 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaternion Wavelet-Conditioned Diffusion Models for Image Super-Resolution
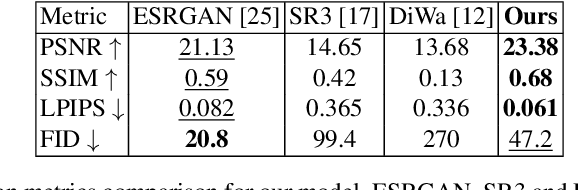
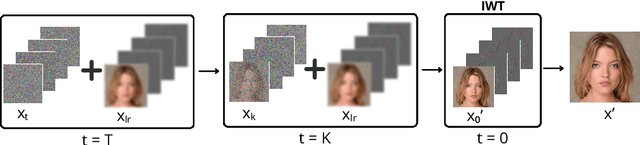
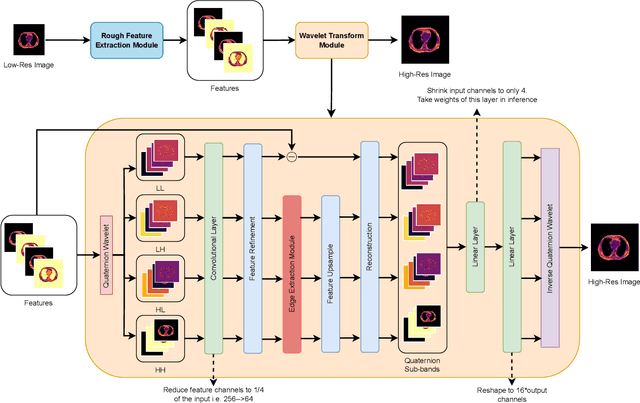
May 05, 2025Image Super-Resolution is a fundamental problem in computer vision with broad applications spacing from medical imaging to satellite analysis. The ability to reconstruct high-resolution images from low-resolution inputs is crucial for enhancing downstream tasks such as object detection and segmentation. While deep learning has significantly advanced SR, achieving high-quality reconstructions with fine-grained details and realistic textures remains challenging, particularly at high upscaling factors. Recent approaches leveraging diffusion models have demonstrated promising results, yet they often struggle to balance perceptual quality with structural fidelity. In this work, we introduce ResQu a novel SR framework that integrates a quaternion wavelet preprocessing framework with latent diffusion models, incorporating a new quaternion wavelet- and time-aware encoder. Unlike prior methods that simply apply wavelet transforms within diffusion models, our approach enhances the conditioning process by exploiting quaternion wavelet embeddings, which are dynamically integrated at different stages of denoising. Furthermore, we also leverage the generative priors of foundation models such as Stable Diffusion. Extensive experiments on domain-specific datasets demonstrate that our method achieves outstanding SR results, outperforming in many cases existing approaches in perceptual quality and standard evaluation metrics. The code will be available after the revision process.
Gramian Multimodal Representation Learning and Alignment
Dec 16, 2024



Human perception integrates multiple modalities, such as vision, hearing, and language, into a unified understanding of the surrounding reality. While recent multimodal models have achieved significant progress by aligning pairs of modalities via contrastive learning, their solutions are unsuitable when scaling to multiple modalities. These models typically align each modality to a designated anchor without ensuring the alignment of all modalities with each other, leading to suboptimal performance in tasks requiring a joint understanding of multiple modalities. In this paper, we structurally rethink the pairwise conventional approach to multimodal learning and we present the novel Gramian Representation Alignment Measure (GRAM), which overcomes the above-mentioned limitations. GRAM learns and then aligns $n$ modalities directly in the higher-dimensional space in which modality embeddings lie by minimizing the Gramian volume of the $k$-dimensional parallelotope spanned by the modality vectors, ensuring the geometric alignment of all modalities simultaneously. GRAM can replace cosine similarity in any downstream method, holding for 2 to $n$ modality and providing more meaningful alignment with respect to previous similarity measures. The novel GRAM-based contrastive loss function enhances the alignment of multimodal models in the higher-dimensional embedding space, leading to new state-of-the-art performance in downstream tasks such as video-audio-text retrieval and audio-video classification. The project page, the code, and the pretrained models are available at https://ispamm.github.io/GRAM/.
A Wavelet Diffusion GAN for Image Super-Resolution
Oct 23, 2024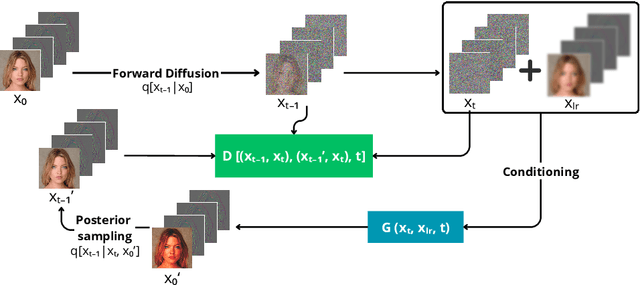

In recent years, diffusion models have emerged as a superior alternative to generative adversarial networks (GANs) for high-fidelity image generation, with wide applications in text-to-image generation, image-to-image translation, and super-resolution. However, their real-time feasibility is hindered by slow training and inference speeds. This study addresses this challenge by proposing a wavelet-based conditional Diffusion GAN scheme for Single-Image Super-Resolution (SISR). Our approach utilizes the diffusion GAN paradigm to reduce the timesteps required by the reverse diffusion process and the Discrete Wavelet Transform (DWT) to achieve dimensionality reduction, decreasing training and inference times significantly. The results of an experimental validation on the CelebA-HQ dataset confirm the effectiveness of our proposed scheme. Our approach outperforms other state-of-the-art methodologies successfully ensuring high-fidelity output while overcoming inherent drawbacks associated with diffusion models in time-sensitive applications.
Ship in Sight: Diffusion Models for Ship-Image Super Resolution
Mar 27, 2024In recent years, remarkable advancements have been achieved in the field of image generation, primarily driven by the escalating demand for high-quality outcomes across various image generation subtasks, such as inpainting, denoising, and super resolution. A major effort is devoted to exploring the application of super-resolution techniques to enhance the quality of low-resolution images. In this context, our method explores in depth the problem of ship image super resolution, which is crucial for coastal and port surveillance. We investigate the opportunity given by the growing interest in text-to-image diffusion models, taking advantage of the prior knowledge that such foundation models have already learned. In particular, we present a diffusion-model-based architecture that leverages text conditioning during training while being class-aware, to best preserve the crucial details of the ships during the generation of the super-resoluted image. Since the specificity of this task and the scarcity availability of off-the-shelf data, we also introduce a large labeled ship dataset scraped from online ship images, mostly from ShipSpotting\footnote{\url{www.shipspotting.com}} website. Our method achieves more robust results than other deep learning models previously employed for super resolution, as proven by the multiple experiments performed. Moreover, we investigate how this model can benefit downstream tasks, such as classification and object detection, thus emphasizing practical implementation in a real-world scenario. Experimental results show flexibility, reliability, and impressive performance of the proposed framework over state-of-the-art methods for different tasks. The code is available at: https://github.com/LuigiSigillo/ShipinSight .
Generalizing Medical Image Representations via Quaternion Wavelet Networks
Oct 16, 2023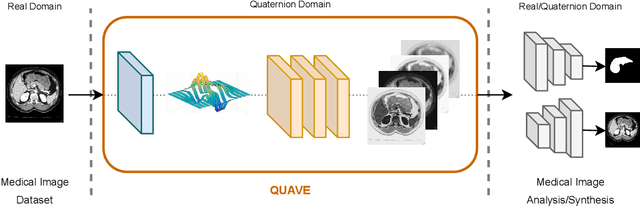
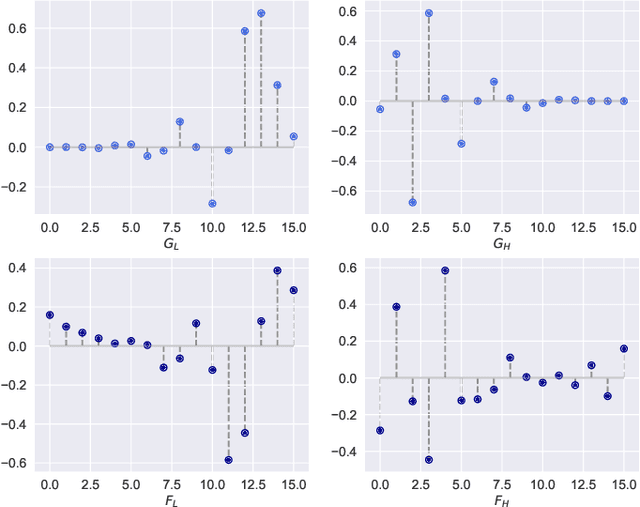
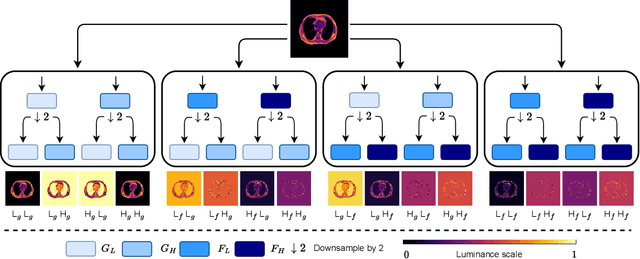
Neural network generalizability is becoming a broad research field due to the increasing availability of datasets from different sources and for various tasks. This issue is even wider when processing medical data, where a lack of methodological standards causes large variations being provided by different imaging centers or acquired with various devices and cofactors. To overcome these limitations, we introduce a novel, generalizable, data- and task-agnostic framework able to extract salient features from medical images. The proposed quaternion wavelet network (QUAVE) can be easily integrated with any pre-existing medical image analysis or synthesis task, and it can be involved with real, quaternion, or hypercomplex-valued models, generalizing their adoption to single-channel data. QUAVE first extracts different sub-bands through the quaternion wavelet transform, resulting in both low-frequency/approximation bands and high-frequency/fine-grained features. Then, it weighs the most representative set of sub-bands to be involved as input to any other neural model for image processing, replacing standard data samples. We conduct an extensive experimental evaluation comprising different datasets, diverse image analysis, and synthesis tasks including reconstruction, segmentation, and modality translation. We also evaluate QUAVE in combination with both real and quaternion-valued models. Results demonstrate the effectiveness and the generalizability of the proposed framework that improves network performance while being flexible to be adopted in manifold scenarios.
StawGAN: Structural-Aware Generative Adversarial Networks for Infrared Image Translation
May 18, 2023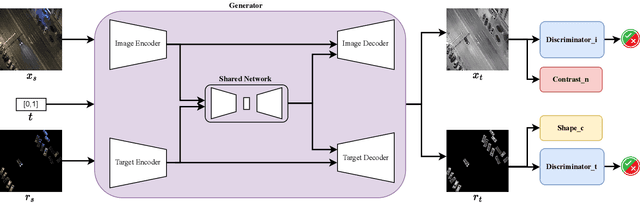



This paper addresses the problem of translating night-time thermal infrared images, which are the most adopted image modalities to analyze night-time scenes, to daytime color images (NTIT2DC), which provide better perceptions of objects. We introduce a novel model that focuses on enhancing the quality of the target generation without merely colorizing it. The proposed structural aware (StawGAN) enables the translation of better-shaped and high-definition objects in the target domain. We test our model on aerial images of the DroneVeichle dataset containing RGB-IR paired images. The proposed approach produces a more accurate translation with respect to other state-of-the-art image translation models. The source code is available at https://github.com/LuigiSigillo/StawGAN
Hypercomplex Image-to-Image Translation
May 04, 2022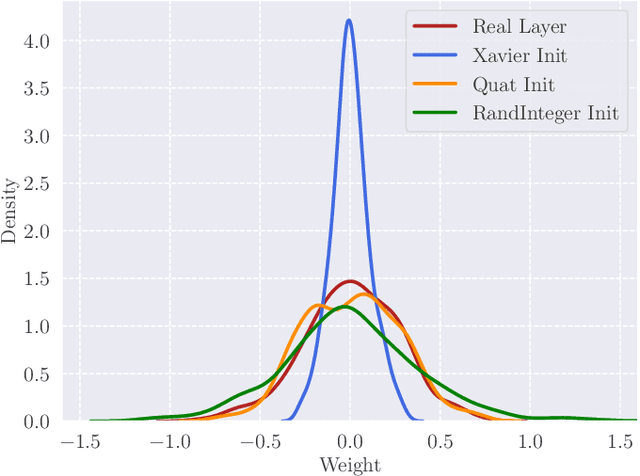
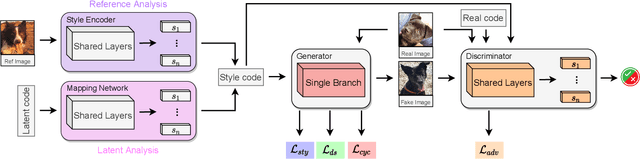


Image-to-image translation (I2I) aims at transferring the content representation from an input domain to an output one, bouncing along different target domains. Recent I2I generative models, which gain outstanding results in this task, comprise a set of diverse deep networks each with tens of million parameters. Moreover, images are usually three-dimensional being composed of RGB channels and common neural models do not take dimensions correlation into account, losing beneficial information. In this paper, we propose to leverage hypercomplex algebra properties to define lightweight I2I generative models capable of preserving pre-existing relations among image dimensions, thus exploiting additional input information. On manifold I2I benchmarks, we show how the proposed Quaternion StarGANv2 and parameterized hypercomplex StarGANv2 (PHStarGANv2) reduce parameters and storage memory amount while ensuring high domain translation performance and good image quality as measured by FID and LPIPS scores. Full code is available at: https://github.com/ispamm/HI2I.