 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-based neurodevelopmental assessment in preterm infants
Jan 17, 2026Preterm infants (born between 28 and 37 weeks of gestation) face elevated risks of neurodevelopmental delays, making early identification crucial for timely intervention. While deep learning-based volumetric segmentation of brain MRI scans offers a promising avenue for assessing neonatal neurodevelopment, achieving accurate segmentation of white matter (WM) and gray matter (GM) in preterm infants remains challenging due to their comparable signal intensities (isointense appearance) on MRI during early brain development. To address this, we propose a novel segmentation neural network, named Hierarchical Dense Attention Network. Our architecture incorporates a 3D spatial-channel attention mechanism combined with an attention-guided dense upsampling strategy to enhance feature discrimination in low-contrast volumetric data. Quantitative experiments demonstrate that our method achieves superior segmentation performance compared to state-of-the-art baselines, effectively tackling the challenge of isointense tissue differentiation. Furthermore, application of our algorithm confirms that WM and GM volumes in preterm infants are significantly lower than those in term infants, providing additional imaging evidence of the neurodevelopmental delays associated with preterm birth. The code is available at: https://github.com/ICL-SUST/HDAN.
Dual Attention Driven Lumbar Magnetic Resonance Image Feature Enhancement and Automatic Diagnosis of Herniation
Apr 28, 2025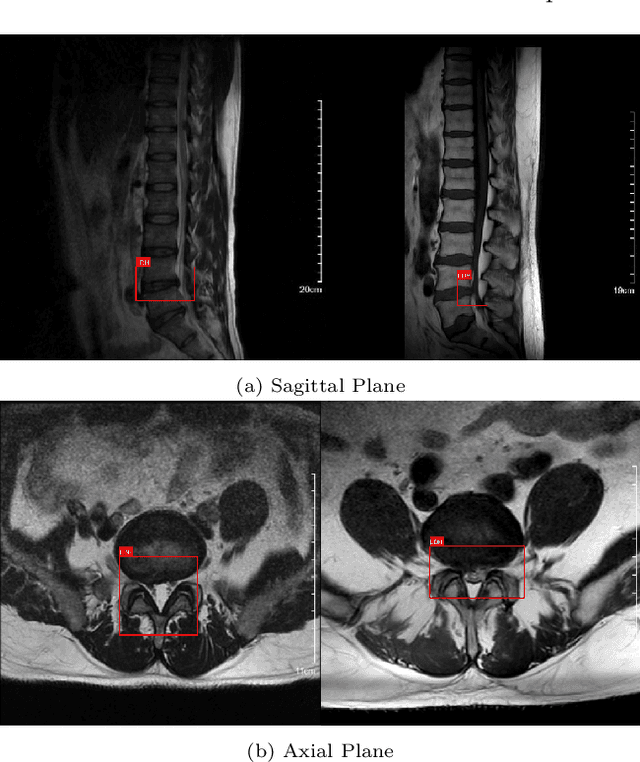
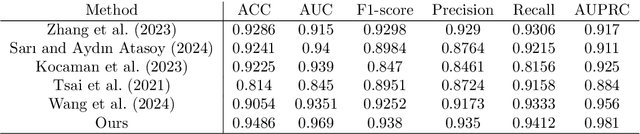
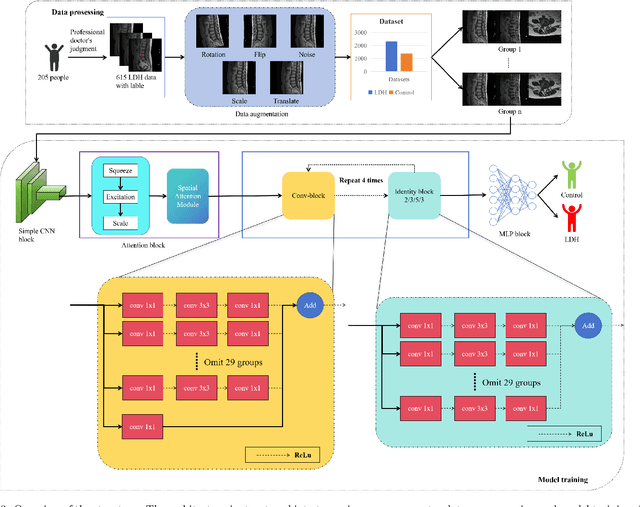
Lumbar disc herniation (LDH) is a common musculoskeletal disease that requires magnetic resonance imaging (MRI) for effective clinical management. However, the interpretation of MRI images heavily relies on the expertise of radiologists, leading to delayed diagnosis and high costs for training physicians. Therefore, this paper proposes an innovative automated LDH classification framework. To address these key issues, the framework utilizes T1-weighted and T2-weighted MRI images from 205 people. The framework extracts clinically actionable LDH features and generates standardized diagnostic outputs by leveraging data augmentation and channel and spatial attention mechanisms. These outputs can help physicians make confident and time-effective care decisions when needed. The proposed framework achieves an area under the receiver operating characteristic curve (AUC-ROC) of 0.969 and an accuracy of 0.9486 for LDH detection. The experimental results demonstrate the performance of the proposed framework. Our framework only requires a small number of datasets for training to demonstrate high diagnostic accuracy. This is expected to be a solution to enhance the LDH detection capabilities of primary hospitals.
Fed-NDIF: A Noise-Embedded Federated Diffusion Model For Low-Count Whole-Body PET Denoising
Mar 20, 2025



Low-count positron emission tomography (LCPET) imaging can reduce patients' exposure to radiation but often suffers from increased image noise and reduced lesion detectability, necessitating effective denoising techniques. Diffusion models have shown promise in LCPET denoising for recovering degraded image quality. However, training such models requires large and diverse datasets, which are challenging to obtain in the medical domain. To address data scarcity and privacy concerns, we combine diffusion models with federated learning -- a decentralized training approach where models are trained individually at different sites, and their parameters are aggregated on a central server over multiple iterations. The variation in scanner types and image noise levels within and across institutions poses additional challenges for federated learning in LCPET denoising. In this study, we propose a novel noise-embedded federated learning diffusion model (Fed-NDIF) to address these challenges, leveraging a multicenter dataset and varying count levels. Our approach incorporates liver normalized standard deviation (NSTD) noise embedding into a 2.5D diffusion model and utilizes the Federated Averaging (FedAvg) algorithm to aggregate locally trained models into a global model, which is subsequently fine-tuned on local datasets to optimize performance and obtain personalized models. Extensive validation on datasets from the University of Bern, Ruijin Hospital in Shanghai, and Yale-New Haven Hospital demonstrates the superior performance of our method in enhancing image quality and improving lesion quantification. The Fed-NDIF model shows significant improvements in PSNR, SSIM, and NMSE of the entire 3D volume, as well as enhanced lesion detectability and quantification, compared to local diffusion models and federated UNet-based models.
Anatomically and Metabolically Informed Diffusion for Unified Denoising and Segmentation in Low-Count PET Imaging
Mar 17, 2025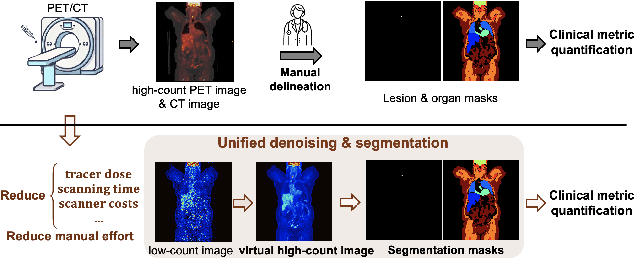
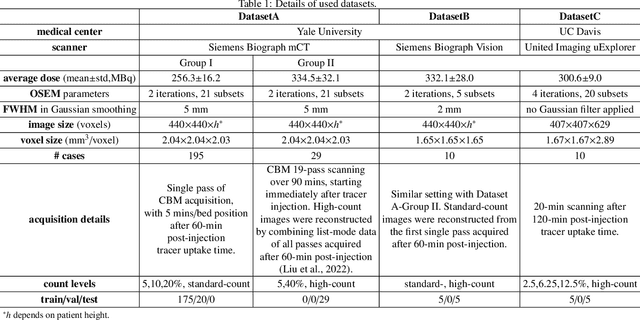
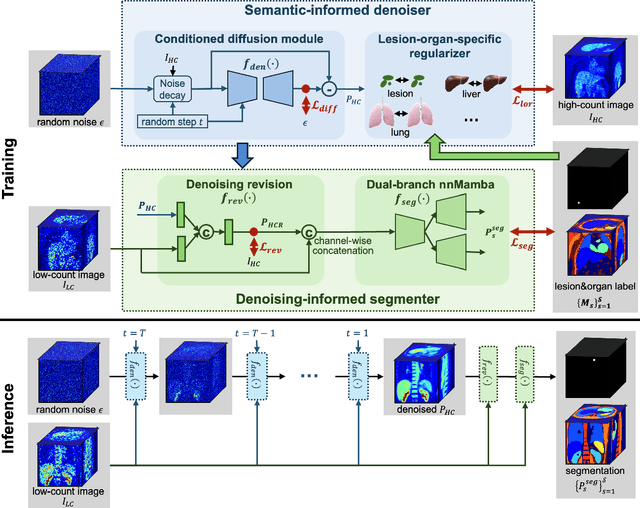
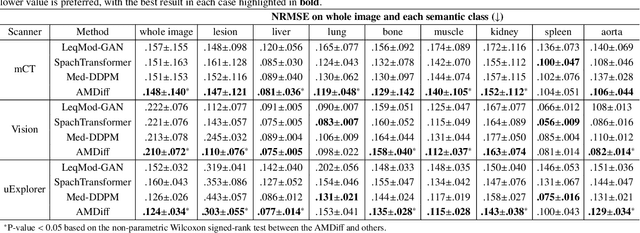
Positron emission tomography (PET) image denoising, along with lesion and organ segmentation, are critical steps in PET-aided diagnosis. However, existing methods typically treat these tasks independently, overlooking inherent synergies between them as correlated steps in the analysis pipeline. In this work, we present the anatomically and metabolically informed diffusion (AMDiff) model, a unified framework for denoising and lesion/organ segmentation in low-count PET imaging. By integrating multi-task functionality and exploiting the mutual benefits of these tasks, AMDiff enables direct quantification of clinical metrics, such as total lesion glycolysis (TLG), from low-count inputs. The AMDiff model incorporates a semantic-informed denoiser based on diffusion strategy and a denoising-informed segmenter utilizing nnMamba architecture. The segmenter constrains denoised outputs via a lesion-organ-specific regularizer, while the denoiser enhances the segmenter by providing enriched image information through a denoising revision module. These components are connected via a warming-up mechanism to optimize multitask interactions. Experiments on multi-vendor, multi-center, and multi-noise-level datasets demonstrate the superior performance of AMDiff. For test cases below 20% of the clinical count levels from participating sites, AMDiff achieves TLG quantification biases of -26.98%, outperforming its ablated versions which yield biases of -35.85% (without the lesion-organ-specific regularizer) and -40.79% (without the denoising revision module).
Derivative-Free Optimization via Finite Difference Approximation: An Experimental Study
Oct 31, 2024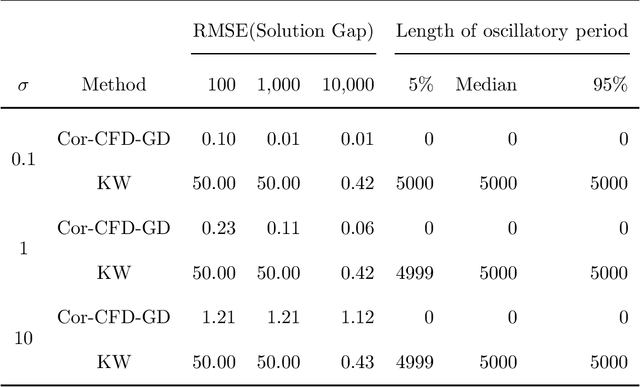
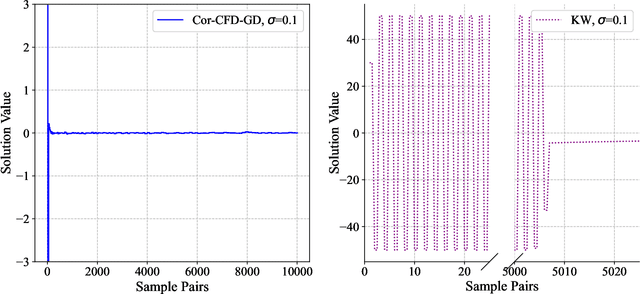
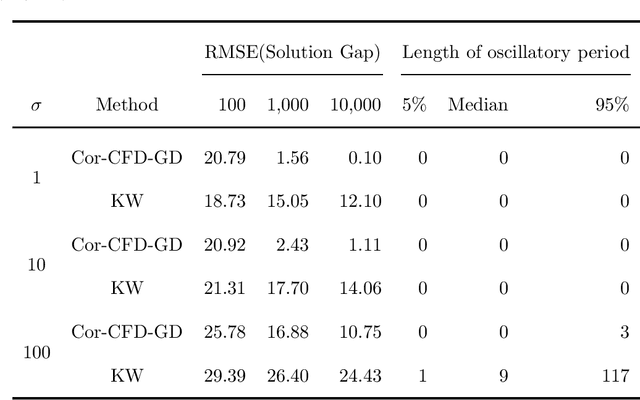
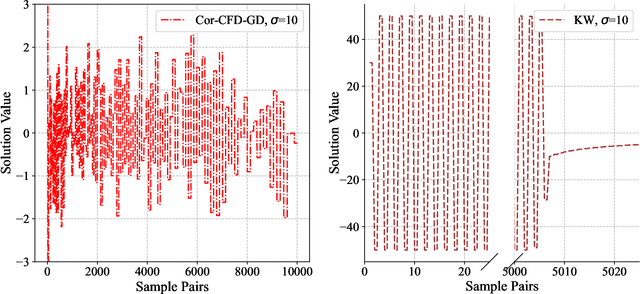
Derivative-free optimization (DFO) is vital in solving complex optimization problems where only noisy function evaluations are available through an oracle. Within this domain, DFO via finite difference (FD) approximation has emerged as a powerful method. Two classical approaches are the Kiefer-Wolfowitz (KW) and simultaneous perturbation stochastic approximation (SPSA) algorithms, which estimate gradients using just two samples in each iteration to conserve samples. However, this approach yields imprecise gradient estimators, necessitating diminishing step sizes to ensure convergence, often resulting in slow optimization progress. In contrast, FD estimators constructed from batch samples approximate gradients more accurately. While gradient descent algorithms using batch-based FD estimators achieve more precise results in each iteration, they require more samples and permit fewer iterations. This raises a fundamental question: which approach is more effective -- KW-style methods or DFO with batch-based FD estimators? This paper conducts a comprehensive experimental comparison among these approaches, examining the fundamental trade-off between gradient estimation accuracy and iteration steps. Through extensive experiments in both low-dimensional and high-dimensional settings, we demonstrate a surprising finding: when an efficient batch-based FD estimator is applied, its corresponding gradient descent algorithm generally shows better performance compared to classical KW and SPSA algorithms in our tested scenarios.
Noise-aware Dynamic Image Denoising and Positron Range Correction for Rubidium-82 Cardiac PET Imaging via Self-supervision
Sep 17, 2024



Rb-82 is a radioactive isotope widely used for cardiac PET imaging. Despite numerous benefits of 82-Rb, there are several factors that limits its image quality and quantitative accuracy. First, the short half-life of 82-Rb results in noisy dynamic frames. Low signal-to-noise ratio would result in inaccurate and biased image quantification. Noisy dynamic frames also lead to highly noisy parametric images. The noise levels also vary substantially in different dynamic frames due to radiotracer decay and short half-life. Existing denoising methods are not applicable for this task due to the lack of paired training inputs/labels and inability to generalize across varying noise levels. Second, 82-Rb emits high-energy positrons. Compared with other tracers such as 18-F, 82-Rb travels a longer distance before annihilation, which negatively affect image spatial resolution. Here, the goal of this study is to propose a self-supervised method for simultaneous (1) noise-aware dynamic image denoising and (2) positron range correction for 82-Rb cardiac PET imaging. Tested on a series of PET scans from a cohort of normal volunteers, the proposed method produced images with superior visual quality. To demonstrate the improvement in image quantification, we compared image-derived input functions (IDIFs) with arterial input functions (AIFs) from continuous arterial blood samples. The IDIF derived from the proposed method led to lower AUC differences, decreasing from 11.09% to 7.58% on average, compared to the original dynamic frames. The proposed method also improved the quantification of myocardium blood flow (MBF), as validated against 15-O-water scans, with mean MBF differences decreased from 0.43 to 0.09, compared to the original dynamic frames. We also conducted a generalizability experiment on 37 patient scans obtained from a different country using a different scanner.
EnviroExam: Benchmarking Environmental Science Knowledge of Large Language Models
May 18, 2024In the field of environmental science, it is crucial to have robust evaluation metrics for large language models to ensure their efficacy and accuracy. We propose EnviroExam, a comprehensive evaluation method designed to assess the knowledge of large language models in the field of environmental science. EnviroExam is based on the curricula of top international universities, covering undergraduate, master's, and doctoral courses, and includes 936 questions across 42 core courses. By conducting 0-shot and 5-shot tests on 31 open-source large language models, EnviroExam reveals the performance differences among these models in the domain of environmental science and provides detailed evaluation standards. The results show that 61.3% of the models passed the 5-shot tests, while 48.39% passed the 0-shot tests. By introducing the coefficient of variation as an indicator, we evaluate the performance of mainstream open-source large language models in environmental science from multiple perspectives, providing effective criteria for selecting and fine-tuning language models in this field. Future research will involve constructing more domain-specific test sets using specialized environmental science textbooks to further enhance the accuracy and specificity of the evaluation.
Dose-aware Diffusion Model for 3D Ultra Low-dose PET Imaging
Nov 07, 2023As PET imaging is accompanied by substantial radiation exposure and cancer risk, reducing radiation dose in PET scans is an important topic. Recently, diffusion models have emerged as the new state-of-the-art generative model to generate high-quality samples and have demonstrated strong potential for various tasks in medical imaging. However, it is difficult to extend diffusion models for 3D image reconstructions due to the memory burden. Directly stacking 2D slices together to create 3D image volumes would results in severe inconsistencies between slices. Previous works tried to either applying a penalty term along the z-axis to remove inconsistencies or reconstructing the 3D image volumes with 2 pre-trained perpendicular 2D diffusion models. Nonetheless, these previous methods failed to produce satisfactory results in challenging cases for PET image denoising. In addition to administered dose, the noise-levels in PET images are affected by several other factors in clinical settings, such as scan time, patient size, and weight, etc. Therefore, a method to simultaneously denoise PET images with different noise-levels is needed. Here, we proposed a dose-aware diffusion model for 3D low-dose PET imaging (DDPET) to address these challenges. The proposed DDPET method was tested on 295 patients from three different medical institutions globally with different low-dose levels. These patient data were acquired on three different commercial PET scanners, including Siemens Vision Quadra, Siemens mCT, and United Imaging Healthcare uExplorere. The proposed method demonstrated superior performance over previously proposed diffusion models for 3D imaging problems as well as models proposed for noise-aware medical image denoising. Code is available at: xxx.
A Lifetime Extended Energy Management Strategy for Fuel Cell Hybrid Electric Vehicles via Self-Learning Fuzzy Reinforcement Learning
Feb 13, 2023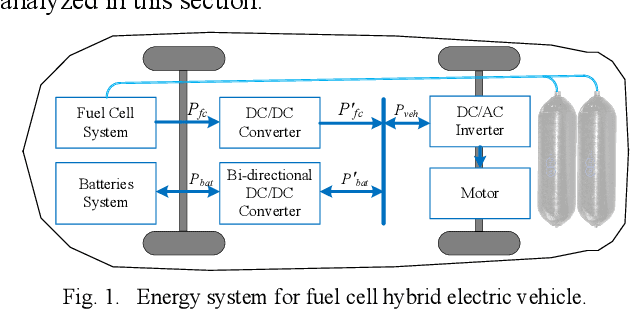
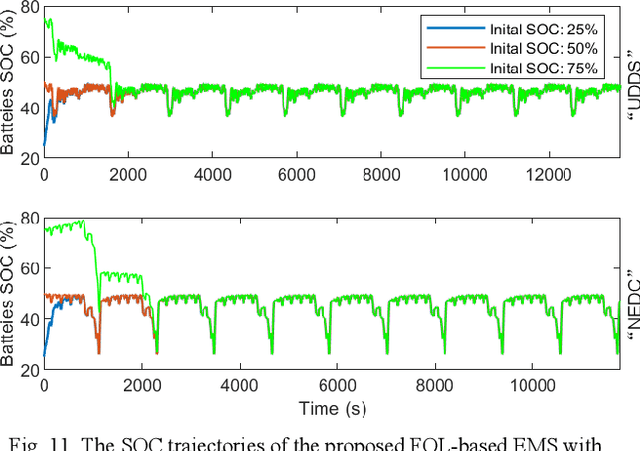
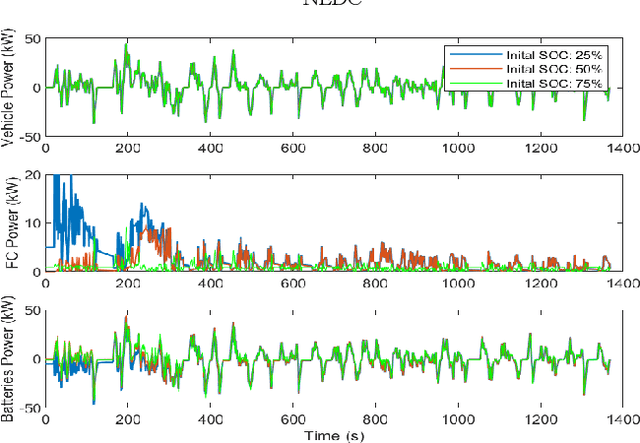
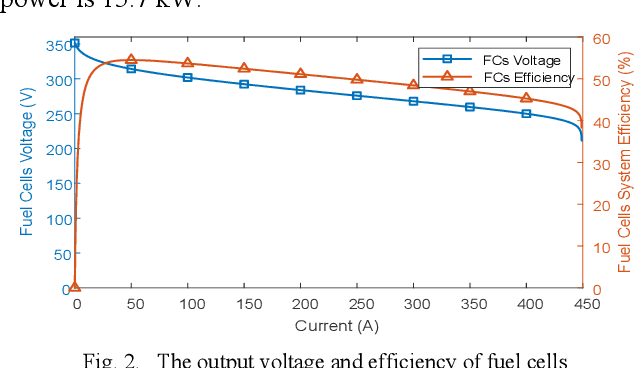
Modeling difficulty, time-varying model, and uncertain external inputs are the main challenges for energy management of fuel cell hybrid electric vehicles. In the paper, a fuzzy reinforcement learning-based energy management strategy for fuel cell hybrid electric vehicles is proposed to reduce fuel consumption, maintain the batteries' long-term operation, and extend the lifetime of the fuel cells system. Fuzzy Q-learning is a model-free reinforcement learning that can learn itself by interacting with the environment, so there is no need for modeling the fuel cells system. In addition, frequent startup of the fuel cells will reduce the remaining useful life of the fuel cells system. The proposed method suppresses frequent fuel cells startup by considering the penalty for the times of fuel cell startups in the reward of reinforcement learning. Moreover, applying fuzzy logic to approximate the value function in Q-Learning can solve continuous state and action space problems. Finally, a python-based training and testing platform verify the effectiveness and self-learning improvement of the proposed method under conditions of initial state change, model change and driving condition change.
Multi-scale temporal-frequency attention for music source separation
Sep 02, 2022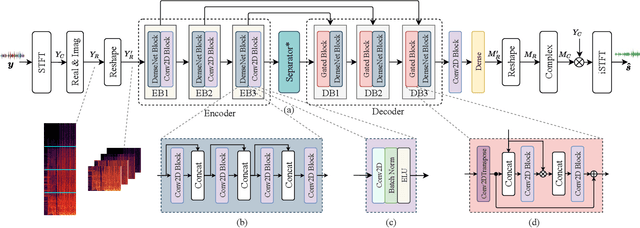
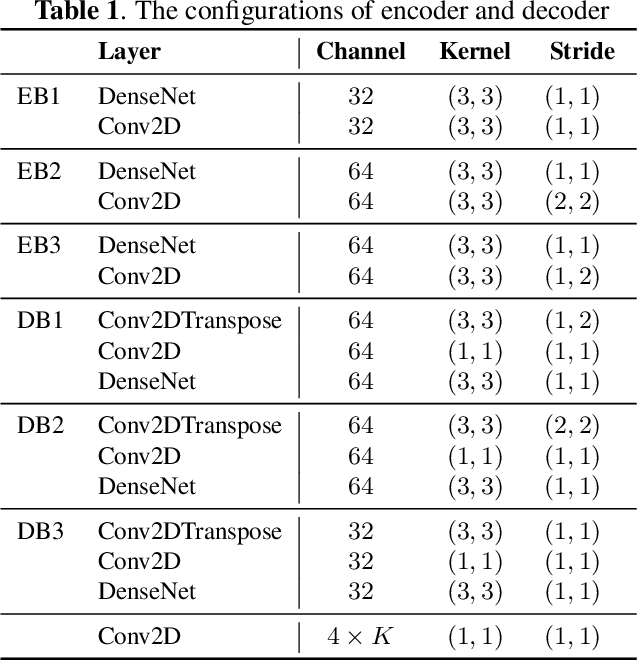
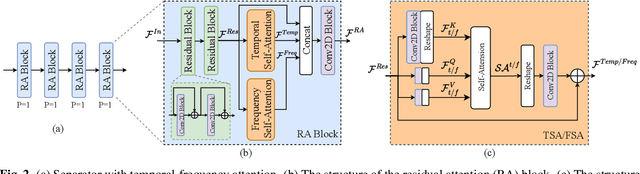
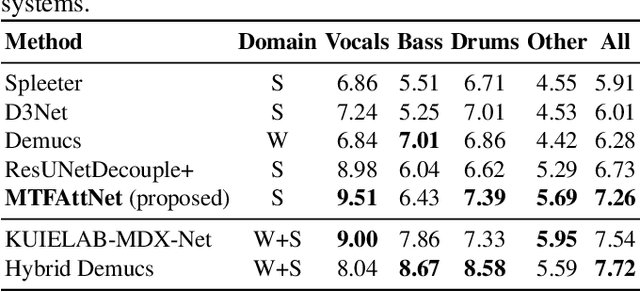
In recent years, deep neural networks (DNNs) based approaches have achieved the start-of-the-art performance for music source separation (MSS). Although previous methods have addressed the large receptive field modeling using various methods, the temporal and frequency correlations of the music spectrogram with repeated patterns have not been explicitly explored for the MSS task. In this paper, a temporal-frequency attention module is proposed to model the spectrogram correlations along both temporal and frequency dimensions. Moreover, a multi-scale attention is proposed to effectively capture the correlations for music signal. The experimental results on MUSDB18 dataset show that the proposed method outperforms the existing state-of-the-art systems with 9.51 dB signal-to-distortion ratio (SDR) on separating the vocal stems, which is the primary practical application of MSS.