 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination-Aware Diffusion Sampling for Inverse Problems via Robust Prior Updates
Jun 01, 2026Diffusion-based inverse problem solvers can produce realistic reconstructions, but realism alone does not ensure that the recovered details are supported by the measurement. We study this failure as measurement-conditioned hallucination: visually meaningful content that is either implausible or inconsistent with the measured instance. Our analysis separates Bayes-rule-based diffusion inverse solvers into a prior update and a measurement-conditioning step, showing that hallucinated content can enter through the prior-side proposal before the measurement correction is applied. Motivated by this view, we propose Robust Prior Update (RPU), a solver-level module that probes the local stability of the diffusion prior update, re-anchors the resulting displacement at the current iterate, and leaves the measurement update unchanged. We instantiate RPU in DPS and evaluate it on FFHQ and ImageNet inverse problems using automatic metrics and human faithfulness studies. On FFHQ, RPU improves PSNR and LPIPS over DPS across box inpainting, Gaussian deblurring, and motion deblurring. In human judgments, RPU receives 91.9% of blind non-tie majority preferences and 91.1% of ground-truth-assisted non-tie preferences on FFHQ box inpainting, while the ImageNet Gaussian reader study is tie-heavy but favors RPU among non-tie cases. These results support a targeted claim: robustifying the prior update can improve instance faithfulness in diffusion inverse solvers, especially when the prior shapes weakly constrained content.
Measurement Geometry and Design for Trustworthy Generative Inverse Problems
Jun 01, 2026Generative models are increasingly used as priors for inverse problems, but their ability to produce realistic images creates a basic trust problem: a plausible reconstruction may be supported by the measurements, or it may be filled in by the prior along unobserved directions. This distinction is especially important in medical imaging, where acquisition operators are designed under scan-time, dose, and calibration constraints. We study generative inverse problems from a measurement-geometry perspective. The central question is whether a fixed measurement operator can distinguish nearby images that are plausible under the generative prior, and whether this relationship can guide better measurements. We introduce a local measurement-manifold compatibility measure that quantifies how well the operator observes prior-relevant tangent directions. Under local regularity assumptions, we prove that this quantity controls the stable part of the reconstruction error, while the generative prior controls off-manifold drift. This worst-direction certificate motivates practical fixed and sequential acquisition rules based on overall local volume preservation, including a posterior-cloud design that adapts measurements at test time without training a sampling policy. Across row-sampling, tomographic, and MR acquisition settings, the proposed scores predict failure modes, explain measurement-induced hallucinations, and guide better sampling. In fastMRI Cartesian sampling, posterior-cloud measurement design improves over strong non-learned ACS-preserving baselines, including variable-density and Poisson-like masks.
World Models: A Comprehensive Survey of Architectures, Methodologies, Reasoning Paradigms, and Applications
May 28, 2026World models, internal simulators that learn the structure and dynamics of an environment, have emerged as a central paradigm in the pursuit of artificial general intelligence, enabling agents to predict, plan, and reason within learned representations. Despite rapid progress across reinforcement learning, robotics, autonomous driving, and video generation, the field lacks a unified framework integrating its diverse architectural choices, training methods, reasoning mechanisms, and application settings. This survey addresses that gap with a multi-axis taxonomy organized along four dimensions: (i) architecture, encompassing representation format, dynamics formulation, input modality, learning paradigm, and downstream application; (ii) methodological family, including state-space and recurrent approaches, transformer-based models, diffusion-based generators, physics-informed networks, and language-augmented multimodal systems; (iii) reasoning strategy, covering imagination-based planning, latent policy learning, counterfactual reasoning, and planning under uncertainty; and (iv) application domain, spanning robotics, autonomous driving, video prediction, multimodal agents, reinforcement learning, scientific modeling, medical imaging, educational measurement, and business and finance. Tracing the field from early cognitive-science foundations to milestone systems such as PlaNet, the Dreamer family, MuZero, Sora, Cosmos, and Genie, we examine how these dimensions interact and highlight the recent convergence of chain-of-thought reasoning with world-model imagination. We review evaluation protocols and benchmarks, identify persistent challenges such as compounding prediction errors, sim-to-real transfer, and fragmented evaluation, and outline future directions toward unified multimodal world models, foundation-scale interactive simulators, and safe deployment in safety-critical domains.
LiFT: Lifted Inter-slice Feature Trajectories for 3D Image Generation from 2D Generators
May 18, 2026High-resolution 3D medical image generation remains challenging because fully volumetric models are computationally expensive, while efficient 2D slice generators often fail to preserve anatomical consistency across the third dimension. We propose LiFT, a framework for Lifted inter-slice Feature Trajectories that factorizes 3D volume synthesis into per-slice image generation and inter-slice trajectory learning. Rather than modeling the volumetric distribution end-to-end, LiFT treats a volume as an ordered trajectory in feature space, capturing how anatomical structures appear, transform, and disappear across depth. A tri-planar drifting loss aligns the trajectory of generated slices with the trajectories of real volumes, enabling distributional learning over inter-slice progressions in unconditional generation; in paired translation, a bidirectional $z$-context mixer trained against the registered target supplies through-plane coherence while preserving per-slice fidelity. We evaluate LiFT on BraTS 2023 (unconditional and missing-modality MR) and SynthRAD2023 (MR-to-CT). Across these settings, LiFT preserves per-slice quality, approaches the reported cWDM missing-MR reconstruction quality at $\sim$$135\times$ lower inference cost (without formal equivalence testing), and improves through-plane coherence on MR-to-CT relative to a no-mapper ablation, demonstrating that lightweight inter-slice trajectory learning is a viable route to high-resolution 3D medical synthesis.
DuetFair: Coupling Inter- and Intra-Subgroup Robustness for Fair Medical Image Segmentation
May 11, 2026Medical image segmentation models can perform unevenly across subgroups. Most existing fairness methods focus on improving average subgroup performance, implicitly treating each subgroup as internally homogeneous. However, this can hide difficult cases within a subgroup, where high-loss samples are obscured by the subgroup mean. We call this problem \textbf{intra-group hidden failure}. To solve this, we propose \textbf{DuetFair} mechanism, a dual-axis fairness framework that jointly considers inter-subgroup adaptation and intra-subgroup robustness. Based on DuetFair, we introduce \textbf{FairDRO}, which combines distribution-aware mixture-of-experts (dMoE) with subgroup-conditioned distributionally robust optimization (DRO) loss aggregation. This design allows the model to adapt across subgroups while also reducing hidden failures within each subgroup. We evaluate FairDRO on three medical image segmentation benchmarks with varying degrees of within-group heterogeneity. FairDRO achieves the best equity-scaled performance on Harvard-FairSeg and improves worst-case subgroup performance on HAM10000 under both age- and race-based grouping schemes. On the 3D radiotherapy target cohort, FairDRO further improves worst-group Dice by 3.5 points ($\uparrow 6.0\%$) under the tumor-stage grouping and by 4.1 points ($\uparrow 7.4\%$) under the institution grouping over the strongest baseline.
Local Intrinsic Dimension Unveils Hallucinations in Diffusion Models
May 06, 2026Diffusion models are prone to generating structural hallucinations - samples that match the statistical properties of the training data yet defy underlying structural rules, resulting in anomalies like hands with more than five fingers. Recent research studied this failure mode from several viewpoints, offering partial explanations to their occurrence, such as mode interpolation. In this work, we propose a complementary perspective that treats hallucinations as instabilities on the model-induced manifold. We begin by showing that a hallucination filter based on such instabilities matches or exceeds the performance of the recently proposed temporal one. By tracing the source of these instabilities, we identify local intrinsic dimension (LID) as their primary driver and propose Intrinsic Quenching (IQ), a direct corrective mechanism that deflates it to alleviate hallucinations. IQ consistently outperforms standard hallucination reduction baselines across a wide array of benchmarks and offers a highly promising solution for enforcing anatomical consistency in downstream medical imaging tasks.
MAPLE: Elevating Medical Reasoning from Statistical Consensus to Process-Led Alignment
Mar 09, 2026Recent advances in medical large language models have explored Test-Time Reinforcement Learning (TTRL) to enhance reasoning. However, standard TTRL often relies on majority voting (MV) as a heuristic supervision signal, which can be unreliable in complex medical scenarios where the most frequent reasoning path is not necessarily the clinically correct one. In this work, we propose a novel and unified training paradigm that integrates medical process reward models with TTRL to bridge the gap between test-time scaling (TTS) and parametric model optimization. Specifically, we advance the TTRL framework by replacing the conventional MV with a fine-grained, expert-aligned supervision paradigm using Med-RPM. This integration ensures that reinforcement learning is guided by medical correctness rather than mere consensus, effectively distilling search-based intelligence into the model's parametric memory. Extensive evaluations on four different benchmarks have demonstrated that our developed method consistently and significantly outperforms current TTRL and standalone PRM selection. Our findings establish that transitioning from stochastic heuristics to structured, step-wise rewards is essential for developing reliable and scalable medical AI systems
LiveMedBench: A Contamination-Free Medical Benchmark for LLMs with Automated Rubric Evaluation
Feb 10, 2026The deployment of Large Language Models (LLMs) in high-stakes clinical settings demands rigorous and reliable evaluation. However, existing medical benchmarks remain static, suffering from two critical limitations: (1) data contamination, where test sets inadvertently leak into training corpora, leading to inflated performance estimates; and (2) temporal misalignment, failing to capture the rapid evolution of medical knowledge. Furthermore, current evaluation metrics for open-ended clinical reasoning often rely on either shallow lexical overlap (e.g., ROUGE) or subjective LLM-as-a-Judge scoring, both inadequate for verifying clinical correctness. To bridge these gaps, we introduce LiveMedBench, a continuously updated, contamination-free, and rubric-based benchmark that weekly harvests real-world clinical cases from online medical communities, ensuring strict temporal separation from model training data. We propose a Multi-Agent Clinical Curation Framework that filters raw data noise and validates clinical integrity against evidence-based medical principles. For evaluation, we develop an Automated Rubric-based Evaluation Framework that decomposes physician responses into granular, case-specific criteria, achieving substantially stronger alignment with expert physicians than LLM-as-a-Judge. To date, LiveMedBench comprises 2,756 real-world cases spanning 38 medical specialties and multiple languages, paired with 16,702 unique evaluation criteria. Extensive evaluation of 38 LLMs reveals that even the best-performing model achieves only 39.2%, and 84% of models exhibit performance degradation on post-cutoff cases, confirming pervasive data contamination risks. Error analysis further identifies contextual application-not factual knowledge-as the dominant bottleneck, with 35-48% of failures stemming from the inability to tailor medical knowledge to patient-specific constraints.
CoMMa: Contribution-Aware Medical Multi-Agents From A Game-Theoretic Perspective
Feb 09, 2026Recent multi-agent frameworks have broadened the ability to tackle oncology decision support tasks that require reasoning over dynamic, heterogeneous patient data. We propose Contribution-Aware Medical Multi-Agents (CoMMa), a decentralized LLM-agent framework in which specialists operate on partitioned evidence and coordinate through a game-theoretic objective for robust decision-making. In contrast to most agent architectures relying on stochastic narrative-based reasoning, CoMMa utilizes deterministic embedding projections to approximate contribution-aware credit assignment. This yields explicit evidence attribution by estimating each agent's marginal utility, producing interpretable and mathematically grounded decision pathways with improved stability. Evaluated on diverse oncology benchmarks, including a real-world multidisciplinary tumor board dataset, CoMMa achieves higher accuracy and more stable performance than data-centralized and role-based multi-agents baselines.
Adaptation of Agentic AI
Dec 22, 2025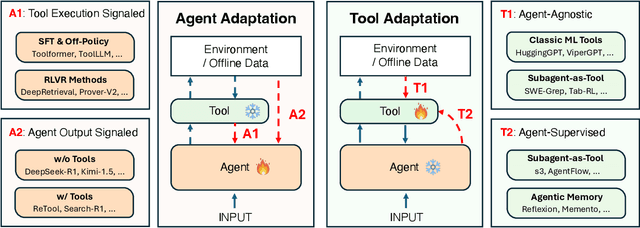
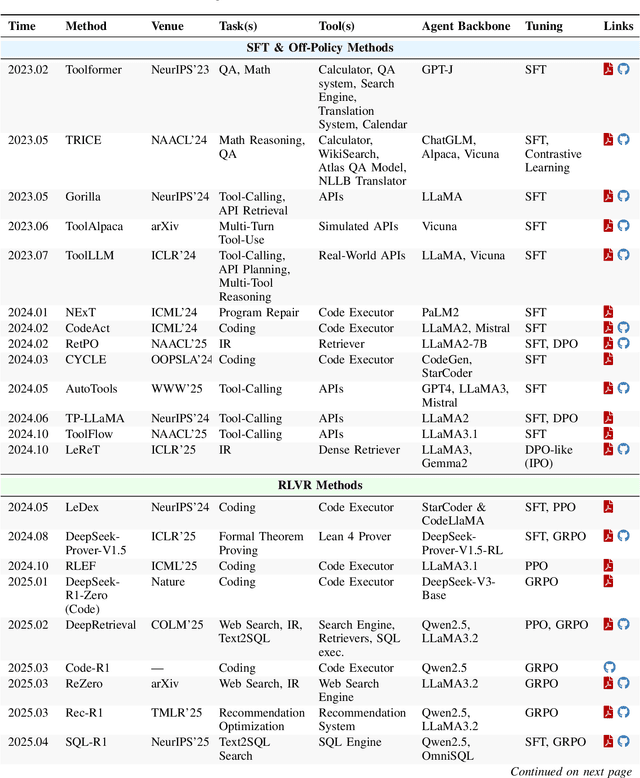
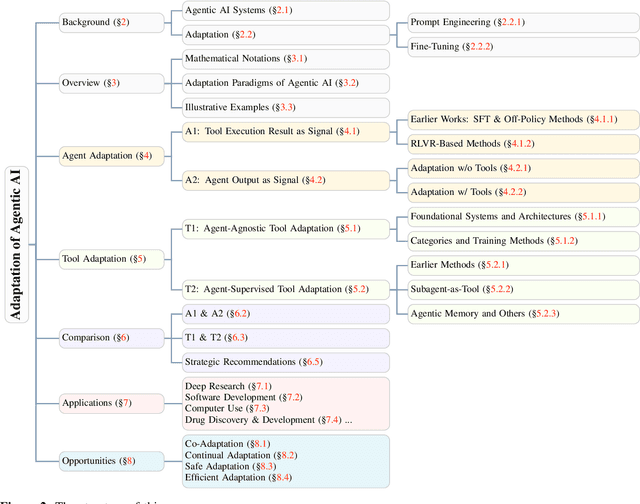
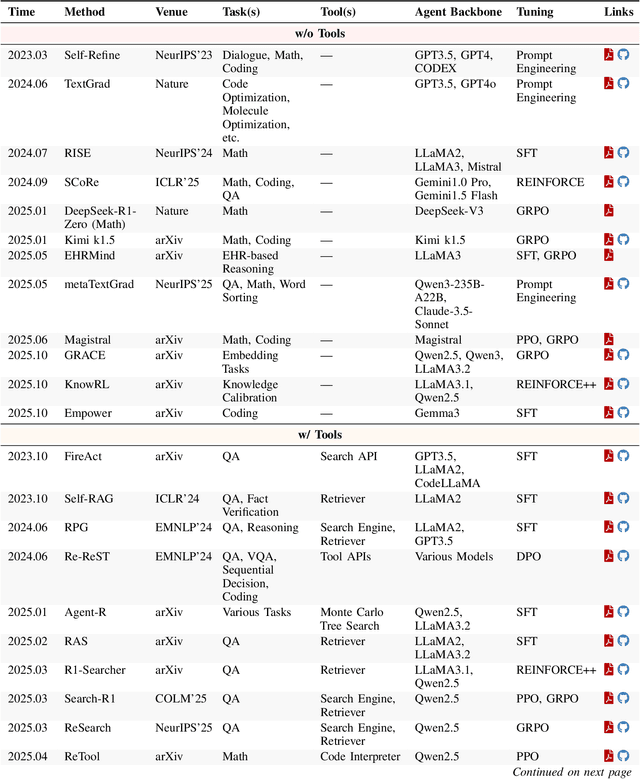
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.