Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA two-step backward compatible fullband speech enhancement system
Paper and Code
Jan 28, 2022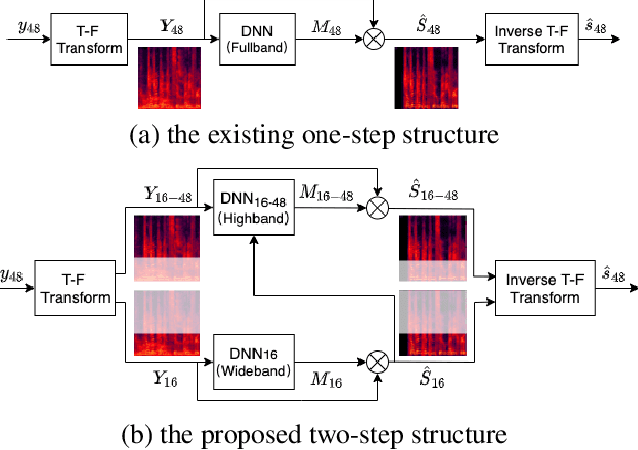
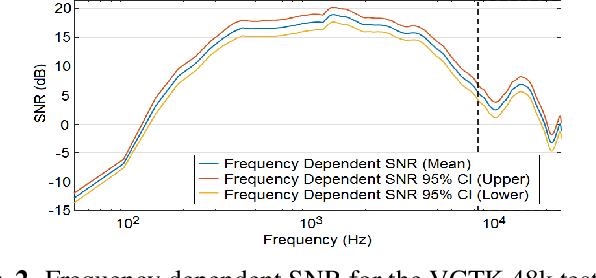
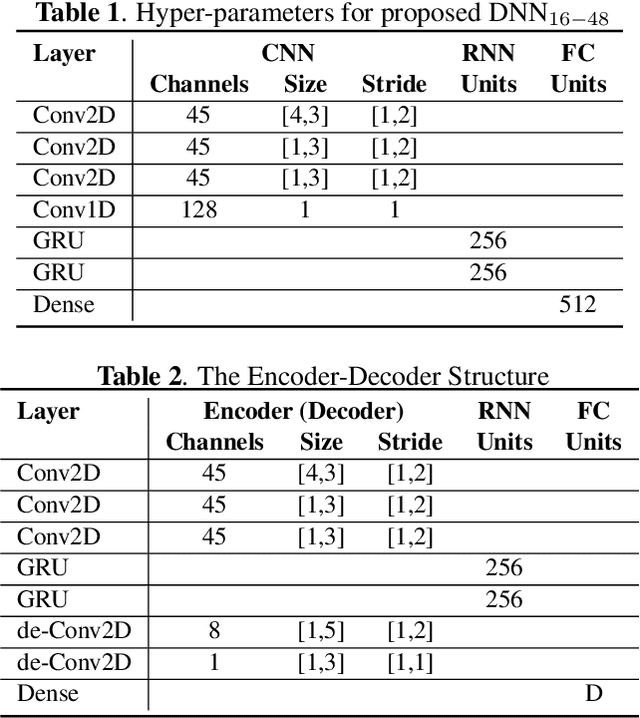
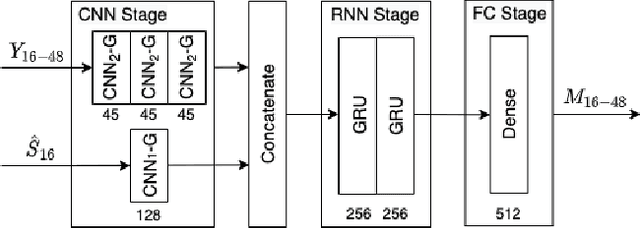
Speech enhancement methods based on deep learning have surpassed traditional methods. While many of these new approaches are operating on the wideband (16kHz) sample rate, a new fullband (48kHz) speech enhancement system is proposed in this paper. Compared to the existing fullband systems that utilizes perceptually motivated features to train the fullband speech enhancement using a single network structure, the proposed system is a two-step system ensuring good fullband speech enhancement quality while backward compatible to the existing wideband systems.
View paper on