 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Modality Gap Aligns Group-Wise Semantics
Jan 26, 2026In multimodal learning, CLIP has been recognized as the \textit{de facto} method for learning a shared latent space across multiple modalities, placing similar representations close to each other and moving them away from dissimilar ones. Although CLIP-based losses effectively align modalities at the semantic level, the resulting latent spaces often remain only partially shared, revealing a structural mismatch known as the modality gap. While the necessity of addressing this phenomenon remains debated, particularly given its limited impact on instance-wise tasks (e.g., retrieval), we prove that its influence is instead strongly pronounced in group-level tasks (e.g., clustering). To support this claim, we introduce a novel method designed to consistently reduce this discrepancy in two-modal settings, with a straightforward extension to the general $n$-modal case. Through our extensive evaluation, we demonstrate our novel insight: while reducing the gap provides only marginal or inconsistent improvements in traditional instance-wise tasks, it significantly enhances group-wise tasks. These findings may reshape our understanding of the modality gap, highlighting its key role in improving performance on tasks requiring semantic grouping.
Quaternion Wavelet-Conditioned Diffusion Models for Image Super-Resolution
May 05, 2025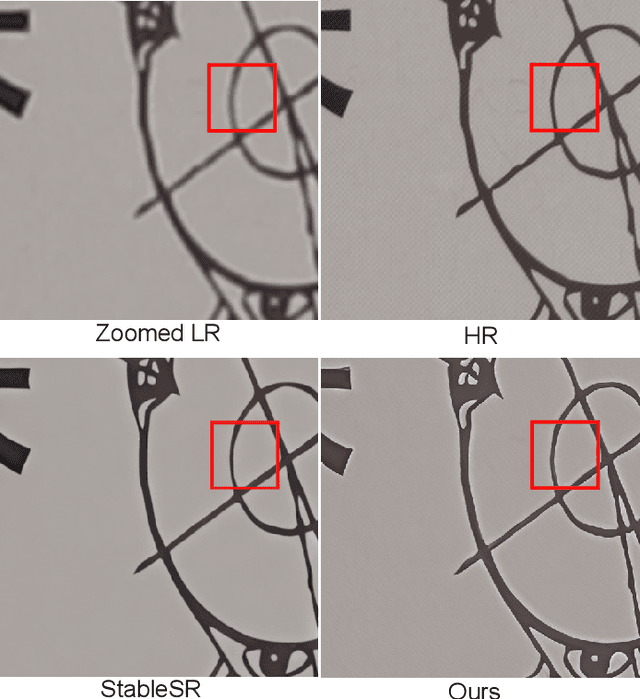
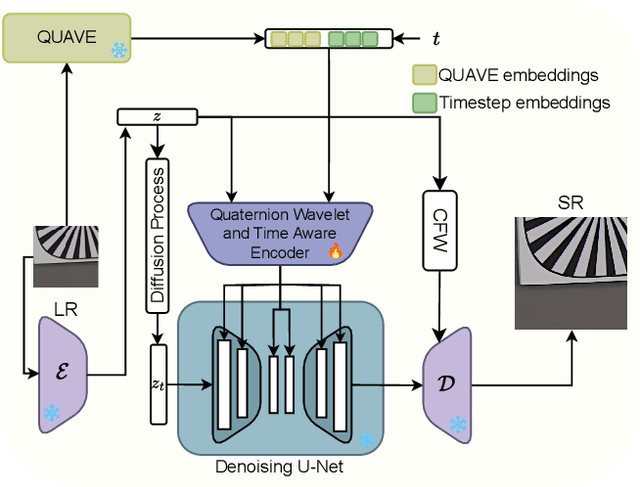

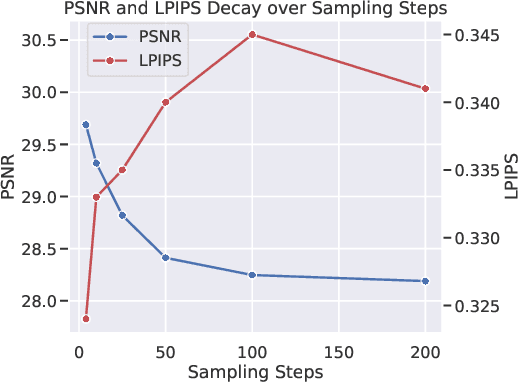
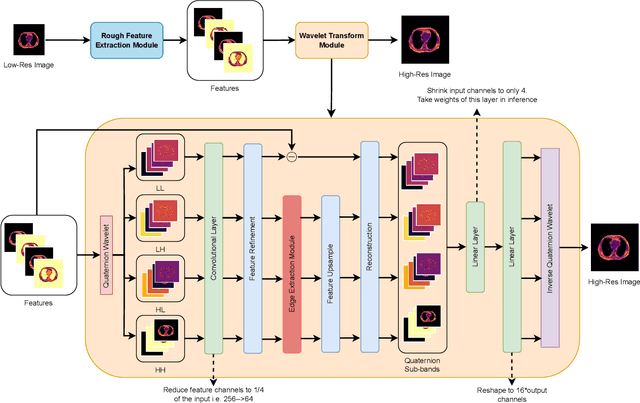
Image Super-Resolution is a fundamental problem in computer vision with broad applications spacing from medical imaging to satellite analysis. The ability to reconstruct high-resolution images from low-resolution inputs is crucial for enhancing downstream tasks such as object detection and segmentation. While deep learning has significantly advanced SR, achieving high-quality reconstructions with fine-grained details and realistic textures remains challenging, particularly at high upscaling factors. Recent approaches leveraging diffusion models have demonstrated promising results, yet they often struggle to balance perceptual quality with structural fidelity. In this work, we introduce ResQu a novel SR framework that integrates a quaternion wavelet preprocessing framework with latent diffusion models, incorporating a new quaternion wavelet- and time-aware encoder. Unlike prior methods that simply apply wavelet transforms within diffusion models, our approach enhances the conditioning process by exploiting quaternion wavelet embeddings, which are dynamically integrated at different stages of denoising. Furthermore, we also leverage the generative priors of foundation models such as Stable Diffusion. Extensive experiments on domain-specific datasets demonstrate that our method achieves outstanding SR results, outperforming in many cases existing approaches in perceptual quality and standard evaluation metrics. The code will be available after the revision process.
Beyond Answers: How LLMs Can Pursue Strategic Thinking in Education
Apr 07, 2025


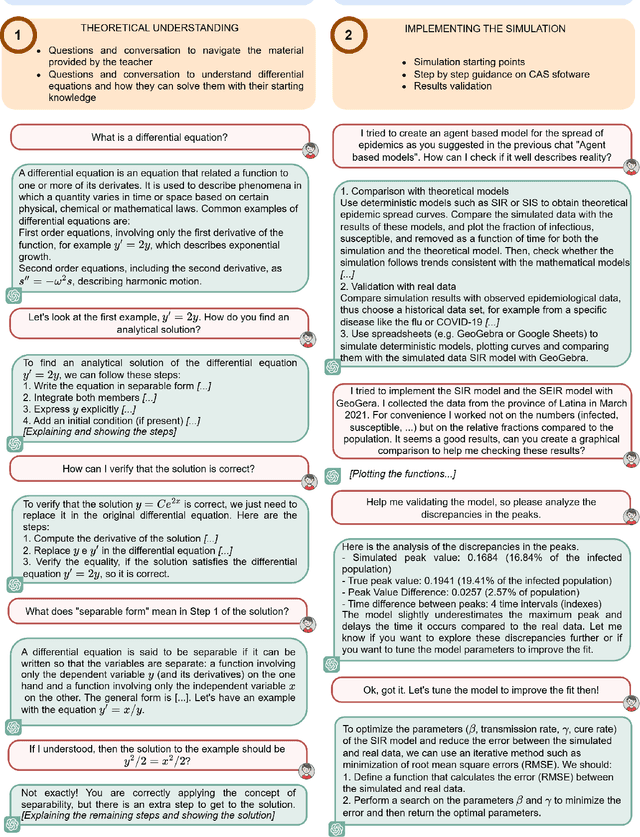
Artificial Intelligence (AI) holds transformative potential in education, enabling personalized learning, enhancing inclusivity, and encouraging creativity and curiosity. In this paper, we explore how Large Language Models (LLMs) can act as both patient tutors and collaborative partners to enhance education delivery. As tutors, LLMs personalize learning by offering step-by-step explanations and addressing individual needs, making education more inclusive for students with diverse backgrounds or abilities. As collaborators, they expand students' horizons, supporting them in tackling complex, real-world problems and co-creating innovative projects. However, to fully realize these benefits, LLMs must be leveraged not as tools for providing direct solutions but rather to guide students in developing resolving strategies and finding learning paths together. Therefore, a strong emphasis should be placed on educating students and teachers on the successful use of LLMs to ensure their effective integration into classrooms. Through practical examples and real-world case studies, this paper illustrates how LLMs can make education more inclusive and engaging while empowering students to reach their full potential.
A Wavelet Diffusion GAN for Image Super-Resolution
Oct 23, 2024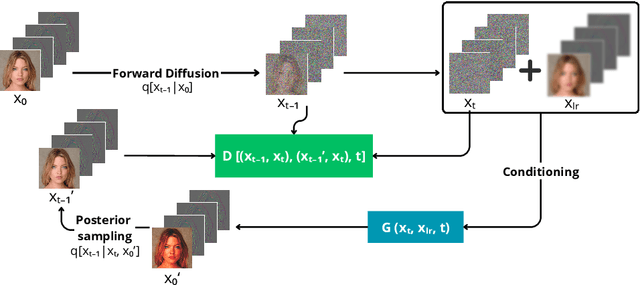
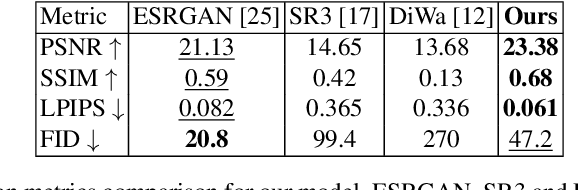
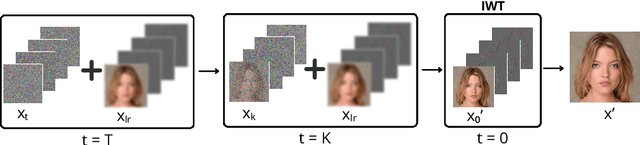

In recent years, diffusion models have emerged as a superior alternative to generative adversarial networks (GANs) for high-fidelity image generation, with wide applications in text-to-image generation, image-to-image translation, and super-resolution. However, their real-time feasibility is hindered by slow training and inference speeds. This study addresses this challenge by proposing a wavelet-based conditional Diffusion GAN scheme for Single-Image Super-Resolution (SISR). Our approach utilizes the diffusion GAN paradigm to reduce the timesteps required by the reverse diffusion process and the Discrete Wavelet Transform (DWT) to achieve dimensionality reduction, decreasing training and inference times significantly. The results of an experimental validation on the CelebA-HQ dataset confirm the effectiveness of our proposed scheme. Our approach outperforms other state-of-the-art methodologies successfully ensuring high-fidelity output while overcoming inherent drawbacks associated with diffusion models in time-sensitive applications.
Hierarchical Hypercomplex Network for Multimodal Emotion Recognition
Sep 13, 2024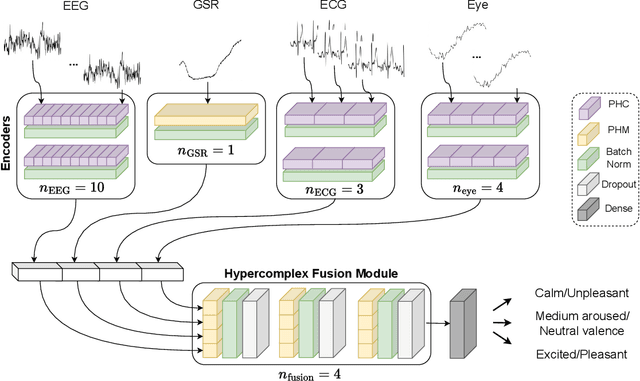
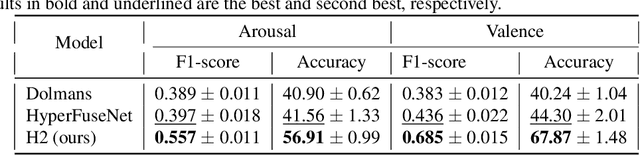
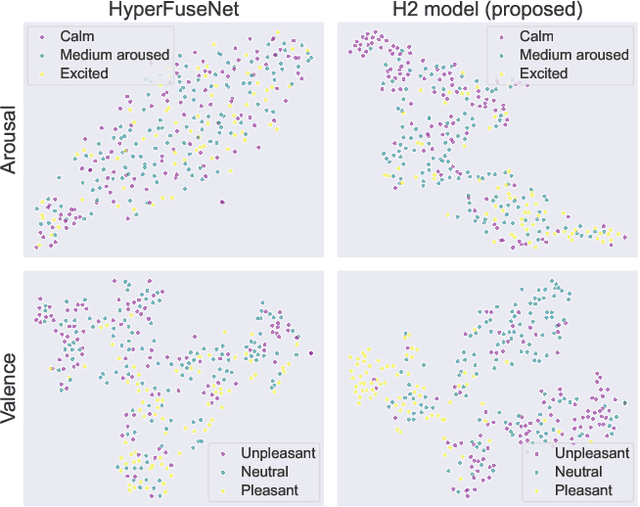
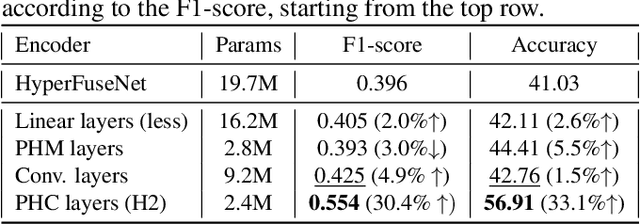
Emotion recognition is relevant in various domains, ranging from healthcare to human-computer interaction. Physiological signals, being beyond voluntary control, offer reliable information for this purpose, unlike speech and facial expressions which can be controlled at will. They reflect genuine emotional responses, devoid of conscious manipulation, thereby enhancing the credibility of emotion recognition systems. Nonetheless, multimodal emotion recognition with deep learning models remains a relatively unexplored field. In this paper, we introduce a fully hypercomplex network with a hierarchical learning structure to fully capture correlations. Specifically, at the encoder level, the model learns intra-modal relations among the different channels of each input signal. Then, a hypercomplex fusion module learns inter-modal relations among the embeddings of the different modalities. The main novelty is in exploiting intra-modal relations by endowing the encoders with parameterized hypercomplex convolutions (PHCs) that thanks to hypercomplex algebra can capture inter-channel interactions within single modalities. Instead, the fusion module comprises parameterized hypercomplex multiplications (PHMs) that can model inter-modal correlations. The proposed architecture surpasses state-of-the-art models on the MAHNOB-HCI dataset for emotion recognition, specifically in classifying valence and arousal from electroencephalograms (EEGs) and peripheral physiological signals. The code of this study is available at https://github.com/ispamm/MHyEEG.
Demystifying the Hypercomplex: Inductive Biases in Hypercomplex Deep Learning
May 11, 2024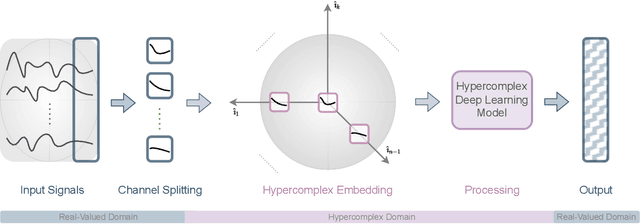
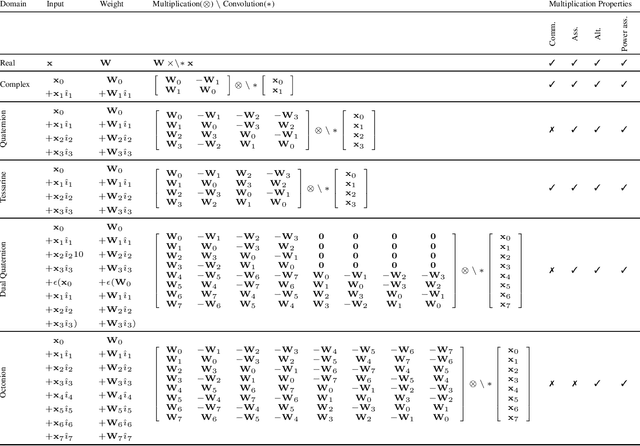
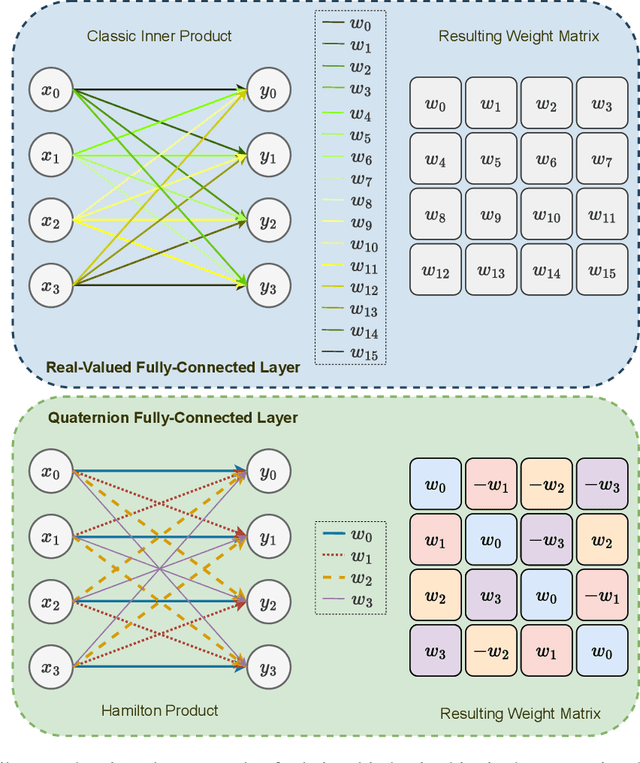
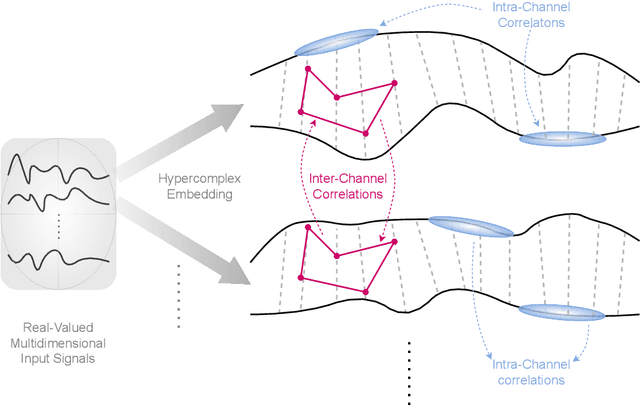
Hypercomplex algebras have recently been gaining prominence in the field of deep learning owing to the advantages of their division algebras over real vector spaces and their superior results when dealing with multidimensional signals in real-world 3D and 4D paradigms. This paper provides a foundational framework that serves as a roadmap for understanding why hypercomplex deep learning methods are so successful and how their potential can be exploited. Such a theoretical framework is described in terms of inductive bias, i.e., a collection of assumptions, properties, and constraints that are built into training algorithms to guide their learning process toward more efficient and accurate solutions. We show that it is possible to derive specific inductive biases in the hypercomplex domains, which extend complex numbers to encompass diverse numbers and data structures. These biases prove effective in managing the distinctive properties of these domains, as well as the complex structures of multidimensional and multimodal signals. This novel perspective for hypercomplex deep learning promises to both demystify this class of methods and clarify their potential, under a unifying framework, and in this way promotes hypercomplex models as viable alternatives to traditional real-valued deep learning for multidimensional signal processing.
Overview of the L3DAS23 Challenge on Audio-Visual Extended Reality
Feb 14, 2024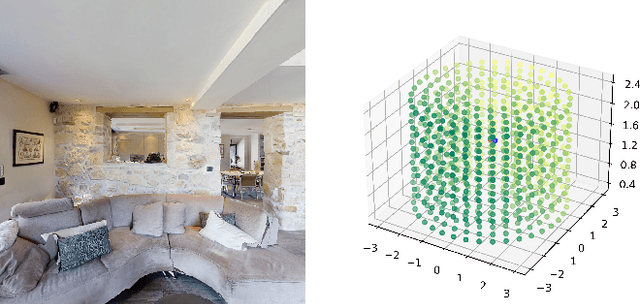
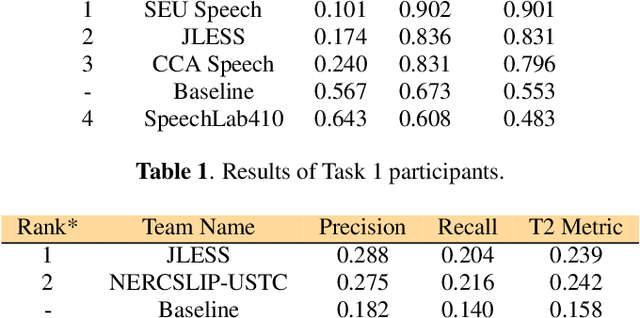
The primary goal of the L3DAS23 Signal Processing Grand Challenge at ICASSP 2023 is to promote and support collaborative research on machine learning for 3D audio signal processing, with a specific emphasis on 3D speech enhancement and 3D Sound Event Localization and Detection in Extended Reality applications. As part of our latest competition, we provide a brand-new dataset, which maintains the same general characteristics of the L3DAS21 and L3DAS22 datasets, but with first-order Ambisonics recordings from multiple reverberant simulated environments. Moreover, we start exploring an audio-visual scenario by providing images of these environments, as perceived by the different microphone positions and orientations. We also propose updated baseline models for both tasks that can now support audio-image couples as input and a supporting API to replicate our results. Finally, we present the results of the participants. Further details about the challenge are available at https://www.l3das.com/icassp2023.
Generalizing Medical Image Representations via Quaternion Wavelet Networks
Oct 16, 2023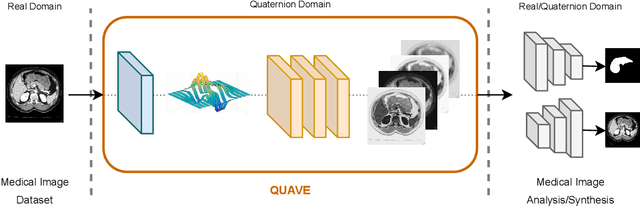
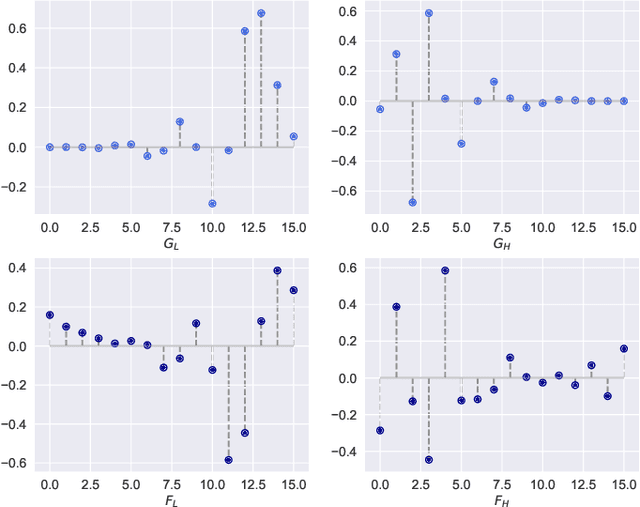
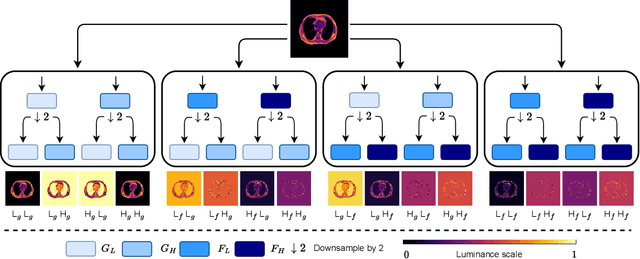
Neural network generalizability is becoming a broad research field due to the increasing availability of datasets from different sources and for various tasks. This issue is even wider when processing medical data, where a lack of methodological standards causes large variations being provided by different imaging centers or acquired with various devices and cofactors. To overcome these limitations, we introduce a novel, generalizable, data- and task-agnostic framework able to extract salient features from medical images. The proposed quaternion wavelet network (QUAVE) can be easily integrated with any pre-existing medical image analysis or synthesis task, and it can be involved with real, quaternion, or hypercomplex-valued models, generalizing their adoption to single-channel data. QUAVE first extracts different sub-bands through the quaternion wavelet transform, resulting in both low-frequency/approximation bands and high-frequency/fine-grained features. Then, it weighs the most representative set of sub-bands to be involved as input to any other neural model for image processing, replacing standard data samples. We conduct an extensive experimental evaluation comprising different datasets, diverse image analysis, and synthesis tasks including reconstruction, segmentation, and modality translation. We also evaluate QUAVE in combination with both real and quaternion-valued models. Results demonstrate the effectiveness and the generalizability of the proposed framework that improves network performance while being flexible to be adopted in manifold scenarios.
PHYDI: Initializing Parameterized Hypercomplex Neural Networks as Identity Functions
Oct 11, 2023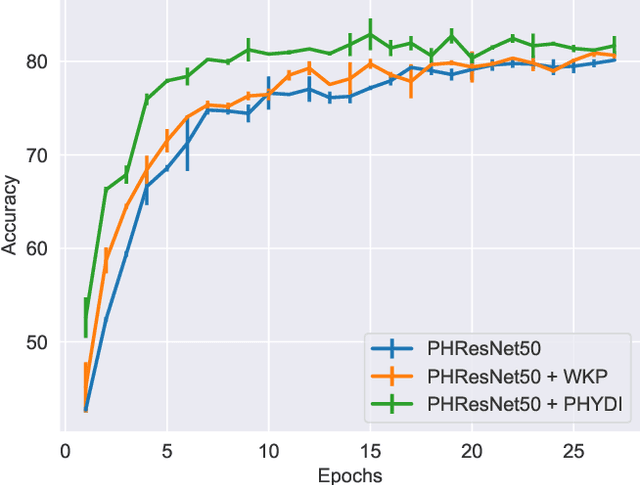
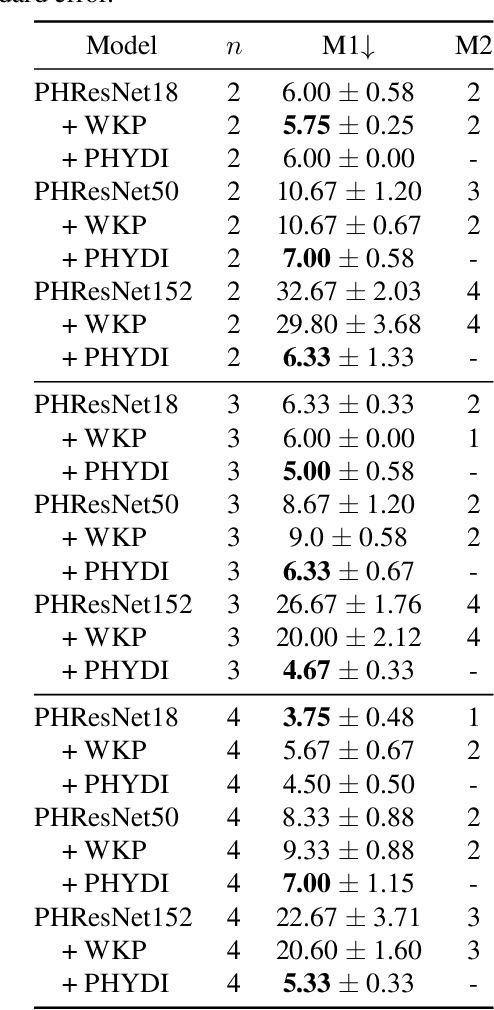
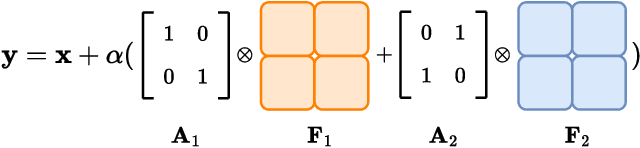
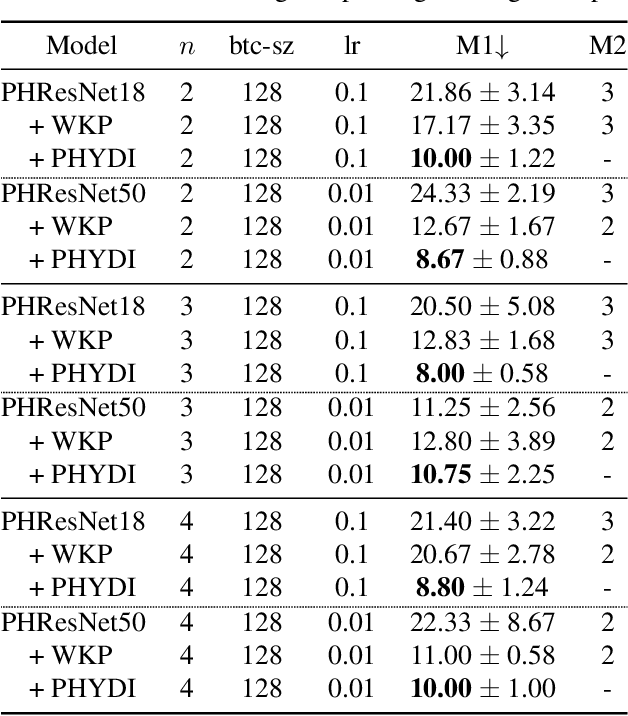
Neural models based on hypercomplex algebra systems are growing and prolificating for a plethora of applications, ranging from computer vision to natural language processing. Hand in hand with their adoption, parameterized hypercomplex neural networks (PHNNs) are growing in size and no techniques have been adopted so far to control their convergence at a large scale. In this paper, we study PHNNs convergence and propose parameterized hypercomplex identity initialization (PHYDI), a method to improve their convergence at different scales, leading to more robust performance when the number of layers scales up, while also reaching the same performance with fewer iterations. We show the effectiveness of this approach in different benchmarks and with common PHNNs with ResNets- and Transformer-based architecture. The code is available at https://github.com/ispamm/PHYDI.
Centroids Matching: an efficient Continual Learning approach operating in the embedding space
Aug 03, 2022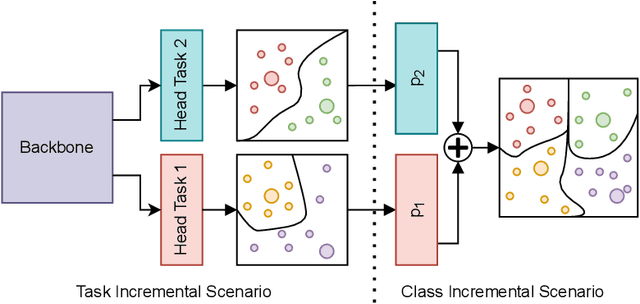


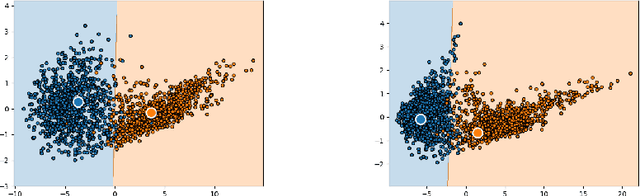
Catastrophic forgetting (CF) occurs when a neural network loses the information previously learned while training on a set of samples from a different distribution, i.e., a new task. Existing approaches have achieved remarkable results in mitigating CF, especially in a scenario called task incremental learning. However, this scenario is not realistic, and limited work has been done to achieve good results on more realistic scenarios. In this paper, we propose a novel regularization method called Centroids Matching, that, inspired by meta-learning approaches, fights CF by operating in the feature space produced by the neural network, achieving good results while requiring a small memory footprint. Specifically, the approach classifies the samples directly using the feature vectors produced by the neural network, by matching those vectors with the centroids representing the classes from the current task, or all the tasks up to that point. Centroids Matching is faster than competing baselines, and it can be exploited to efficiently mitigate CF, by preserving the distances between the embedding space produced by the model when past tasks were over, and the one currently produced, leading to a method that achieves high accuracy on all the tasks, without using an external memory when operating on easy scenarios, or using a small one for more realistic ones. Extensive experiments demonstrate that Centroids Matching achieves accuracy gains on multiple datasets and scenarios.