 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Modality Gap Aligns Group-Wise Semantics
Jan 26, 2026In multimodal learning, CLIP has been recognized as the \textit{de facto} method for learning a shared latent space across multiple modalities, placing similar representations close to each other and moving them away from dissimilar ones. Although CLIP-based losses effectively align modalities at the semantic level, the resulting latent spaces often remain only partially shared, revealing a structural mismatch known as the modality gap. While the necessity of addressing this phenomenon remains debated, particularly given its limited impact on instance-wise tasks (e.g., retrieval), we prove that its influence is instead strongly pronounced in group-level tasks (e.g., clustering). To support this claim, we introduce a novel method designed to consistently reduce this discrepancy in two-modal settings, with a straightforward extension to the general $n$-modal case. Through our extensive evaluation, we demonstrate our novel insight: while reducing the gap provides only marginal or inconsistent improvements in traditional instance-wise tasks, it significantly enhances group-wise tasks. These findings may reshape our understanding of the modality gap, highlighting its key role in improving performance on tasks requiring semantic grouping.
Gramian Multimodal Representation Learning and Alignment
Dec 16, 2024



Human perception integrates multiple modalities, such as vision, hearing, and language, into a unified understanding of the surrounding reality. While recent multimodal models have achieved significant progress by aligning pairs of modalities via contrastive learning, their solutions are unsuitable when scaling to multiple modalities. These models typically align each modality to a designated anchor without ensuring the alignment of all modalities with each other, leading to suboptimal performance in tasks requiring a joint understanding of multiple modalities. In this paper, we structurally rethink the pairwise conventional approach to multimodal learning and we present the novel Gramian Representation Alignment Measure (GRAM), which overcomes the above-mentioned limitations. GRAM learns and then aligns $n$ modalities directly in the higher-dimensional space in which modality embeddings lie by minimizing the Gramian volume of the $k$-dimensional parallelotope spanned by the modality vectors, ensuring the geometric alignment of all modalities simultaneously. GRAM can replace cosine similarity in any downstream method, holding for 2 to $n$ modality and providing more meaningful alignment with respect to previous similarity measures. The novel GRAM-based contrastive loss function enhances the alignment of multimodal models in the higher-dimensional embedding space, leading to new state-of-the-art performance in downstream tasks such as video-audio-text retrieval and audio-video classification. The project page, the code, and the pretrained models are available at https://ispamm.github.io/GRAM/.
Lightweight Diffusion Models for Resource-Constrained Semantic Communication
Oct 03, 2024



Recently, generative semantic communication models have proliferated as they are revolutionizing semantic communication frameworks, improving their performance, and opening the way to novel applications. Despite their impressive ability to regenerate content from the compressed semantic information received, generative models pose crucial challenges for communication systems in terms of high memory footprints and heavy computational load. In this paper, we present a novel Quantized GEnerative Semantic COmmunication framework, Q-GESCO. The core method of Q-GESCO is a quantized semantic diffusion model capable of regenerating transmitted images from the received semantic maps while simultaneously reducing computational load and memory footprint thanks to the proposed post-training quantization technique. Q-GESCO is robust to different channel noises and obtains comparable performance to the full precision counterpart in different scenarios saving up to 75% memory and 79% floating point operations. This allows resource-constrained devices to exploit the generative capabilities of Q-GESCO, widening the range of applications and systems for generative semantic communication frameworks. The code is available at https://github.com/ispamm/Q-GESCO.
Rethinking Multi-User Semantic Communications with Deep Generative Models
May 16, 2024



In recent years, novel communication strategies have emerged to face the challenges that the increased number of connected devices and the higher quality of transmitted information are posing. Among them, semantic communication obtained promising results especially when combined with state-of-the-art deep generative models, such as large language or diffusion models, able to regenerate content from extremely compressed semantic information. However, most of these approaches focus on single-user scenarios processing the received content at the receiver on top of conventional communication systems. In this paper, we propose to go beyond these methods by developing a novel generative semantic communication framework tailored for multi-user scenarios. This system assigns the channel to users knowing that the lost information can be filled in with a diffusion model at the receivers. Under this innovative perspective, OFDMA systems should not aim to transmit the largest part of information, but solely the bits necessary to the generative model to semantically regenerate the missing ones. The thorough experimental evaluation shows the capabilities of the novel diffusion model and the effectiveness of the proposed framework, leading towards a GenAI-based next generation of communications.
Language-Oriented Semantic Latent Representation for Image Transmission
May 16, 2024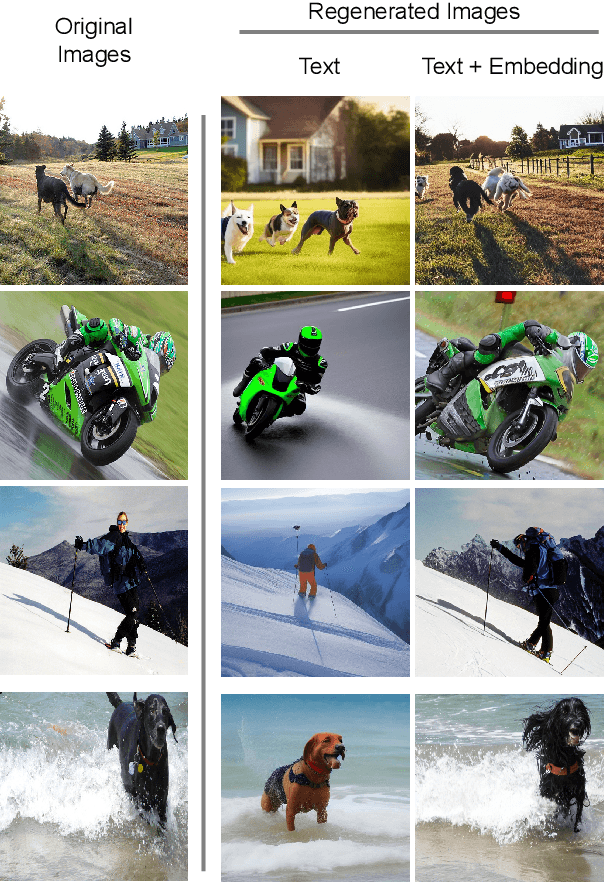

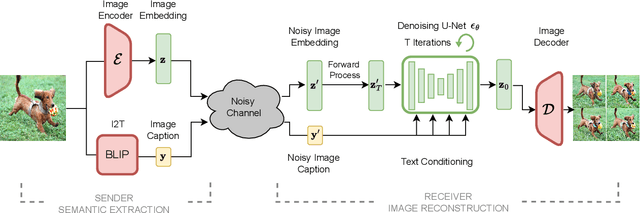
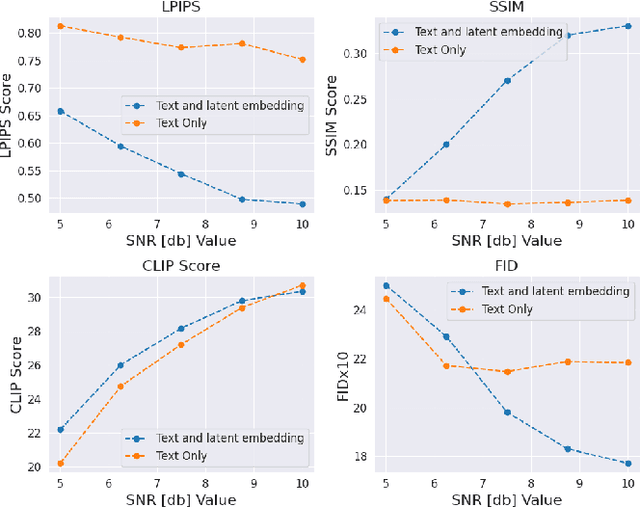
In the new paradigm of semantic communication (SC), the focus is on delivering meanings behind bits by extracting semantic information from raw data. Recent advances in data-to-text models facilitate language-oriented SC, particularly for text-transformed image communication via image-to-text (I2T) encoding and text-to-image (T2I) decoding. However, although semantically aligned, the text is too coarse to precisely capture sophisticated visual features such as spatial locations, color, and texture, incurring a significant perceptual difference between intended and reconstructed images. To address this limitation, in this paper, we propose a novel language-oriented SC framework that communicates both text and a compressed image embedding and combines them using a latent diffusion model to reconstruct the intended image. Experimental results validate the potential of our approach, which transmits only 2.09\% of the original image size while achieving higher perceptual similarities in noisy communication channels compared to a baseline SC method that communicates only through text.The code is available at https://github.com/ispamm/Img2Img-SC/ .
NAF-DPM: A Nonlinear Activation-Free Diffusion Probabilistic Model for Document Enhancement
Apr 08, 2024



Real-world documents may suffer various forms of degradation, often resulting in lower accuracy in optical character recognition (OCR) systems. Therefore, a crucial preprocessing step is essential to eliminate noise while preserving text and key features of documents. In this paper, we propose NAF-DPM, a novel generative framework based on a diffusion probabilistic model (DPM) designed to restore the original quality of degraded documents. While DPMs are recognized for their high-quality generated images, they are also known for their large inference time. To mitigate this problem we provide the DPM with an efficient nonlinear activation-free (NAF) network and we employ as a sampler a fast solver of ordinary differential equations, which can converge in a few iterations. To better preserve text characters, we introduce an additional differentiable module based on convolutional recurrent neural networks, simulating the behavior of an OCR system during training. Experiments conducted on various datasets showcase the superiority of our approach, achieving state-of-the-art performance in terms of pixel-level and perceptual similarity metrics. Furthermore, the results demonstrate a notable character error reduction made by OCR systems when transcribing real-world document images enhanced by our framework. Code and pre-trained models are available at https://github.com/ispamm/NAF-DPM.