 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjection Embedded Diffusion Bridge for CT Reconstruction from Incomplete Data
Oct 26, 2025Reconstructing CT images from incomplete projection data remains challenging due to the ill-posed nature of the problem. Diffusion bridge models have recently shown promise in restoring clean images from their corresponding Filtered Back Projection (FBP) reconstructions, but incorporating data consistency into these models remains largely underexplored. Incorporating data consistency can improve reconstruction fidelity by aligning the reconstructed image with the observed projection data, and can enhance detail recovery by integrating structural information contained in the projections. In this work, we propose the Projection Embedded Diffusion Bridge (PEDB). PEDB introduces a novel reverse stochastic differential equation (SDE) to sample from the distribution of clean images conditioned on both the FBP reconstruction and the incomplete projection data. By explicitly conditioning on the projection data in sampling the clean images, PEDB naturally incorporates data consistency. We embed the projection data into the score function of the reverse SDE. Under certain assumptions, we derive a tractable expression for the posterior score. In addition, we introduce a free parameter to control the level of stochasticity in the reverse process. We also design a discretization scheme for the reverse SDE to mitigate discretization error. Extensive experiments demonstrate that PEDB achieves strong performance in CT reconstruction from three types of incomplete data, including sparse-view, limited-angle, and truncated projections. For each of these types, PEDB outperforms evaluated state-of-the-art diffusion bridge models across standard, noisy, and domain-shift evaluations.
Surf2CT: Cascaded 3D Flow Matching Models for Torso 3D CT Synthesis from Skin Surface
May 29, 2025We present Surf2CT, a novel cascaded flow matching framework that synthesizes full 3D computed tomography (CT) volumes of the human torso from external surface scans and simple demographic data (age, sex, height, weight). This is the first approach capable of generating realistic volumetric internal anatomy images solely based on external body shape and demographics, without any internal imaging. Surf2CT proceeds through three sequential stages: (1) Surface Completion, reconstructing a complete signed distance function (SDF) from partial torso scans using conditional 3D flow matching; (2) Coarse CT Synthesis, generating a low-resolution CT volume from the completed SDF and demographic information; and (3) CT Super-Resolution, refining the coarse volume into a high-resolution CT via a patch-wise conditional flow model. Each stage utilizes a 3D-adapted EDM2 backbone trained via flow matching. We trained our model on a combined dataset of 3,198 torso CT scans (approximately 1.13 million axial slices) sourced from Massachusetts General Hospital (MGH) and the AutoPET challenge. Evaluation on 700 paired torso surface-CT cases demonstrated strong anatomical fidelity: organ volumes exhibited small mean percentage differences (range from -11.1% to 4.4%), and muscle/fat body composition metrics matched ground truth with strong correlation (range from 0.67 to 0.96). Lung localization had minimal bias (mean difference -2.5 mm), and surface completion significantly improved metrics (Chamfer distance: from 521.8 mm to 2.7 mm; Intersection-over-Union: from 0.87 to 0.98). Surf2CT establishes a new paradigm for non-invasive internal anatomical imaging using only external data, opening opportunities for home-based healthcare, preventive medicine, and personalized clinical assessments without the risks associated with conventional imaging techniques.
Cascaded 3D Diffusion Models for Whole-body 3D 18-F FDG PET/CT synthesis from Demographics
May 28, 2025We propose a cascaded 3D diffusion model framework to synthesize high-fidelity 3D PET/CT volumes directly from demographic variables, addressing the growing need for realistic digital twins in oncologic imaging, virtual trials, and AI-driven data augmentation. Unlike deterministic phantoms, which rely on predefined anatomical and metabolic templates, our method employs a two-stage generative process. An initial score-based diffusion model synthesizes low-resolution PET/CT volumes from demographic variables alone, providing global anatomical structures and approximate metabolic activity. This is followed by a super-resolution residual diffusion model that refines spatial resolution. Our framework was trained on 18-F FDG PET/CT scans from the AutoPET dataset and evaluated using organ-wise volume and standardized uptake value (SUV) distributions, comparing synthetic and real data between demographic subgroups. The organ-wise comparison demonstrated strong concordance between synthetic and real images. In particular, most deviations in metabolic uptake values remained within 3-5% of the ground truth in subgroup analysis. These findings highlight the potential of cascaded 3D diffusion models to generate anatomically and metabolically accurate PET/CT images, offering a robust alternative to traditional phantoms and enabling scalable, population-informed synthetic imaging for clinical and research applications.
OWT: A Foundational Organ-Wise Tokenization Framework for Medical Imaging
May 08, 2025Recent advances in representation learning often rely on holistic, black-box embeddings that entangle multiple semantic components, limiting interpretability and generalization. These issues are especially critical in medical imaging. To address these limitations, we propose an Organ-Wise Tokenization (OWT) framework with a Token Group-based Reconstruction (TGR) training paradigm. Unlike conventional approaches that produce holistic features, OWT explicitly disentangles an image into separable token groups, each corresponding to a distinct organ or semantic entity. Our design ensures each token group encapsulates organ-specific information, boosting interpretability, generalization, and efficiency while allowing fine-grained control in downstream tasks. Experiments on CT and MRI datasets demonstrate the effectiveness of OWT in not only achieving strong image reconstruction and segmentation performance, but also enabling novel semantic-level generation and retrieval applications that are out of reach for standard holistic embedding methods. These findings underscore the potential of OWT as a foundational framework for semantically disentangled representation learning, offering broad scalability and applicability to real-world medical imaging scenarios and beyond.
Prediction of Frozen Region Growth in Kidney Cryoablation Intervention Using a 3D Flow-Matching Model
Mar 06, 2025This study presents a 3D flow-matching model designed to predict the progression of the frozen region (iceball) during kidney cryoablation. Precise intraoperative guidance is critical in cryoablation to ensure complete tumor eradication while preserving adjacent healthy tissue. However, conventional methods, typically based on physics driven or diffusion based simulations, are computationally demanding and often struggle to represent complex anatomical structures accurately. To address these limitations, our approach leverages intraoperative CT imaging to inform the model. The proposed 3D flow matching model is trained to learn a continuous deformation field that maps early-stage CT scans to future predictions. This transformation not only estimates the volumetric expansion of the iceball but also generates corresponding segmentation masks, effectively capturing spatial and morphological changes over time. Quantitative analysis highlights the model robustness, demonstrating strong agreement between predictions and ground-truth segmentations. The model achieves an Intersection over Union (IoU) score of 0.61 and a Dice coefficient of 0.75. By integrating real time CT imaging with advanced deep learning techniques, this approach has the potential to enhance intraoperative guidance in kidney cryoablation, improving procedural outcomes and advancing the field of minimally invasive surgery.
Pseudoinverse Diffusion Models for Generative CT Image Reconstruction from Low Dose Data
Feb 20, 2025



Score-based diffusion models have significantly advanced generative deep learning for image processing. Measurement conditioned models have also been applied to inverse problems such as CT reconstruction. However, the conventional approach, culminating in white noise, often requires a high number of reverse process update steps and score function evaluations. To address this limitation, we propose an alternative forward process in score-based diffusion models that aligns with the noise characteristics of low-dose CT reconstructions, rather than converging to white noise. This method significantly reduces the number of required score function evaluations, enhancing efficiency and maintaining familiar noise textures for radiologists, Our approach not only accelerates the generative process but also retains CT noise correlations, a key aspect often criticized by clinicians for deep learning reconstructions. In this work, we rigorously define a matrix-controlled stochastic process for this purpose and validate it through computational experiments. Using a dataset from The Cancer Genome Atlas Liver Hepatocellular Carcinoma (TCGA-LIHC), we simulate low-dose CT measurements and train our model, comparing it with a baseline scalar diffusion process and conditional diffusion model. Our results demonstrate the superiority of our pseudoinverse diffusion model in terms of efficiency and the ability to produce high-quality reconstructions that are familiar in texture to medical professionals in a low number of score function evaluations. This advancement paves the way for more efficient and clinically practical diffusion models in medical imaging, particularly beneficial in scenarios demanding rapid reconstructions or lower radiation exposure.
End-to-End Deep Learning for Interior Tomography with Low-Dose X-ray CT
Jan 09, 2025Objective: There exist several X-ray computed tomography (CT) scanning strategies to reduce a radiation dose, such as (1) sparse-view CT, (2) low-dose CT, and (3) region-of-interest (ROI) CT (called interior tomography). To further reduce the dose, the sparse-view and/or low-dose CT settings can be applied together with interior tomography. Interior tomography has various advantages in terms of reducing the number of detectors and decreasing the X-ray radiation dose. However, a large patient or small field-of-view (FOV) detector can cause truncated projections, and then the reconstructed images suffer from severe cupping artifacts. In addition, although the low-dose CT can reduce the radiation exposure dose, analytic reconstruction algorithms produce image noise. Recently, many researchers have utilized image-domain deep learning (DL) approaches to remove each artifact and demonstrated impressive performances, and the theory of deep convolutional framelets supports the reason for the performance improvement. Approach: In this paper, we found that the image-domain convolutional neural network (CNN) is difficult to solve coupled artifacts, based on deep convolutional framelets. Significance: To address the coupled problem, we decouple it into two sub-problems: (i) image domain noise reduction inside truncated projection to solve low-dose CT problem and (ii) extrapolation of projection outside truncated projection to solve the ROI CT problem. The decoupled sub-problems are solved directly with a novel proposed end-to-end learning using dual-domain CNNs. Main results: We demonstrate that the proposed method outperforms the conventional image-domain deep learning methods, and a projection-domain CNN shows better performance than the image-domain CNNs which are commonly used by many researchers.
An Ordinary Differential Equation Sampler with Stochastic Start for Diffusion Bridge Models
Dec 28, 2024



Diffusion bridge models have demonstrated promising performance in conditional image generation tasks, such as image restoration and translation, by initializing the generative process from corrupted images instead of pure Gaussian noise. However, existing diffusion bridge models often rely on Stochastic Differential Equation (SDE) samplers, which result in slower inference speed compared to diffusion models that employ high-order Ordinary Differential Equation (ODE) solvers for acceleration. To mitigate this gap, we propose a high-order ODE sampler with a stochastic start for diffusion bridge models. To overcome the singular behavior of the probability flow ODE (PF-ODE) at the beginning of the reverse process, a posterior sampling approach was introduced at the first reverse step. The sampling was designed to ensure a smooth transition from corrupted images to the generative trajectory while reducing discretization errors. Following this stochastic start, Heun's second-order solver is applied to solve the PF-ODE, achieving high perceptual quality with significantly reduced neural function evaluations (NFEs). Our method is fully compatible with pretrained diffusion bridge models and requires no additional training. Extensive experiments on image restoration and translation tasks, including super-resolution, JPEG restoration, Edges-to-Handbags, and DIODE-Outdoor, demonstrated that our sampler outperforms state-of-the-art methods in both visual quality and Frechet Inception Distance (FID).
Hallucination Index: An Image Quality Metric for Generative Reconstruction Models
Jul 17, 2024Generative image reconstruction algorithms such as measurement conditioned diffusion models are increasingly popular in the field of medical imaging. These powerful models can transform low signal-to-noise ratio (SNR) inputs into outputs with the appearance of high SNR. However, the outputs can have a new type of error called hallucinations. In medical imaging, these hallucinations may not be obvious to a Radiologist but could cause diagnostic errors. Generally, hallucination refers to error in estimation of object structure caused by a machine learning model, but there is no widely accepted method to evaluate hallucination magnitude. In this work, we propose a new image quality metric called the hallucination index. Our approach is to compute the Hellinger distance from the distribution of reconstructed images to a zero hallucination reference distribution. To evaluate our approach, we conducted a numerical experiment with electron microscopy images, simulated noisy measurements, and applied diffusion based reconstructions. We sampled the measurements and the generative reconstructions repeatedly to compute the sample mean and covariance. For the zero hallucination reference, we used the forward diffusion process applied to ground truth. Our results show that higher measurement SNR leads to lower hallucination index for the same apparent image quality. We also evaluated the impact of early stopping in the reverse diffusion process and found that more modest denoising strengths can reduce hallucination. We believe this metric could be useful for evaluation of generative image reconstructions or as a warning label to inform radiologists about the degree of hallucinations in medical images.
Contrastive Learning Via Equivariant Representation
Jun 01, 2024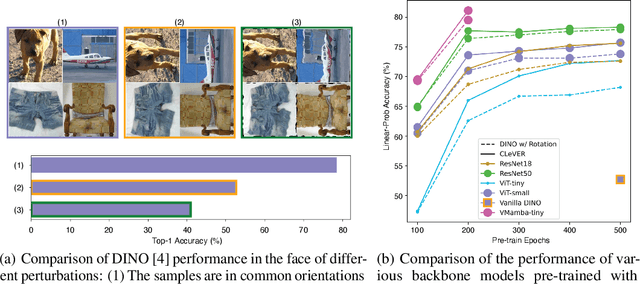
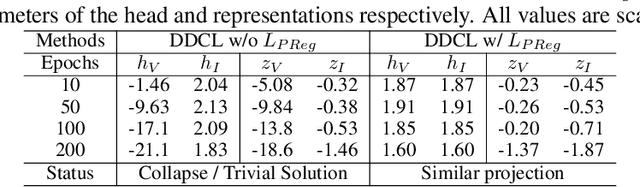
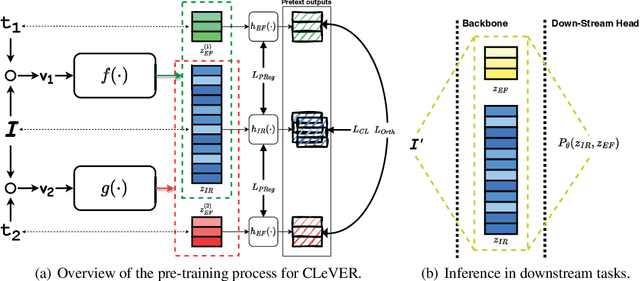
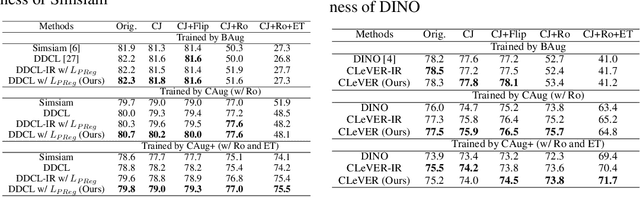
Invariant-based Contrastive Learning (ICL) methods have achieved impressive performance across various domains. However, the absence of latent space representation for distortion (augmentation)-related information in the latent space makes ICL sub-optimal regarding training efficiency and robustness in downstream tasks. Recent studies suggest that introducing equivariance into Contrastive Learning (CL) can improve overall performance. In this paper, we rethink the roles of augmentation strategies and equivariance in improving CL efficacy. We propose a novel Equivariant-based Contrastive Learning (ECL) framework, CLeVER (Contrastive Learning Via Equivariant Representation), compatible with augmentation strategies of arbitrary complexity for various mainstream CL methods and model frameworks. Experimental results demonstrate that CLeVER effectively extracts and incorporates equivariant information from data, thereby improving the training efficiency and robustness of baseline models in downstream tasks.