 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVL: Unified Vision-Language Embedding for Spatially Grounded Contextual Image Generation
May 20, 2026We introduce spatially grounded contextual image generation, a controllable image generation task that reframes the conditioning paradigm. Instead of supplying a reference image and a global text prompt through two separate encoders, one for vision and one for language, UniVL is trained to bind semantics to spatial locations directly from a single unified visual input, where the textual instruction is rendered onto the spatial mask. This removes the need for a standalone text encoder at inference time. The resulting model supports contextual image generation by following user-specified instructions about what should appear where, while substantially reducing computation. To address this task, we propose a framework in which the UniVL encoder, adapted from an optical-character-recognition-pretrained backbone, reads the unified condition optically and produces a UniVL embedding, fVIL, that fuses visual and semantic intent with spatial locations in a single token sequence. A two-stage pipeline first aligns UniVL with the VAE embedding space and then conditions a pretrained diffusion backbone entirely on UniVL embeddings, eliminating the standalone text encoder, such as T5. Although this reframing uses a deliberately minimal text interface, it yields strong empirical gains. On UniVL-ImgGen, a benchmark of 477K mask-annotated images that we construct for training and evaluation, UniVL improves image quality over text-prompted baselines, reducing FID from 14 to 11 and increasing PSNR from 16 to 20. It also eliminates the text encoder entirely, reducing inference TFLOPs by up to 52% and runtime by up to 44%. Additional ablation studies validate the contributions of the proposed components, paving the way for efficient, spatially grounded image generation with a unified conditioning paradigm.
A Unified Framework for Multimodal Image Reconstruction and Synthesis using Denoising Diffusion Models
Feb 09, 2026Image reconstruction and image synthesis are important for handling incomplete multimodal imaging data, but existing methods require various task-specific models, complicating training and deployment workflows. We introduce Any2all, a unified framework that addresses this limitation by formulating these disparate tasks as a single virtual inpainting problem. We train a single, unconditional diffusion model on the complete multimodal data stack. This model is then adapted at inference time to ``inpaint'' all target modalities from any combination of inputs of available clean images or noisy measurements. We validated Any2all on a PET/MR/CT brain dataset. Our results show that Any2all can achieve excellent performance on both multimodal reconstruction and synthesis tasks, consistently yielding images with competitive distortion-based performance and superior perceptual quality over specialized methods.
Plug-and-Play Posterior Sampling for Blind Inverse Problems
May 28, 2025


We introduce Blind Plug-and-Play Diffusion Models (Blind-PnPDM) as a novel framework for solving blind inverse problems where both the target image and the measurement operator are unknown. Unlike conventional methods that rely on explicit priors or separate parameter estimation, our approach performs posterior sampling by recasting the problem into an alternating Gaussian denoising scheme. We leverage two diffusion models as learned priors: one to capture the distribution of the target image and another to characterize the parameters of the measurement operator. This PnP integration of diffusion models ensures flexibility and ease of adaptation. Our experiments on blind image deblurring show that Blind-PnPDM outperforms state-of-the-art methods in terms of both quantitative metrics and visual fidelity. Our results highlight the effectiveness of treating blind inverse problems as a sequence of denoising subproblems while harnessing the expressive power of diffusion-based priors.
A Self-supervised Diffusion Bridge for MRI Reconstruction
Jan 06, 2025

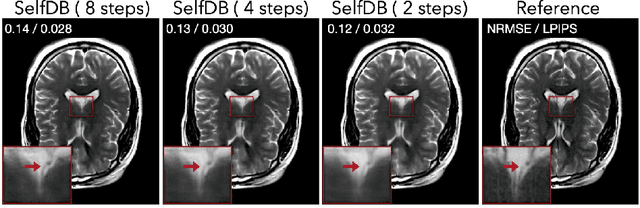

Diffusion bridges (DBs) are a class of diffusion models that enable faster sampling by interpolating between two paired image distributions. Training traditional DBs for image reconstruction requires high-quality reference images, which limits their applicability to settings where such references are unavailable. We propose SelfDB as a novel self-supervised method for training DBs directly on available noisy measurements without any high-quality reference images. SelfDB formulates the diffusion process by further sub-sampling the available measurements two additional times and training a neural network to reverse the corresponding degradation process by using the available measurements as the training targets. We validate SelfDB on compressed sensing MRI, showing its superior performance compared to the denoising diffusion models.
A Generalizable 3D Diffusion Framework for Low-Dose and Few-View Cardiac SPECT
Dec 21, 2024Myocardial perfusion imaging using SPECT is widely utilized to diagnose coronary artery diseases, but image quality can be negatively affected in low-dose and few-view acquisition settings. Although various deep learning methods have been introduced to improve image quality from low-dose or few-view SPECT data, previous approaches often fail to generalize across different acquisition settings, limiting their applicability in reality. This work introduced DiffSPECT-3D, a diffusion framework for 3D cardiac SPECT imaging that effectively adapts to different acquisition settings without requiring further network re-training or fine-tuning. Using both image and projection data, a consistency strategy is proposed to ensure that diffusion sampling at each step aligns with the low-dose/few-view projection measurements, the image data, and the scanner geometry, thus enabling generalization to different low-dose/few-view settings. Incorporating anatomical spatial information from CT and total variation constraint, we proposed a 2.5D conditional strategy to allow the DiffSPECT-3D to observe 3D contextual information from the entire image volume, addressing the 3D memory issues in diffusion model. We extensively evaluated the proposed method on 1,325 clinical 99mTc tetrofosmin stress/rest studies from 795 patients. Each study was reconstructed into 5 different low-count and 5 different few-view levels for model evaluations, ranging from 1% to 50% and from 1 view to 9 view, respectively. Validated against cardiac catheterization results and diagnostic comments from nuclear cardiologists, the presented results show the potential to achieve low-dose and few-view SPECT imaging without compromising clinical performance. Additionally, DiffSPECT-3D could be directly applied to full-dose SPECT images to further improve image quality, especially in a low-dose stress-first cardiac SPECT imaging protocol.
ADOBI: Adaptive Diffusion Bridge For Blind Inverse Problems with Application to MRI Reconstruction
Nov 25, 2024

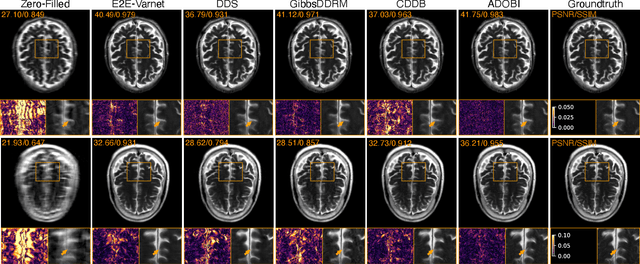

Diffusion bridges (DB) have emerged as a promising alternative to diffusion models for imaging inverse problems, achieving faster sampling by directly bridging low- and high-quality image distributions. While incorporating measurement consistency has been shown to improve performance, existing DB methods fail to maintain this consistency in blind inverse problems, where the forward model is unknown. To address this limitation, we introduce ADOBI (Adaptive Diffusion Bridge for Inverse Problems), a novel framework that adaptively calibrates the unknown forward model to enforce measurement consistency throughout sampling iterations. Our adaptation strategy allows ADOBI to achieve high-quality parallel magnetic resonance imaging (PMRI) reconstruction in only 5-10 steps. Our numerical results show that ADOBI consistently delivers state-of-the-art performance, and further advances the Pareto frontier for the perception-distortion trade-off.
Stochastic Deep Restoration Priors for Imaging Inverse Problems
Oct 02, 2024



Deep neural networks trained as image denoisers are widely used as priors for solving imaging inverse problems. While Gaussian denoising is thought sufficient for learning image priors, we show that priors from deep models pre-trained as more general restoration operators can perform better. We introduce Stochastic deep Restoration Priors (ShaRP), a novel method that leverages an ensemble of such restoration models to regularize inverse problems. ShaRP improves upon methods using Gaussian denoiser priors by better handling structured artifacts and enabling self-supervised training even without fully sampled data. We prove ShaRP minimizes an objective function involving a regularizer derived from the score functions of minimum mean square error (MMSE) restoration operators, and theoretically analyze its convergence. Empirically, ShaRP achieves state-of-the-art performance on tasks such as magnetic resonance imaging reconstruction and single-image super-resolution, surpassing both denoiser-and diffusion-model-based methods without requiring retraining.
Pseudo-MRI-Guided PET Image Reconstruction Method Based on a Diffusion Probabilistic Model
Mar 26, 2024



Anatomically guided PET reconstruction using MRI information has been shown to have the potential to improve PET image quality. However, these improvements are limited to PET scans with paired MRI information. In this work we employed a diffusion probabilistic model (DPM) to infer T1-weighted-MRI (deep-MRI) images from FDG-PET brain images. We then use the DPM-generated T1w-MRI to guide the PET reconstruction. The model was trained with brain FDG scans, and tested in datasets containing multiple levels of counts. Deep-MRI images appeared somewhat degraded than the acquired MRI images. Regarding PET image quality, volume of interest analysis in different brain regions showed that both PET reconstructed images using the acquired and the deep-MRI images improved image quality compared to OSEM. Same conclusions were found analysing the decimated datasets. A subjective evaluation performed by two physicians confirmed that OSEM scored consistently worse than the MRI-guided PET images and no significant differences were observed between the MRI-guided PET images. This proof of concept shows that it is possible to infer DPM-based MRI imagery to guide the PET reconstruction, enabling the possibility of changing reconstruction parameters such as the strength of the prior on anatomically guided PET reconstruction in the absence of MRI.
Convergence of Nonconvex PnP-ADMM with MMSE Denoisers
Nov 30, 2023Plug-and-Play Alternating Direction Method of Multipliers (PnP-ADMM) is a widely-used algorithm for solving inverse problems by integrating physical measurement models and convolutional neural network (CNN) priors. PnP-ADMM has been theoretically proven to converge for convex data-fidelity terms and nonexpansive CNNs. It has however been observed that PnP-ADMM often empirically converges even for expansive CNNs. This paper presents a theoretical explanation for the observed stability of PnP-ADMM based on the interpretation of the CNN prior as a minimum mean-squared error (MMSE) denoiser. Our explanation parallels a similar argument recently made for the iterative shrinkage/thresholding algorithm variant of PnP (PnP-ISTA) and relies on the connection between MMSE denoisers and proximal operators. We also numerically evaluate the performance gap between PnP-ADMM using a nonexpansive DnCNN denoiser and expansive DRUNet denoiser, thus motivating the use of expansive CNNs.
DiffGEPCI: 3D MRI Synthesis from mGRE Signals using 2.5D Diffusion Model
Nov 29, 2023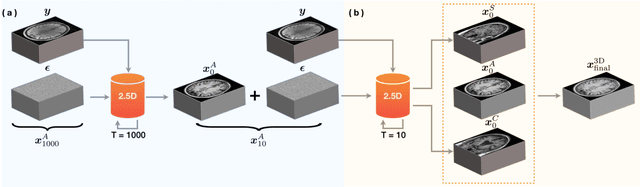
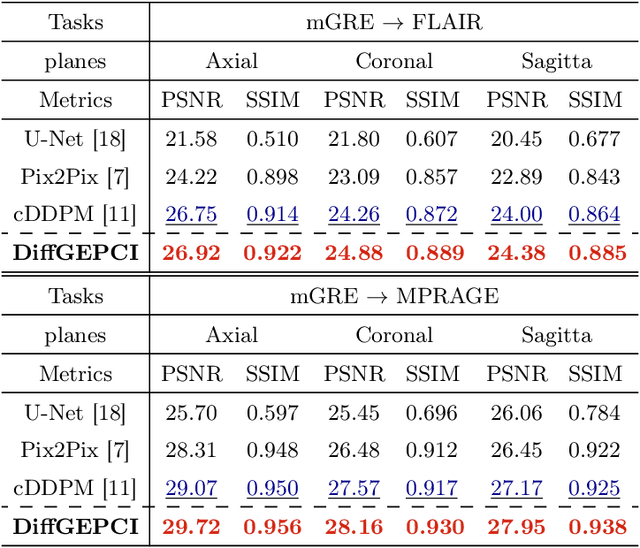
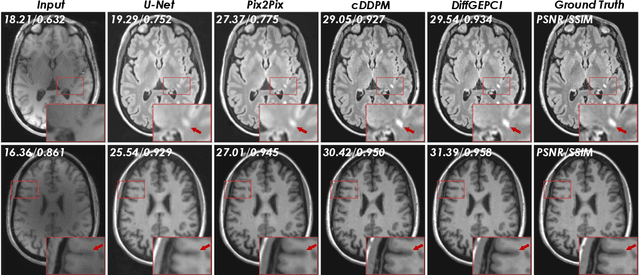
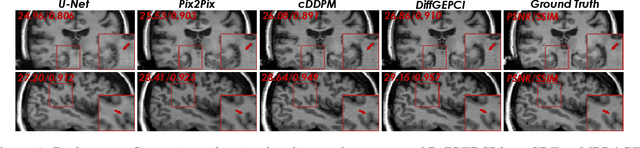
We introduce a new framework called DiffGEPCI for cross-modality generation in magnetic resonance imaging (MRI) using a 2.5D conditional diffusion model. DiffGEPCI can synthesize high-quality Fluid Attenuated Inversion Recovery (FLAIR) and Magnetization Prepared-Rapid Gradient Echo (MPRAGE) images, without acquiring corresponding measurements, by leveraging multi-Gradient-Recalled Echo (mGRE) MRI signals as conditional inputs. DiffGEPCI operates in a two-step fashion: it initially estimates a 3D volume slice-by-slice using the axial plane and subsequently applies a refinement algorithm (referred to as 2.5D) to enhance the quality of the coronal and sagittal planes. Experimental validation on real mGRE data shows that DiffGEPCI achieves excellent performance, surpassing generative adversarial networks (GANs) and traditional diffusion models.