic segmentation and keypoint detection, pose significant challenges for MLLMs when represented solely as text outputs. Simultaneously, current MLLMs utilizing latent embeddings for visual task decoding generally demonstrate limited adaptability to both multi-task learning and multi-granularity scenarios. In this work, we present REF-VLM, an end-to-end framework for unified training of various visual decoding tasks. To address complex visual decoding scenarios, we introduce the Triplet-Based Referring Paradigm (TRP), which explicitly decouples three critical dimensions in visual decoding tasks through a triplet structure: concepts, decoding types, and targets. TRP employs symbolic delimiters to enforce structured representation learning, enhancing the parsability and interpretability of model outputs. Additionally, we construct Visual-Task Instruction Following Dataset (VTInstruct), a large-scale multi-task dataset containing over 100 million multimodal dialogue samples across 25 task types. Beyond text inputs and outputs, VT-Instruct incorporates various visual prompts such as point, box, scribble, and mask, and generates outputs composed of text and visual units like box, keypoint, depth and mask. The combination of different visual prompts and visual units generates a wide variety of task types, expanding the applicability of REF-VLM significantly. Both qualitative and quantitative experiments demonstrate that our REF-VLM outperforms other MLLMs across a variety of standard benchmarks. The code, dataset, and demo available at https://github.com/MacavityT/REF-VLM.
An Ordinary Differential Equation Sampler with Stochastic Start for Diffusion Bridge Models
Dec 28, 2024



Diffusion bridge models have demonstrated promising performance in conditional image generation tasks, such as image restoration and translation, by initializing the generative process from corrupted images instead of pure Gaussian noise. However, existing diffusion bridge models often rely on Stochastic Differential Equation (SDE) samplers, which result in slower inference speed compared to diffusion models that employ high-order Ordinary Differential Equation (ODE) solvers for acceleration. To mitigate this gap, we propose a high-order ODE sampler with a stochastic start for diffusion bridge models. To overcome the singular behavior of the probability flow ODE (PF-ODE) at the beginning of the reverse process, a posterior sampling approach was introduced at the first reverse step. The sampling was designed to ensure a smooth transition from corrupted images to the generative trajectory while reducing discretization errors. Following this stochastic start, Heun's second-order solver is applied to solve the PF-ODE, achieving high perceptual quality with significantly reduced neural function evaluations (NFEs). Our method is fully compatible with pretrained diffusion bridge models and requires no additional training. Extensive experiments on image restoration and translation tasks, including super-resolution, JPEG restoration, Edges-to-Handbags, and DIODE-Outdoor, demonstrated that our sampler outperforms state-of-the-art methods in both visual quality and Frechet Inception Distance (FID).
CaRtGS: Computational Alignment for Real-Time Gaussian Splatting SLAM
Oct 02, 2024Simultaneous Localization and Mapping (SLAM) is pivotal in robotics, with photorealistic scene reconstruction emerging as a key challenge. To address this, we introduce Computational Alignment for Real-Time Gaussian Splatting SLAM (CaRtGS), a novel method enhancing the efficiency and quality of photorealistic scene reconstruction in real-time environments. Leveraging 3D Gaussian Splatting (3DGS), CaRtGS achieves superior rendering quality and processing speed, which is crucial for scene photorealistic reconstruction. Our approach tackles computational misalignment in Gaussian Splatting SLAM (GS-SLAM) through an adaptive strategy that optimizes training, addresses long-tail optimization, and refines densification. Experiments on Replica and TUM-RGBD datasets demonstrate CaRtGS's effectiveness in achieving high-fidelity rendering with fewer Gaussian primitives. This work propels SLAM towards real-time, photorealistic dense rendering, significantly advancing photorealistic scene representation. For the benefit of the research community, we release the code on our project website: https://dapengfeng.github.io/cartgs.
Learning from Pattern Completion: Self-supervised Controllable Generation
Sep 27, 2024
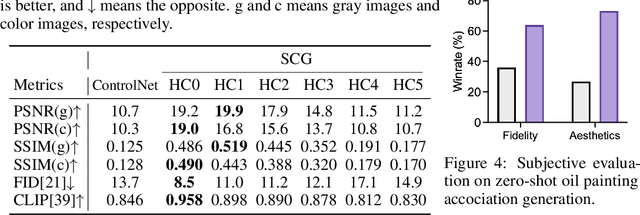
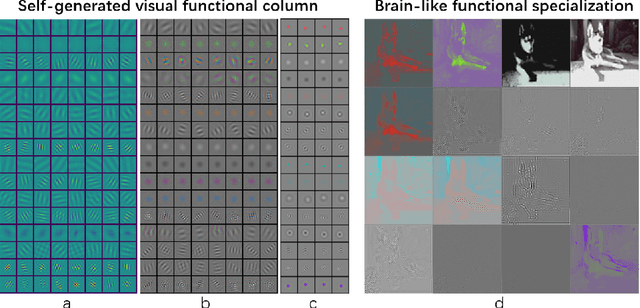

The human brain exhibits a strong ability to spontaneously associate different visual attributes of the same or similar visual scene, such as associating sketches and graffiti with real-world visual objects, usually without supervising information. In contrast, in the field of artificial intelligence, controllable generation methods like ControlNet heavily rely on annotated training datasets such as depth maps, semantic segmentation maps, and poses, which limits the method's scalability. Inspired by the neural mechanisms that may contribute to the brain's associative power, specifically the cortical modularization and hippocampal pattern completion, here we propose a self-supervised controllable generation (SCG) framework. Firstly, we introduce an equivariant constraint to promote inter-module independence and intra-module correlation in a modular autoencoder network, thereby achieving functional specialization. Subsequently, based on these specialized modules, we employ a self-supervised pattern completion approach for controllable generation training. Experimental results demonstrate that the proposed modular autoencoder effectively achieves functional specialization, including the modular processing of color, brightness, and edge detection, and exhibits brain-like features including orientation selectivity, color antagonism, and center-surround receptive fields. Through self-supervised training, associative generation capabilities spontaneously emerge in SCG, demonstrating excellent generalization ability to various tasks such as associative generation on painting, sketches, and ancient graffiti. Compared to the previous representative method ControlNet, our proposed approach not only demonstrates superior robustness in more challenging high-noise scenarios but also possesses more promising scalability potential due to its self-supervised manner.
Heterogeneous LiDAR Dataset for Benchmarking Robust Localization in Diverse Degenerate Scenarios
Sep 10, 2024The ability to estimate pose and generate maps using 3D LiDAR significantly enhances robotic system autonomy. However, existing open-source datasets lack representation of geometrically degenerate environments, limiting the development and benchmarking of robust LiDAR SLAM algorithms. To address this gap, we introduce GEODE, a comprehensive multi-LiDAR, multi-scenario dataset specifically designed to include real-world geometrically degenerate environments. GEODE comprises 64 trajectories spanning over 64 kilometers across seven diverse settings with varying degrees of degeneracy. The data was meticulously collected to promote the development of versatile algorithms by incorporating various LiDAR sensors, stereo cameras, IMUs, and diverse motion conditions. We evaluate state-of-the-art SLAM approaches using the GEODE dataset to highlight current limitations in LiDAR SLAM techniques. This extensive dataset will be publicly available at https://geode.github.io, supporting further advancements in LiDAR-based SLAM.
RELEAD: Resilient Localization with Enhanced LiDAR Odometry in Adverse Environments
Mar 15, 2024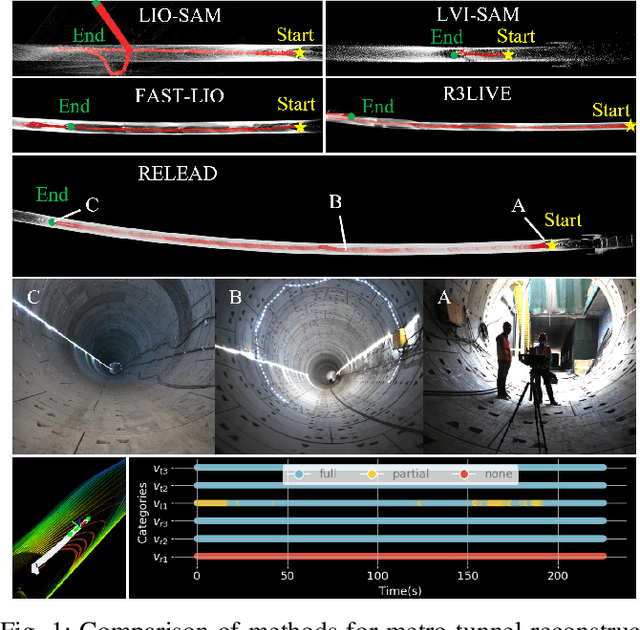
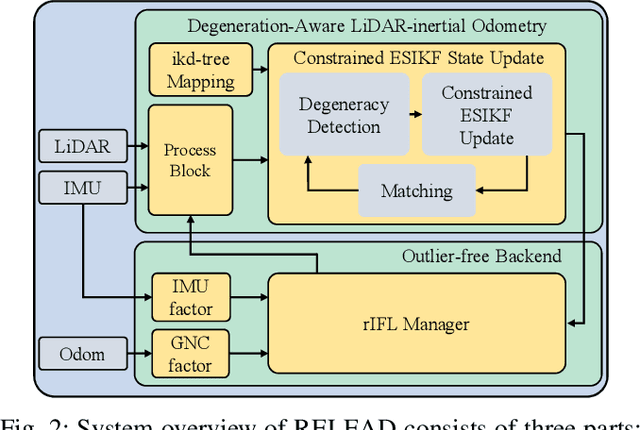
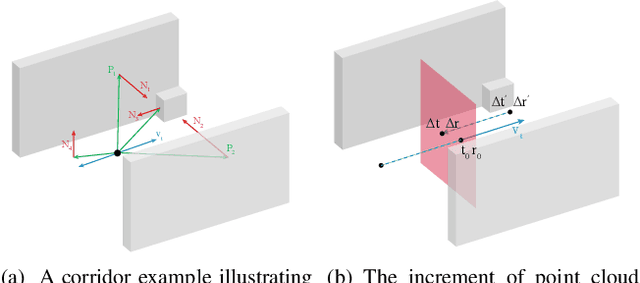
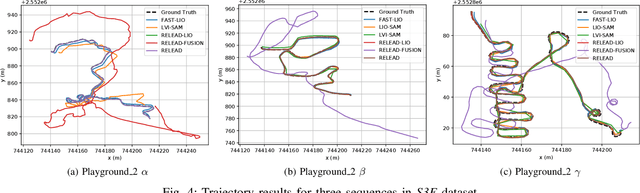
LiDAR-based localization is valuable for applications like mining surveys and underground facility maintenance. However, existing methods can struggle when dealing with uninformative geometric structures in challenging scenarios. This paper presents RELEAD, a LiDAR-centric solution designed to address scan-matching degradation. Our method enables degeneracy-free point cloud registration by solving constrained ESIKF updates in the front end and incorporates multisensor constraints, even when dealing with outlier measurements, through graph optimization based on Graduated Non-Convexity (GNC). Additionally, we propose a robust Incremental Fixed Lag Smoother (rIFL) for efficient GNC-based optimization. RELEAD has undergone extensive evaluation in degenerate scenarios and has outperformed existing state-of-the-art LiDAR-Inertial odometry and LiDAR-Visual-Inertial odometry methods.
Implicit Image-to-Image Schrodinger Bridge for CT Super-Resolution and Denoising
Mar 10, 2024Conditional diffusion models have gained recognition for their effectiveness in image restoration tasks, yet their iterative denoising process, starting from Gaussian noise, often leads to slow inference speeds. As a promising alternative, the Image-to-Image Schr\"odinger Bridge (I2SB) initializes the generative process from corrupted images and integrates training techniques from conditional diffusion models. In this study, we extended the I2SB method by introducing the Implicit Image-to-Image Schrodinger Bridge (I3SB), transitioning its generative process to a non-Markovian process by incorporating corrupted images in each generative step. This enhancement empowers I3SB to generate images with better texture restoration using a small number of generative steps. The proposed method was validated on CT super-resolution and denoising tasks and outperformed existing methods, including the conditional denoising diffusion probabilistic model (cDDPM) and I2SB, in both visual quality and quantitative metrics. These findings underscore the potential of I3SB in improving medical image restoration by providing fast and accurate generative modeling.
CoLRIO: LiDAR-Ranging-Inertial Centralized State Estimation for Robotic Swarms
Feb 23, 2024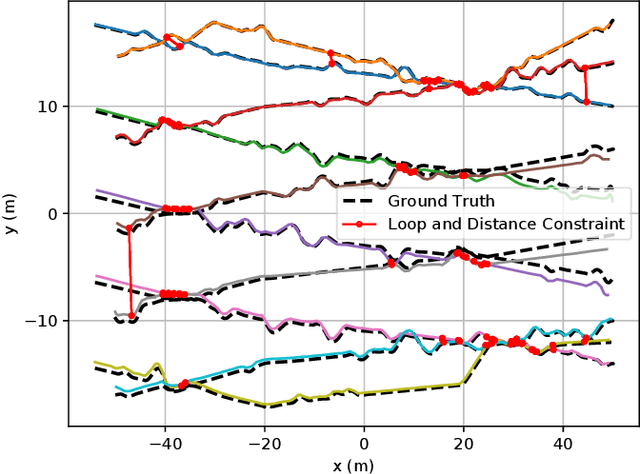
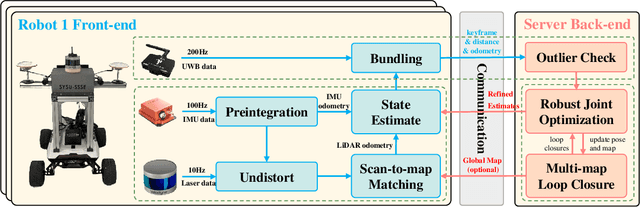
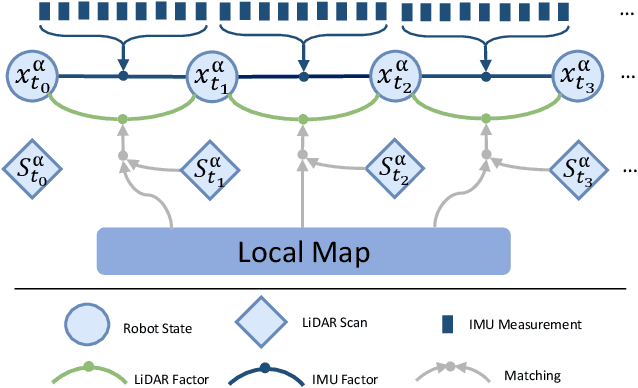
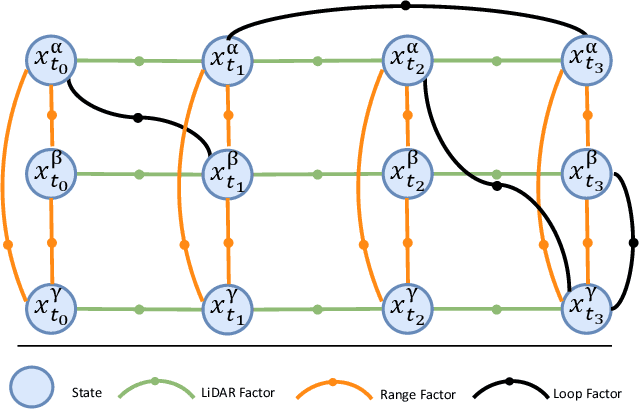
Collaborative state estimation using different heterogeneous sensors is a fundamental prerequisite for robotic swarms operating in GPS-denied environments, posing a significant research challenge. In this paper, we introduce a centralized system to facilitate collaborative LiDAR-ranging-inertial state estimation, enabling robotic swarms to operate without the need for anchor deployment. The system efficiently distributes computationally intensive tasks to a central server, thereby reducing the computational burden on individual robots for local odometry calculations. The server back-end establishes a global reference by leveraging shared data and refining joint pose graph optimization through place recognition, global optimization techniques, and removal of outlier data to ensure precise and robust collaborative state estimation. Extensive evaluations of our system, utilizing both publicly available datasets and our custom datasets, demonstrate significant enhancements in the accuracy of collaborative SLAM estimates. Moreover, our system exhibits remarkable proficiency in large-scale missions, seamlessly enabling ten robots to collaborate effectively in performing SLAM tasks. In order to contribute to the research community, we will make our code open-source and accessible at \url{https://github.com/PengYu-team/Co-LRIO}.