 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Oriented Semantic Latent Representation for Image Transmission
Paper and Code
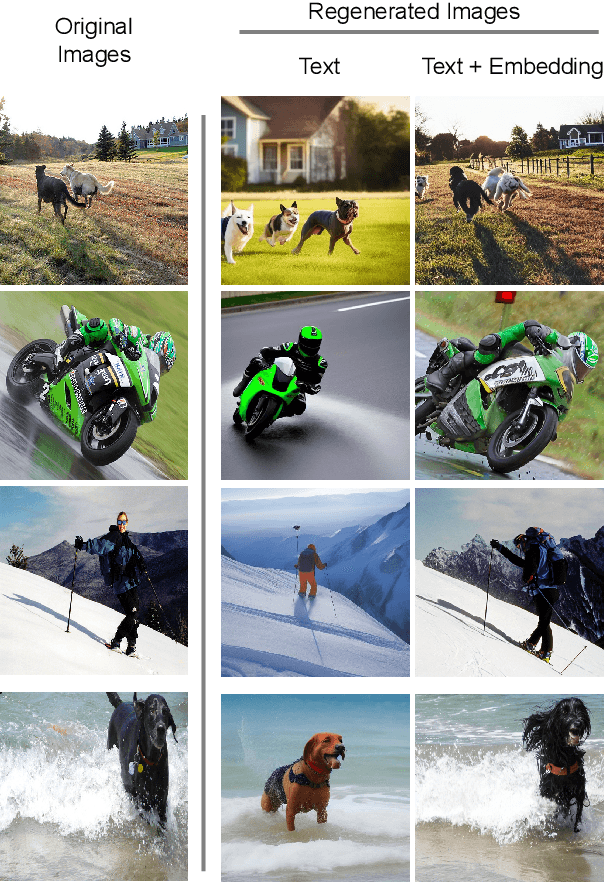

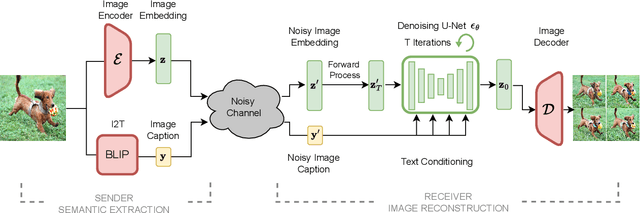
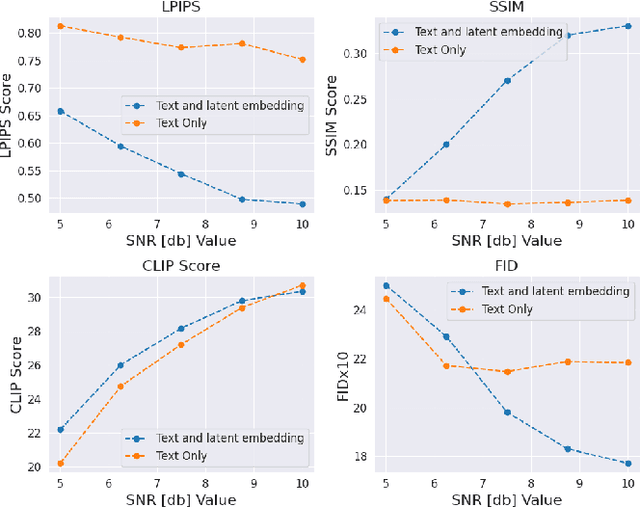
In the new paradigm of semantic communication (SC), the focus is on delivering meanings behind bits by extracting semantic information from raw data. Recent advances in data-to-text models facilitate language-oriented SC, particularly for text-transformed image communication via image-to-text (I2T) encoding and text-to-image (T2I) decoding. However, although semantically aligned, the text is too coarse to precisely capture sophisticated visual features such as spatial locations, color, and texture, incurring a significant perceptual difference between intended and reconstructed images. To address this limitation, in this paper, we propose a novel language-oriented SC framework that communicates both text and a compressed image embedding and combines them using a latent diffusion model to reconstruct the intended image. Experimental results validate the potential of our approach, which transmits only 2.09\% of the original image size while achieving higher perceptual similarities in noisy communication channels compared to a baseline SC method that communicates only through text.The code is available at https://github.com/ispamm/Img2Img-SC/ .