 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities
Jul 29, 2024Discerning between authentic content and that generated by advanced AI methods has become increasingly challenging. While previous research primarily addresses the detection of fake faces, the identification of generated natural images has only recently surfaced. This prompted the recent exploration of solutions that employ foundation vision-and-language models, like CLIP. However, the CLIP embedding space is optimized for global image-to-text alignment and is not inherently designed for deepfake detection, neglecting the potential benefits of tailored training and local image features. In this study, we propose CoDE (Contrastive Deepfake Embeddings), a novel embedding space specifically designed for deepfake detection. CoDE is trained via contrastive learning by additionally enforcing global-local similarities. To sustain the training of our model, we generate a comprehensive dataset that focuses on images generated by diffusion models and encompasses a collection of 9.2 million images produced by using four different generators. Experimental results demonstrate that CoDE achieves state-of-the-art accuracy on the newly collected dataset, while also showing excellent generalization capabilities to unseen image generators. Our source code, trained models, and collected dataset are publicly available at: https://github.com/aimagelab/CoDE.
Towards Retrieval-Augmented Architectures for Image Captioning
May 21, 2024


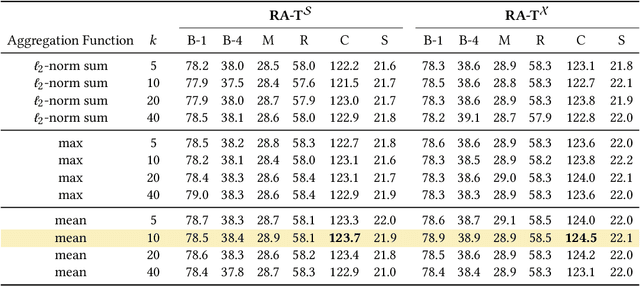
The objective of image captioning models is to bridge the gap between the visual and linguistic modalities by generating natural language descriptions that accurately reflect the content of input images. In recent years, researchers have leveraged deep learning-based models and made advances in the extraction of visual features and the design of multimodal connections to tackle this task. This work presents a novel approach towards developing image captioning models that utilize an external kNN memory to improve the generation process. Specifically, we propose two model variants that incorporate a knowledge retriever component that is based on visual similarities, a differentiable encoder to represent input images, and a kNN-augmented language model to predict tokens based on contextual cues and text retrieved from the external memory. We experimentally validate our approach on COCO and nocaps datasets and demonstrate that incorporating an explicit external memory can significantly enhance the quality of captions, especially with a larger retrieval corpus. This work provides valuable insights into retrieval-augmented captioning models and opens up new avenues for improving image captioning at a larger scale.
Ship in Sight: Diffusion Models for Ship-Image Super Resolution
Mar 27, 2024In recent years, remarkable advancements have been achieved in the field of image generation, primarily driven by the escalating demand for high-quality outcomes across various image generation subtasks, such as inpainting, denoising, and super resolution. A major effort is devoted to exploring the application of super-resolution techniques to enhance the quality of low-resolution images. In this context, our method explores in depth the problem of ship image super resolution, which is crucial for coastal and port surveillance. We investigate the opportunity given by the growing interest in text-to-image diffusion models, taking advantage of the prior knowledge that such foundation models have already learned. In particular, we present a diffusion-model-based architecture that leverages text conditioning during training while being class-aware, to best preserve the crucial details of the ships during the generation of the super-resoluted image. Since the specificity of this task and the scarcity availability of off-the-shelf data, we also introduce a large labeled ship dataset scraped from online ship images, mostly from ShipSpotting\footnote{\url{www.shipspotting.com}} website. Our method achieves more robust results than other deep learning models previously employed for super resolution, as proven by the multiple experiments performed. Moreover, we investigate how this model can benefit downstream tasks, such as classification and object detection, thus emphasizing practical implementation in a real-world scenario. Experimental results show flexibility, reliability, and impressive performance of the proposed framework over state-of-the-art methods for different tasks. The code is available at: https://github.com/LuigiSigillo/ShipinSight .
Adaptive Point Transformer
Jan 26, 2024The recent surge in 3D data acquisition has spurred the development of geometric deep learning models for point cloud processing, boosted by the remarkable success of transformers in natural language processing. While point cloud transformers (PTs) have achieved impressive results recently, their quadratic scaling with respect to the point cloud size poses a significant scalability challenge for real-world applications. To address this issue, we propose the Adaptive Point Cloud Transformer (AdaPT), a standard PT model augmented by an adaptive token selection mechanism. AdaPT dynamically reduces the number of tokens during inference, enabling efficient processing of large point clouds. Furthermore, we introduce a budget mechanism to flexibly adjust the computational cost of the model at inference time without the need for retraining or fine-tuning separate models. Our extensive experimental evaluation on point cloud classification tasks demonstrates that AdaPT significantly reduces computational complexity while maintaining competitive accuracy compared to standard PTs. The code for AdaPT is made publicly available.
MIND: Multi-Task Incremental Network Distillation
Dec 20, 2023
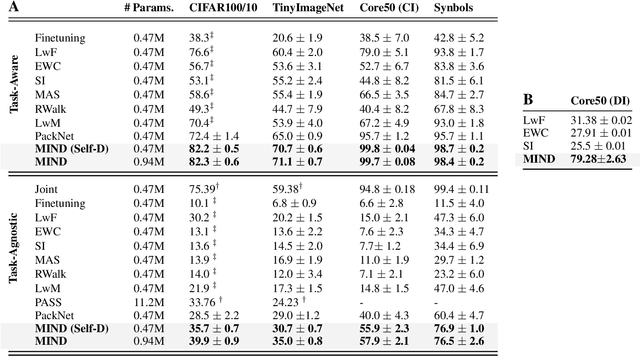


The recent surge of pervasive devices that generate dynamic data streams has underscored the necessity for learning systems to adapt continually to data distributional shifts. To tackle this challenge, the research community has put forth a spectrum of methodologies, including the demanding pursuit of class-incremental learning without replay data. In this study, we present MIND, a parameter isolation method that aims to significantly enhance the performance of replay-free solutions and achieve state-of-the-art results on several widely studied datasets. Our approach introduces two main contributions: two alternative distillation procedures that significantly improve the efficiency of MIND increasing the accumulated knowledge of each sub-network, and the optimization of the BachNorm layers across tasks inside the sub-networks. Overall, MIND outperforms all the state-of-the-art methods for rehearsal-free Class-Incremental learning (with an increment in classification accuracy of approx. +6% on CIFAR-100/10 and +10% on TinyImageNet/10) reaching up to approx. +40% accuracy in Domain-Incremental scenarios. Moreover, we ablated each contribution to demonstrate its impact on performance improvement. Our results showcase the superior performance of MIND indicating its potential for addressing the challenges posed by Class-incremental and Domain-Incremental learning in resource-constrained environments.
DUCK: Distance-based Unlearning via Centroid Kinematics
Dec 04, 2023



Machine Unlearning is rising as a new field, driven by the pressing necessity of ensuring privacy in modern artificial intelligence models. This technique primarily aims to eradicate any residual influence of a specific subset of data from the knowledge acquired by a neural model during its training. This work introduces a novel unlearning algorithm, denoted as Distance-based Unlearning via Centroid Kinematics (DUCK), which employs metric learning to guide the removal of samples matching the nearest incorrect centroid in the embedding space. Evaluation of the algorithm's performance is conducted across various benchmark datasets in two distinct scenarios, class removal, and homogeneous sampling removal, obtaining state-of-the-art performance. We introduce a novel metric, called Adaptive Unlearning Score (AUS), encompassing not only the efficacy of the unlearning process in forgetting target data but also quantifying the performance loss relative to the original model. Moreover, we propose a novel membership inference attack to assess the algorithm's capacity to erase previously acquired knowledge, designed to be adaptable to future methodologies.