 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaguan-TS: A Sequence-Native In-Context Learning Model for Time Series Forecasting with Covariates
Mar 18, 2026Transformers enable in-context learning (ICL) for rapid, gradient-free adaptation in time series forecasting, yet most ICL-style approaches rely on tabularized, hand-crafted features, while end-to-end sequence models lack inference-time adaptation. We bridge this gap with a unified framework, Baguan-TS, which integrates the raw-sequence representation learning with ICL, instantiated by a 3D Transformer that attends jointly over temporal, variable, and context axes. To make this high-capacity model practical, we tackle two key hurdles: (i) calibration and training stability, improved with a feature-agnostic, target-space retrieval-based local calibration; and (ii) output oversmoothing, mitigated via context-overfitting strategy. On public benchmark with covariates, Baguan-TS consistently outperforms established baselines, achieving the highest win rate and significant reductions in both point and probabilistic forecasting metrics. Further evaluations across diverse real-world energy datasets demonstrate its robustness, yielding substantial improvements.
S3E: A Large-scale Multimodal Dataset for Collaborative SLAM
Oct 25, 2022



With the advanced request to employ a team of robots to perform a task collaboratively, the research community has become increasingly interested in collaborative simultaneous localization and mapping. Unfortunately, existing datasets are limited in the scale and variation of the collaborative trajectories they capture, even though generalization between inter-trajectories among different agents is crucial to the overall viability of collaborative tasks. To help align the research community's contributions with real-world multiagent ordinated SLAM problems, we introduce S3E, a novel large-scale multimodal dataset captured by a fleet of unmanned ground vehicles along four designed collaborative trajectory paradigms. S3E consists of 7 outdoor and 5 indoor scenes that each exceed 200 seconds, consisting of well synchronized and calibrated high-quality stereo camera, LiDAR, and high-frequency IMU data. Crucially, our effort exceeds previous attempts regarding dataset size, scene variability, and complexity. It has 4x as much average recording time as the pioneering EuRoC dataset. We also provide careful dataset analysis as well as baselines for collaborative SLAM and single counterparts. Find data, code, and more up-to-date information at https://github.com/PengYu-Team/S3E.
CNN Is All You Need
Dec 27, 2017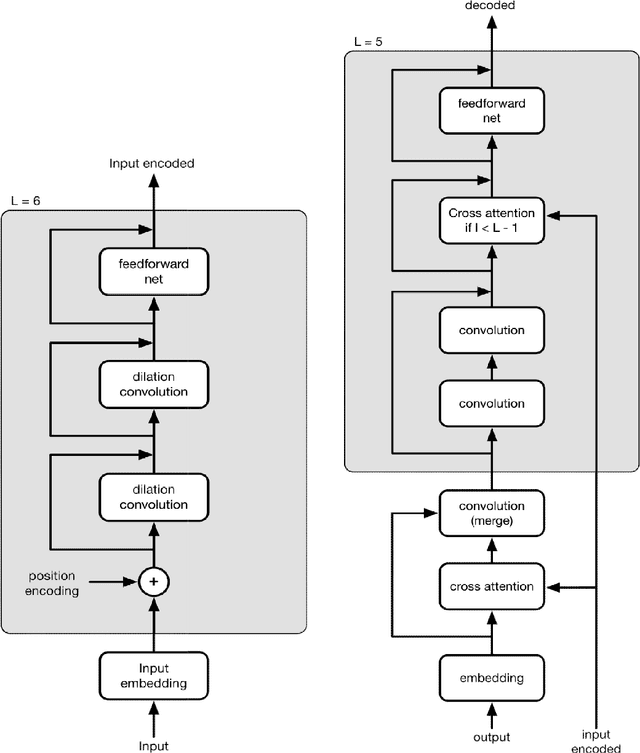

The Convolution Neural Network (CNN) has demonstrated the unique advantage in audio, image and text learning; recently it has also challenged Recurrent Neural Networks (RNNs) with long short-term memory cells (LSTM) in sequence-to-sequence learning, since the computations involved in CNN are easily parallelizable whereas those involved in RNN are mostly sequential, leading to a performance bottleneck. However, unlike RNN, the native CNN lacks the history sensitivity required for sequence transformation; therefore enhancing the sequential order awareness, or position-sensitivity, becomes the key to make CNN the general deep learning model. In this work we introduce an extended CNN model with strengthen position-sensitivity, called PoseNet. A notable feature of PoseNet is the asymmetric treatment of position information in the encoder and the decoder. Experiments shows that PoseNet allows us to improve the accuracy of CNN based sequence-to-sequence learning significantly, achieving around 33-36 BLEU scores on the WMT 2014 English-to-German translation task, and around 44-46 BLEU scores on the English-to-French translation task.