 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Wavelet Diffusion GAN for Image Super-Resolution
Paper and Code
Oct 23, 2024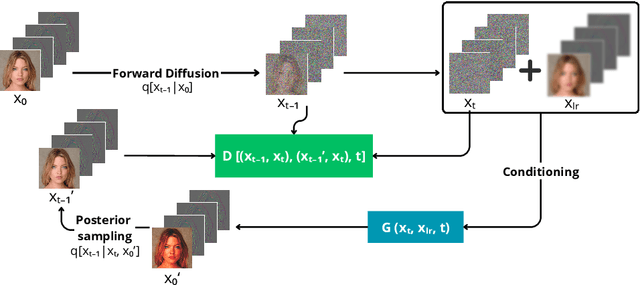
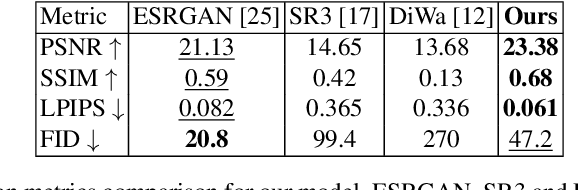
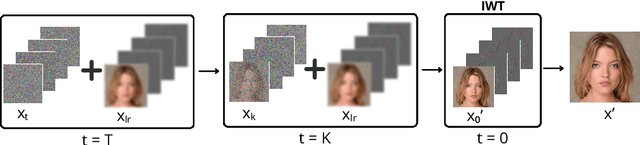

In recent years, diffusion models have emerged as a superior alternative to generative adversarial networks (GANs) for high-fidelity image generation, with wide applications in text-to-image generation, image-to-image translation, and super-resolution. However, their real-time feasibility is hindered by slow training and inference speeds. This study addresses this challenge by proposing a wavelet-based conditional Diffusion GAN scheme for Single-Image Super-Resolution (SISR). Our approach utilizes the diffusion GAN paradigm to reduce the timesteps required by the reverse diffusion process and the Discrete Wavelet Transform (DWT) to achieve dimensionality reduction, decreasing training and inference times significantly. The results of an experimental validation on the CelebA-HQ dataset confirm the effectiveness of our proposed scheme. Our approach outperforms other state-of-the-art methodologies successfully ensuring high-fidelity output while overcoming inherent drawbacks associated with diffusion models in time-sensitive applications.