 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECADE: A Temporally-Consistent Unsupervised Diffusion Model for Enhanced Rb-82 Dynamic Cardiac PET Image Denoising
Mar 08, 2026Rb-82 dynamic cardiac PET imaging is widely used for the clinical diagnosis of coronary artery disease (CAD), but its short half-life results in high noise levels that degrade dynamic frame quality and parametric imaging. The lack of paired clean-noisy training data, rapid tracer kinetics, and frame-dependent noise variations further limit the effectiveness of existing deep learning denoising methods. We propose DECADE (A Temporally-Consistent Unsupervised Diffusion model for Enhanced Rb-82 CArdiac PET DEnoising), an unsupervised diffusion framework that generalizes across early- to late-phase dynamic frames. DECADE incorporates temporal consistency during both training and iterative sampling, using noisy frames as guidance to preserve quantitative accuracy. The method was trained and evaluated on datasets acquired from Siemens Vision 450 and Siemens Biograph Vision Quadra scanners. On the Vision 450 dataset, DECADE consistently produced high-quality dynamic and parametric images with reduced noise while preserving myocardial blood flow (MBF) and myocardial flow reserve (MFR). On the Quadra dataset, using 15%-count images as input and full-count images as reference, DECADE outperformed UNet-based and other diffusion models in image quality and K1/MBF quantification. The proposed framework enables effective unsupervised denoising of Rb-82 dynamic cardiac PET without paired training data, supporting clearer visualization while maintaining quantitative integrity.
LangMamba: A Language-driven Mamba Framework for Low-dose CT Denoising with Vision-language Models
Jul 08, 2025Low-dose computed tomography (LDCT) reduces radiation exposure but often degrades image quality, potentially compromising diagnostic accuracy. Existing deep learning-based denoising methods focus primarily on pixel-level mappings, overlooking the potential benefits of high-level semantic guidance. Recent advances in vision-language models (VLMs) suggest that language can serve as a powerful tool for capturing structured semantic information, offering new opportunities to improve LDCT reconstruction. In this paper, we introduce LangMamba, a Language-driven Mamba framework for LDCT denoising that leverages VLM-derived representations to enhance supervision from normal-dose CT (NDCT). LangMamba follows a two-stage learning strategy. First, we pre-train a Language-guided AutoEncoder (LangAE) that leverages frozen VLMs to map NDCT images into a semantic space enriched with anatomical information. Second, we synergize LangAE with two key components to guide LDCT denoising: Semantic-Enhanced Efficient Denoiser (SEED), which enhances NDCT-relevant local semantic while capturing global features with efficient Mamba mechanism, and Language-engaged Dual-space Alignment (LangDA) Loss, which ensures that denoised images align with NDCT in both perceptual and semantic spaces. Extensive experiments on two public datasets demonstrate that LangMamba outperforms conventional state-of-the-art methods, significantly improving detail preservation and visual fidelity. Remarkably, LangAE exhibits strong generalizability to unseen datasets, thereby reducing training costs. Furthermore, LangDA loss improves explainability by integrating language-guided insights into image reconstruction and offers a plug-and-play fashion. Our findings shed new light on the potential of language as a supervisory signal to advance LDCT denoising. The code is publicly available on https://github.com/hao1635/LangMamba.
Fed-NDIF: A Noise-Embedded Federated Diffusion Model For Low-Count Whole-Body PET Denoising
Mar 20, 2025



Low-count positron emission tomography (LCPET) imaging can reduce patients' exposure to radiation but often suffers from increased image noise and reduced lesion detectability, necessitating effective denoising techniques. Diffusion models have shown promise in LCPET denoising for recovering degraded image quality. However, training such models requires large and diverse datasets, which are challenging to obtain in the medical domain. To address data scarcity and privacy concerns, we combine diffusion models with federated learning -- a decentralized training approach where models are trained individually at different sites, and their parameters are aggregated on a central server over multiple iterations. The variation in scanner types and image noise levels within and across institutions poses additional challenges for federated learning in LCPET denoising. In this study, we propose a novel noise-embedded federated learning diffusion model (Fed-NDIF) to address these challenges, leveraging a multicenter dataset and varying count levels. Our approach incorporates liver normalized standard deviation (NSTD) noise embedding into a 2.5D diffusion model and utilizes the Federated Averaging (FedAvg) algorithm to aggregate locally trained models into a global model, which is subsequently fine-tuned on local datasets to optimize performance and obtain personalized models. Extensive validation on datasets from the University of Bern, Ruijin Hospital in Shanghai, and Yale-New Haven Hospital demonstrates the superior performance of our method in enhancing image quality and improving lesion quantification. The Fed-NDIF model shows significant improvements in PSNR, SSIM, and NMSE of the entire 3D volume, as well as enhanced lesion detectability and quantification, compared to local diffusion models and federated UNet-based models.
Anatomically and Metabolically Informed Diffusion for Unified Denoising and Segmentation in Low-Count PET Imaging
Mar 17, 2025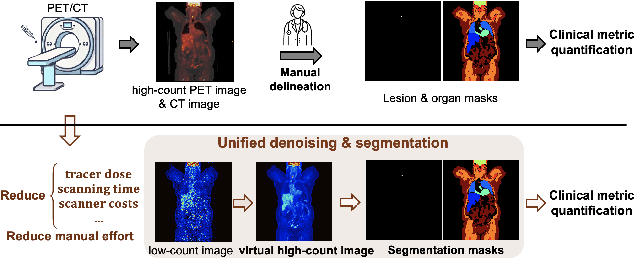
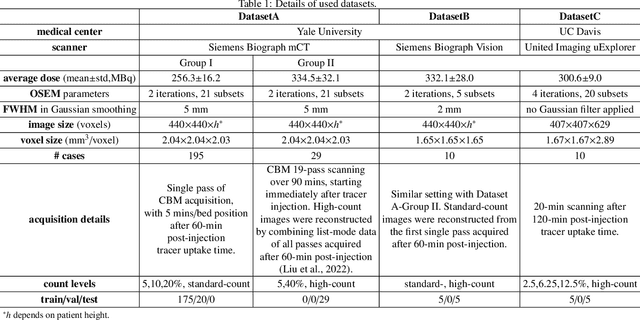
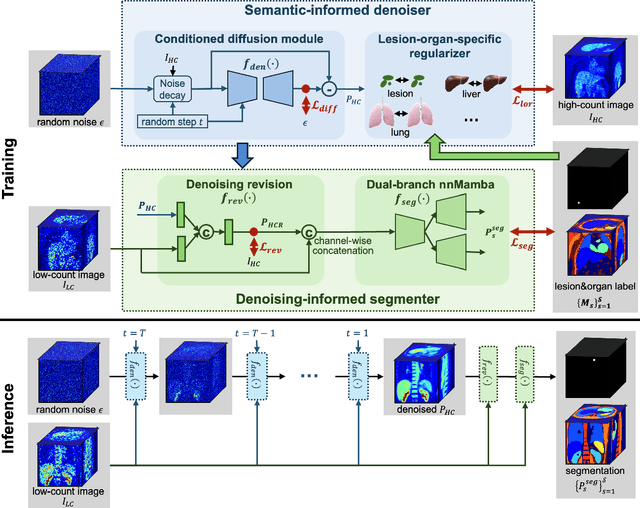
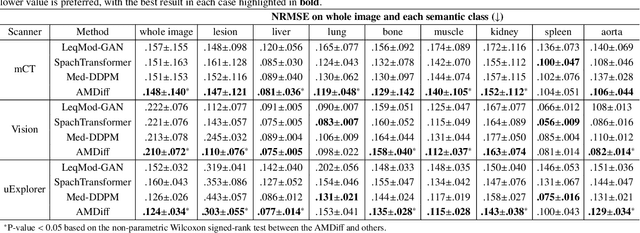
Positron emission tomography (PET) image denoising, along with lesion and organ segmentation, are critical steps in PET-aided diagnosis. However, existing methods typically treat these tasks independently, overlooking inherent synergies between them as correlated steps in the analysis pipeline. In this work, we present the anatomically and metabolically informed diffusion (AMDiff) model, a unified framework for denoising and lesion/organ segmentation in low-count PET imaging. By integrating multi-task functionality and exploiting the mutual benefits of these tasks, AMDiff enables direct quantification of clinical metrics, such as total lesion glycolysis (TLG), from low-count inputs. The AMDiff model incorporates a semantic-informed denoiser based on diffusion strategy and a denoising-informed segmenter utilizing nnMamba architecture. The segmenter constrains denoised outputs via a lesion-organ-specific regularizer, while the denoiser enhances the segmenter by providing enriched image information through a denoising revision module. These components are connected via a warming-up mechanism to optimize multitask interactions. Experiments on multi-vendor, multi-center, and multi-noise-level datasets demonstrate the superior performance of AMDiff. For test cases below 20% of the clinical count levels from participating sites, AMDiff achieves TLG quantification biases of -26.98%, outperforming its ablated versions which yield biases of -35.85% (without the lesion-organ-specific regularizer) and -40.79% (without the denoising revision module).
A Generalizable 3D Diffusion Framework for Low-Dose and Few-View Cardiac SPECT
Dec 21, 2024Myocardial perfusion imaging using SPECT is widely utilized to diagnose coronary artery diseases, but image quality can be negatively affected in low-dose and few-view acquisition settings. Although various deep learning methods have been introduced to improve image quality from low-dose or few-view SPECT data, previous approaches often fail to generalize across different acquisition settings, limiting their applicability in reality. This work introduced DiffSPECT-3D, a diffusion framework for 3D cardiac SPECT imaging that effectively adapts to different acquisition settings without requiring further network re-training or fine-tuning. Using both image and projection data, a consistency strategy is proposed to ensure that diffusion sampling at each step aligns with the low-dose/few-view projection measurements, the image data, and the scanner geometry, thus enabling generalization to different low-dose/few-view settings. Incorporating anatomical spatial information from CT and total variation constraint, we proposed a 2.5D conditional strategy to allow the DiffSPECT-3D to observe 3D contextual information from the entire image volume, addressing the 3D memory issues in diffusion model. We extensively evaluated the proposed method on 1,325 clinical 99mTc tetrofosmin stress/rest studies from 795 patients. Each study was reconstructed into 5 different low-count and 5 different few-view levels for model evaluations, ranging from 1% to 50% and from 1 view to 9 view, respectively. Validated against cardiac catheterization results and diagnostic comments from nuclear cardiologists, the presented results show the potential to achieve low-dose and few-view SPECT imaging without compromising clinical performance. Additionally, DiffSPECT-3D could be directly applied to full-dose SPECT images to further improve image quality, especially in a low-dose stress-first cardiac SPECT imaging protocol.
Noise-aware Dynamic Image Denoising and Positron Range Correction for Rubidium-82 Cardiac PET Imaging via Self-supervision
Sep 17, 2024



Rb-82 is a radioactive isotope widely used for cardiac PET imaging. Despite numerous benefits of 82-Rb, there are several factors that limits its image quality and quantitative accuracy. First, the short half-life of 82-Rb results in noisy dynamic frames. Low signal-to-noise ratio would result in inaccurate and biased image quantification. Noisy dynamic frames also lead to highly noisy parametric images. The noise levels also vary substantially in different dynamic frames due to radiotracer decay and short half-life. Existing denoising methods are not applicable for this task due to the lack of paired training inputs/labels and inability to generalize across varying noise levels. Second, 82-Rb emits high-energy positrons. Compared with other tracers such as 18-F, 82-Rb travels a longer distance before annihilation, which negatively affect image spatial resolution. Here, the goal of this study is to propose a self-supervised method for simultaneous (1) noise-aware dynamic image denoising and (2) positron range correction for 82-Rb cardiac PET imaging. Tested on a series of PET scans from a cohort of normal volunteers, the proposed method produced images with superior visual quality. To demonstrate the improvement in image quantification, we compared image-derived input functions (IDIFs) with arterial input functions (AIFs) from continuous arterial blood samples. The IDIF derived from the proposed method led to lower AUC differences, decreasing from 11.09% to 7.58% on average, compared to the original dynamic frames. The proposed method also improved the quantification of myocardium blood flow (MBF), as validated against 15-O-water scans, with mean MBF differences decreased from 0.43 to 0.09, compared to the original dynamic frames. We also conducted a generalizability experiment on 37 patient scans obtained from a different country using a different scanner.
2.5D Multi-view Averaging Diffusion Model for 3D Medical Image Translation: Application to Low-count PET Reconstruction with CT-less Attenuation Correction
Jun 12, 2024


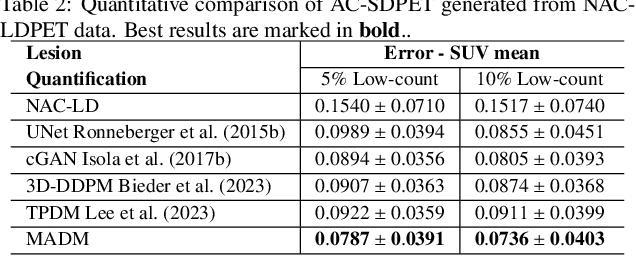
Positron Emission Tomography (PET) is an important clinical imaging tool but inevitably introduces radiation hazards to patients and healthcare providers. Reducing the tracer injection dose and eliminating the CT acquisition for attenuation correction can reduce the overall radiation dose, but often results in PET with high noise and bias. Thus, it is desirable to develop 3D methods to translate the non-attenuation-corrected low-dose PET (NAC-LDPET) into attenuation-corrected standard-dose PET (AC-SDPET). Recently, diffusion models have emerged as a new state-of-the-art deep learning method for image-to-image translation, better than traditional CNN-based methods. However, due to the high computation cost and memory burden, it is largely limited to 2D applications. To address these challenges, we developed a novel 2.5D Multi-view Averaging Diffusion Model (MADM) for 3D image-to-image translation with application on NAC-LDPET to AC-SDPET translation. Specifically, MADM employs separate diffusion models for axial, coronal, and sagittal views, whose outputs are averaged in each sampling step to ensure the 3D generation quality from multiple views. To accelerate the 3D sampling process, we also proposed a strategy to use the CNN-based 3D generation as a prior for the diffusion model. Our experimental results on human patient studies suggested that MADM can generate high-quality 3D translation images, outperforming previous CNN-based and Diffusion-based baseline methods.
LpQcM: Adaptable Lesion-Quantification-Consistent Modulation for Deep Learning Low-Count PET Image Denoising
Apr 27, 2024
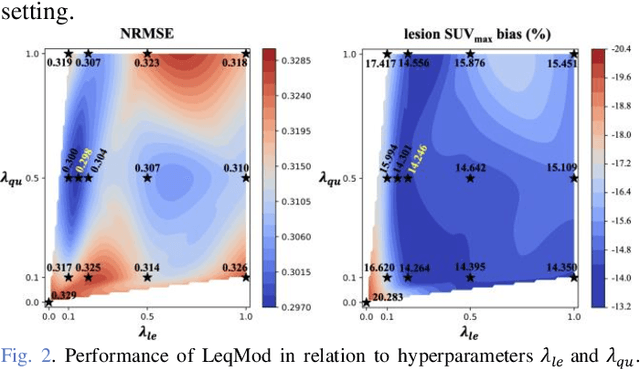


Deep learning-based positron emission tomography (PET) image denoising offers the potential to reduce radiation exposure and scanning time by transforming low-count images into high-count equivalents. However, existing methods typically blur crucial details, leading to inaccurate lesion quantification. This paper proposes a lesion-perceived and quantification-consistent modulation (LpQcM) strategy for enhanced PET image denoising, via employing downstream lesion quantification analysis as auxiliary tools. The LpQcM is a plug-and-play design adaptable to a wide range of model architectures, modulating the sampling and optimization procedures of model training without adding any computational burden to the inference phase. Specifically, the LpQcM consists of two components, the lesion-perceived modulation (LpM) and the multiscale quantification-consistent modulation (QcM). The LpM enhances lesion contrast and visibility by allocating higher sampling weights and stricter loss criteria to lesion-present samples determined by an auxiliary segmentation network than lesion-absent ones. The QcM further emphasizes accuracy of quantification for both the mean and maximum standardized uptake value (SUVmean and SUVmax) across multiscale sub-regions throughout the entire image, thereby enhancing the overall image quality. Experiments conducted on large PET datasets from multiple centers and vendors, and varying noise levels demonstrated the LpQcM efficacy across various denoising frameworks. Compared to frameworks without LpQcM, the integration of LpQcM reduces the lesion SUVmean bias by 2.92% on average and increases the peak signal-to-noise ratio (PSNR) by 0.34 on average, for denoising images of extremely low-count levels below 10%.
Pseudo-MRI-Guided PET Image Reconstruction Method Based on a Diffusion Probabilistic Model
Mar 26, 2024



Anatomically guided PET reconstruction using MRI information has been shown to have the potential to improve PET image quality. However, these improvements are limited to PET scans with paired MRI information. In this work we employed a diffusion probabilistic model (DPM) to infer T1-weighted-MRI (deep-MRI) images from FDG-PET brain images. We then use the DPM-generated T1w-MRI to guide the PET reconstruction. The model was trained with brain FDG scans, and tested in datasets containing multiple levels of counts. Deep-MRI images appeared somewhat degraded than the acquired MRI images. Regarding PET image quality, volume of interest analysis in different brain regions showed that both PET reconstructed images using the acquired and the deep-MRI images improved image quality compared to OSEM. Same conclusions were found analysing the decimated datasets. A subjective evaluation performed by two physicians confirmed that OSEM scored consistently worse than the MRI-guided PET images and no significant differences were observed between the MRI-guided PET images. This proof of concept shows that it is possible to infer DPM-based MRI imagery to guide the PET reconstruction, enabling the possibility of changing reconstruction parameters such as the strength of the prior on anatomically guided PET reconstruction in the absence of MRI.
TAI-GAN: A Temporally and Anatomically Informed Generative Adversarial Network for early-to-late frame conversion in dynamic cardiac PET inter-frame motion correction
Feb 14, 2024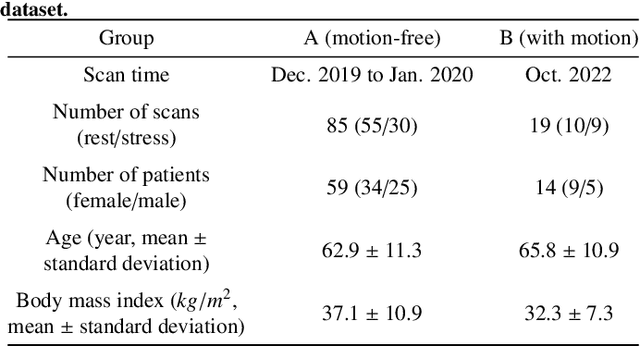
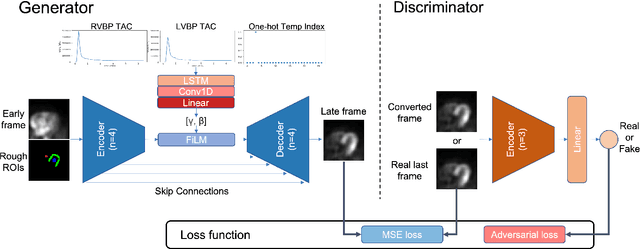
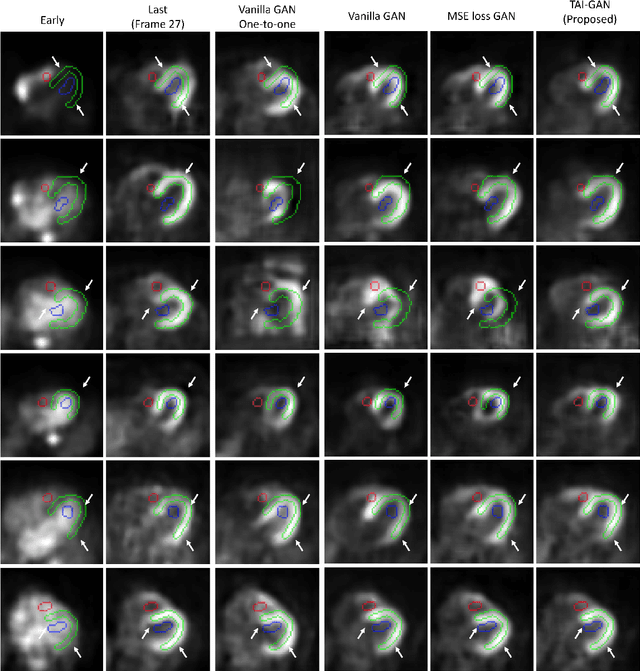
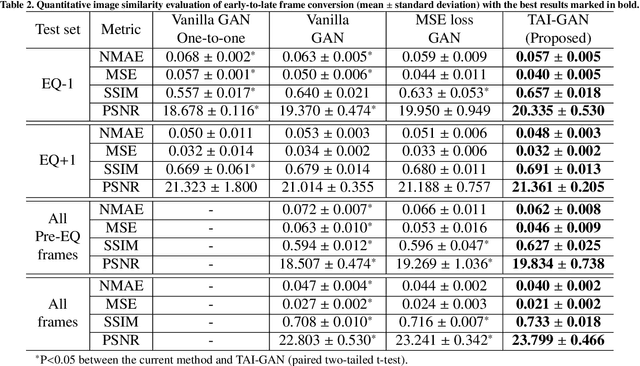
Inter-frame motion in dynamic cardiac positron emission tomography (PET) using rubidium-82 (82-Rb) myocardial perfusion imaging impacts myocardial blood flow (MBF) quantification and the diagnosis accuracy of coronary artery diseases. However, the high cross-frame distribution variation due to rapid tracer kinetics poses a considerable challenge for inter-frame motion correction, especially for early frames where intensity-based image registration techniques often fail. To address this issue, we propose a novel method called Temporally and Anatomically Informed Generative Adversarial Network (TAI-GAN) that utilizes an all-to-one mapping to convert early frames into those with tracer distribution similar to the last reference frame. The TAI-GAN consists of a feature-wise linear modulation layer that encodes channel-wise parameters generated from temporal information and rough cardiac segmentation masks with local shifts that serve as anatomical information. Our proposed method was evaluated on a clinical 82-Rb PET dataset, and the results show that our TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, the motion estimation accuracy and subsequent myocardial blood flow (MBF) quantification with both conventional and deep learning-based motion correction methods were improved compared to using the original frames.