 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Mean Opinion Score Prediction
Aug 23, 2024Mean Opinion Score (MOS) prediction has made significant progress in specific domains. However, the unstable performance of MOS prediction models across diverse samples presents ongoing challenges in the practical application of these systems. In this paper, we point out that the absence of uncertainty modeling is a significant limitation hindering MOS prediction systems from applying to the real and open world. We analyze the sources of uncertainty in the MOS prediction task and propose to establish an uncertainty-aware MOS prediction system that models aleatory uncertainty and epistemic uncertainty by heteroscedastic regression and Monte Carlo dropout separately. The experimental results show that the system captures uncertainty well and is capable of performing selective prediction and out-of-domain detection. Such capabilities significantly enhance the practical utility of MOS systems in diverse real and open-world environments.
KS-Net: Multi-band joint speech restoration and enhancement network for 2024 ICASSP SSI Challenge
Feb 02, 2024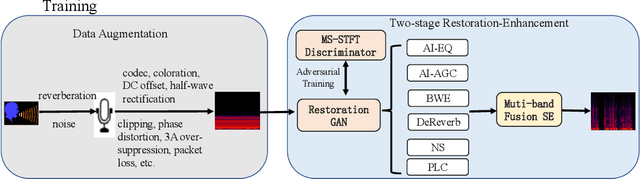
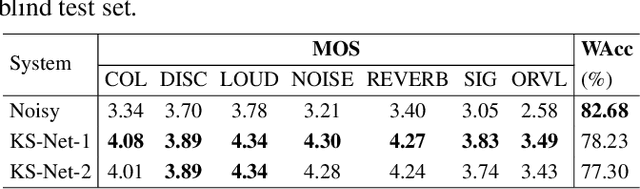
This paper presents the speech restoration and enhancement system created by the 1024K team for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. Our system consists of a generative adversarial network (GAN) in complex-domain for speech restoration and a fine-grained multi-band fusion module for speech enhancement. In the blind test set of SSI, the proposed system achieves an overall mean opinion score (MOS) of 3.49 based on ITU-T P.804 and a Word Accuracy Rate (WAcc) of 0.78 for the real-time track, as well as an overall P.804 MOS of 3.43 and a WAcc of 0.78 for the non-real-time track, ranking 1st in both tracks.
BAE-Net: A Low complexity and high fidelity Bandwidth-Adaptive neural network for speech super-resolution
Dec 21, 2023



Speech bandwidth extension (BWE) has demonstrated promising performance in enhancing the perceptual speech quality in real communication systems. Most existing BWE researches primarily focus on fixed upsampling ratios, disregarding the fact that the effective bandwidth of captured audio may fluctuate frequently due to various capturing devices and transmission conditions. In this paper, we propose a novel streaming adaptive bandwidth extension solution dubbed BAE-Net, which is suitable to handle the low-resolution speech with unknown and varying effective bandwidth. To address the challenges of recovering both the high-frequency magnitude and phase speech content blindly, we devise a dual-stream architecture that incorporates the magnitude inpainting and phase refinement. For potential applications on edge devices, this paper also introduces BAE-NET-lite, which is a lightweight, streaming and efficient framework. Quantitative results demonstrate the superiority of BAE-Net in terms of both performance and computational efficiency when compared with existing state-of-the-art BWE methods.
RAMP: Retrieval-Augmented MOS Prediction via Confidence-based Dynamic Weighting
Aug 31, 2023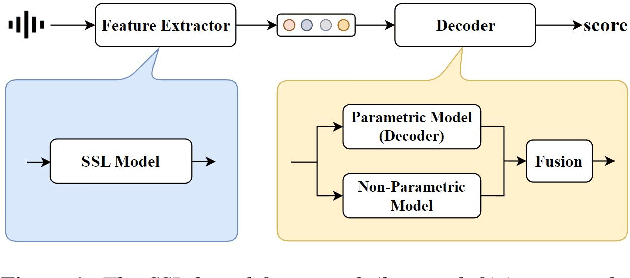
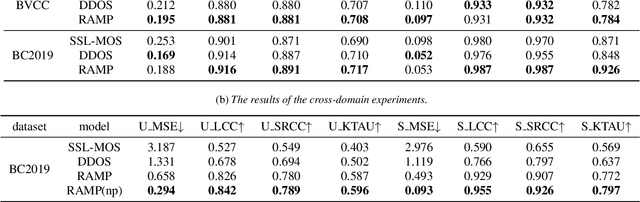
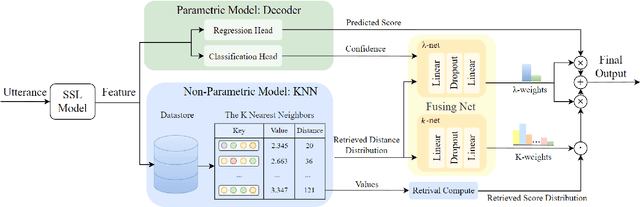

Automatic Mean Opinion Score (MOS) prediction is crucial to evaluate the perceptual quality of the synthetic speech. While recent approaches using pre-trained self-supervised learning (SSL) models have shown promising results, they only partly address the data scarcity issue for the feature extractor. This leaves the data scarcity issue for the decoder unresolved and leading to suboptimal performance. To address this challenge, we propose a retrieval-augmented MOS prediction method, dubbed {\bf RAMP}, to enhance the decoder's ability against the data scarcity issue. A fusing network is also proposed to dynamically adjust the retrieval scope for each instance and the fusion weights based on the predictive confidence. Experimental results show that our proposed method outperforms the existing methods in multiple scenarios.
* Accepted by Interspeech 2023, oral
Multi-scale temporal-frequency attention for music source separation
Sep 02, 2022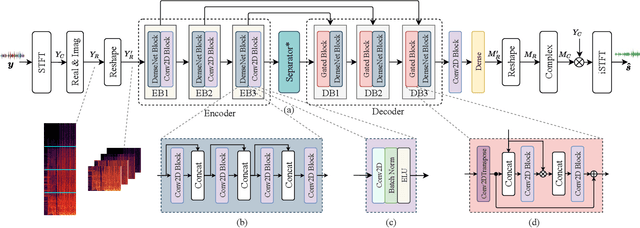
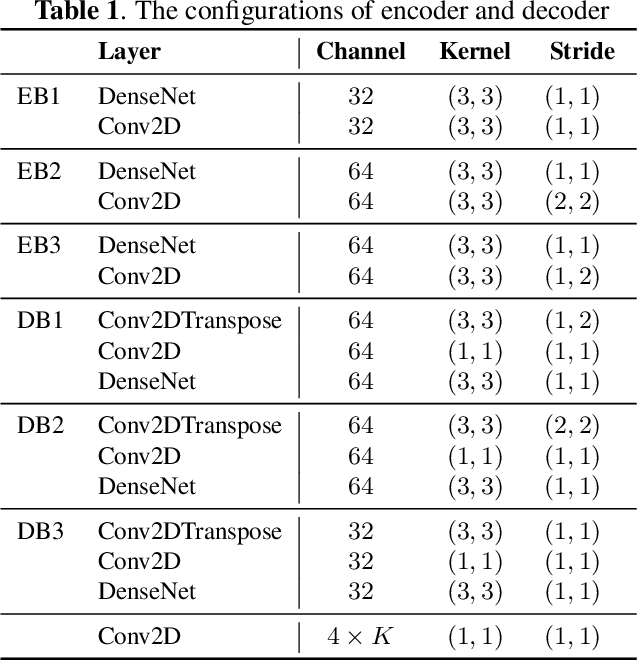
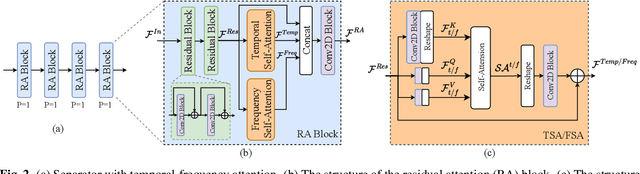
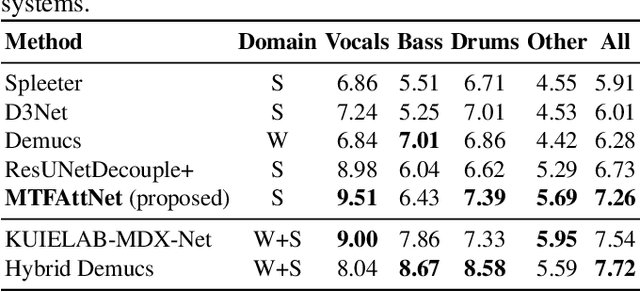
In recent years, deep neural networks (DNNs) based approaches have achieved the start-of-the-art performance for music source separation (MSS). Although previous methods have addressed the large receptive field modeling using various methods, the temporal and frequency correlations of the music spectrogram with repeated patterns have not been explicitly explored for the MSS task. In this paper, a temporal-frequency attention module is proposed to model the spectrogram correlations along both temporal and frequency dimensions. Moreover, a multi-scale attention is proposed to effectively capture the correlations for music signal. The experimental results on MUSDB18 dataset show that the proposed method outperforms the existing state-of-the-art systems with 9.51 dB signal-to-distortion ratio (SDR) on separating the vocal stems, which is the primary practical application of MSS.
L3DAS22 Challenge: Learning 3D Audio Sources in a Real Office Environment
Feb 21, 2022
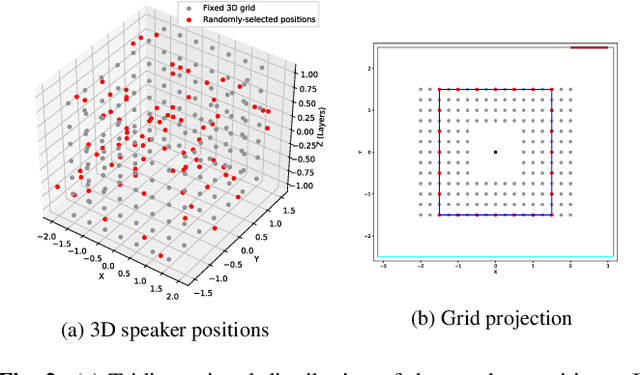
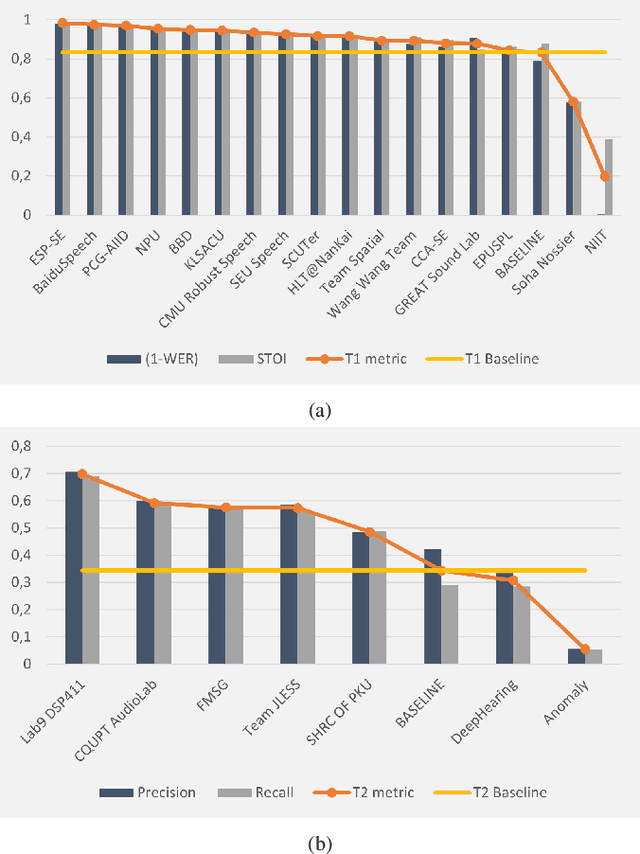
The L3DAS22 Challenge is aimed at encouraging the development of machine learning strategies for 3D speech enhancement and 3D sound localization and detection in office-like environments. This challenge improves and extends the tasks of the L3DAS21 edition. We generated a new dataset, which maintains the same general characteristics of L3DAS21 datasets, but with an extended number of data points and adding constrains that improve the baseline model's efficiency and overcome the major difficulties encountered by the participants of the previous challenge. We updated the baseline model of Task 1, using the architecture that ranked first in the previous challenge edition. We wrote a new supporting API, improving its clarity and ease-of-use. In the end, we present and discuss the results submitted by all participants. L3DAS22 Challenge website: www.l3das.com/icassp2022.
A two-step backward compatible fullband speech enhancement system
Jan 28, 2022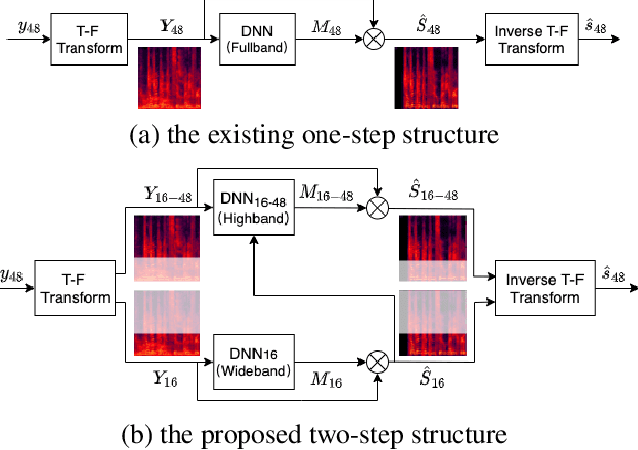
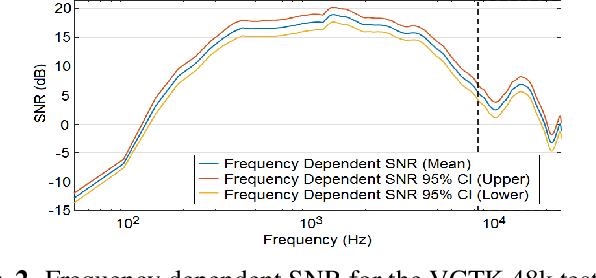
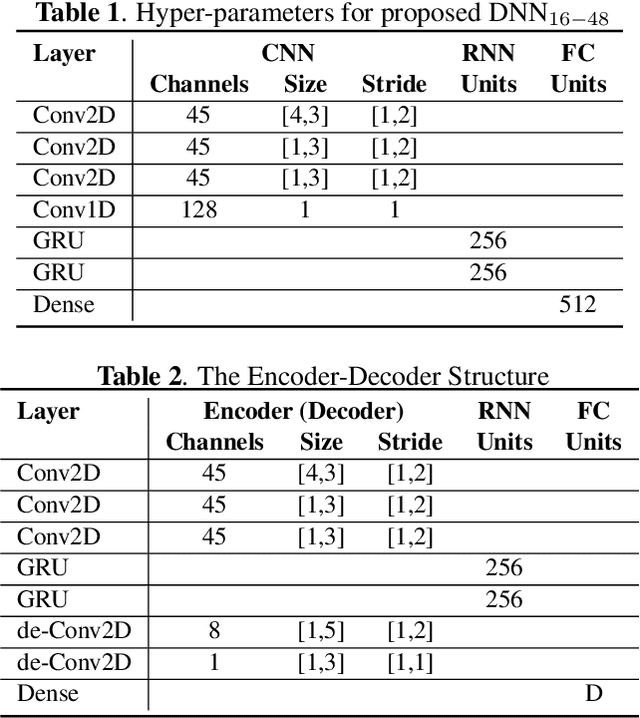
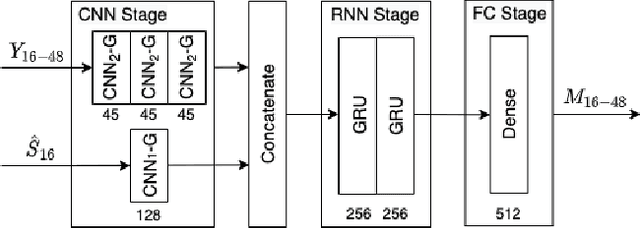
Speech enhancement methods based on deep learning have surpassed traditional methods. While many of these new approaches are operating on the wideband (16kHz) sample rate, a new fullband (48kHz) speech enhancement system is proposed in this paper. Compared to the existing fullband systems that utilizes perceptually motivated features to train the fullband speech enhancement using a single network structure, the proposed system is a two-step system ensuring good fullband speech enhancement quality while backward compatible to the existing wideband systems.