 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask and Compress: Efficient Skeleton-based Action Recognition in Continual Learning
Jul 01, 2024



The use of skeletal data allows deep learning models to perform action recognition efficiently and effectively. Herein, we believe that exploring this problem within the context of Continual Learning is crucial. While numerous studies focus on skeleton-based action recognition from a traditional offline perspective, only a handful venture into online approaches. In this respect, we introduce CHARON (Continual Human Action Recognition On skeletoNs), which maintains consistent performance while operating within an efficient framework. Through techniques like uniform sampling, interpolation, and a memory-efficient training stage based on masking, we achieve improved recognition accuracy while minimizing computational overhead. Our experiments on Split NTU-60 and the proposed Split NTU-120 datasets demonstrate that CHARON sets a new benchmark in this domain. The code is available at https://github.com/Sperimental3/CHARON.
Is Retain Set All You Need in Machine Unlearning? Restoring Performance of Unlearned Models with Out-Of-Distribution Images
Apr 19, 2024



In this paper, we introduce Selective-distillation for Class and Architecture-agnostic unleaRning (SCAR), a novel approximate unlearning method. SCAR efficiently eliminates specific information while preserving the model's test accuracy without using a retain set, which is a key component in state-of-the-art approximate unlearning algorithms. Our approach utilizes a modified Mahalanobis distance to guide the unlearning of the feature vectors of the instances to be forgotten, aligning them to the nearest wrong class distribution. Moreover, we propose a distillation-trick mechanism that distills the knowledge of the original model into the unlearning model with out-of-distribution images for retaining the original model's test performance without using any retain set. Importantly, we propose a self-forget version of SCAR that unlearns without having access to the forget set. We experimentally verified the effectiveness of our method, on three public datasets, comparing it with state-of-the-art methods. Our method obtains performance higher than methods that operate without the retain set and comparable w.r.t the best methods that rely on the retain set.
DUCK: Distance-based Unlearning via Centroid Kinematics
Dec 04, 2023



Machine Unlearning is rising as a new field, driven by the pressing necessity of ensuring privacy in modern artificial intelligence models. This technique primarily aims to eradicate any residual influence of a specific subset of data from the knowledge acquired by a neural model during its training. This work introduces a novel unlearning algorithm, denoted as Distance-based Unlearning via Centroid Kinematics (DUCK), which employs metric learning to guide the removal of samples matching the nearest incorrect centroid in the embedding space. Evaluation of the algorithm's performance is conducted across various benchmark datasets in two distinct scenarios, class removal, and homogeneous sampling removal, obtaining state-of-the-art performance. We introduce a novel metric, called Adaptive Unlearning Score (AUS), encompassing not only the efficacy of the unlearning process in forgetting target data but also quantifying the performance loss relative to the original model. Moreover, we propose a novel membership inference attack to assess the algorithm's capacity to erase previously acquired knowledge, designed to be adaptable to future methodologies.
Predicting Tweet Engagement with Graph Neural Networks
May 17, 2023



Social Networks represent one of the most important online sources to share content across a world-scale audience. In this context, predicting whether a post will have any impact in terms of engagement is of crucial importance to drive the profitable exploitation of these media. In the literature, several studies address this issue by leveraging direct features of the posts, typically related to the textual content and the user publishing it. In this paper, we argue that the rise of engagement is also related to another key component, which is the semantic connection among posts published by users in social media. Hence, we propose TweetGage, a Graph Neural Network solution to predict the user engagement based on a novel graph-based model that represents the relationships among posts. To validate our proposal, we focus on the Twitter platform and perform a thorough experimental campaign providing evidence of its quality.
Gated Class-Attention with Cascaded Feature Drift Compensation for Exemplar-free Continual Learning of Vision Transformers
Nov 22, 2022In this paper we propose a new method for exemplar-free class incremental training of ViTs. The main challenge of exemplar-free continual learning is maintaining plasticity of the learner without causing catastrophic forgetting of previously learned tasks. This is often achieved via exemplar replay which can help recalibrate previous task classifiers to the feature drift which occurs when learning new tasks. Exemplar replay, however, comes at the cost of retaining samples from previous tasks which for some applications may not be possible. To address the problem of continual ViT training, we first propose gated class-attention to minimize the drift in the final ViT transformer block. This mask-based gating is applied to class-attention mechanism of the last transformer block and strongly regulates the weights crucial for previous tasks. Secondly, we propose a new method of feature drift compensation that accommodates feature drift in the backbone when learning new tasks. The combination of gated class-attention and cascaded feature drift compensation allows for plasticity towards new tasks while limiting forgetting of previous ones. Extensive experiments performed on CIFAR-100, Tiny-ImageNet and ImageNet100 demonstrate that our method outperforms existing exemplar-free state-of-the-art methods without the need to store any representative exemplars of past tasks.
Explaining Image Enhancement Black-Box Methods through a Path Planning Based Algorithm
Jul 14, 2022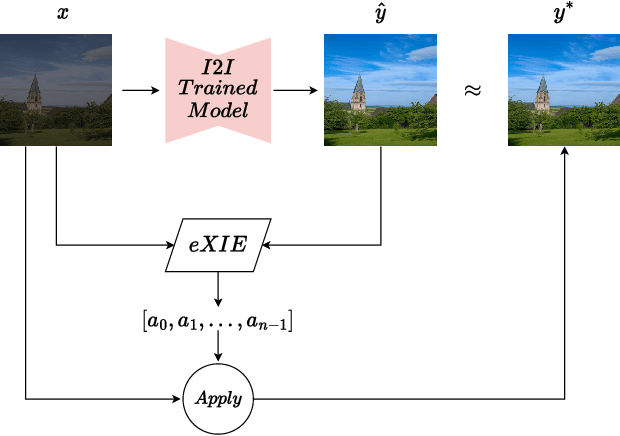
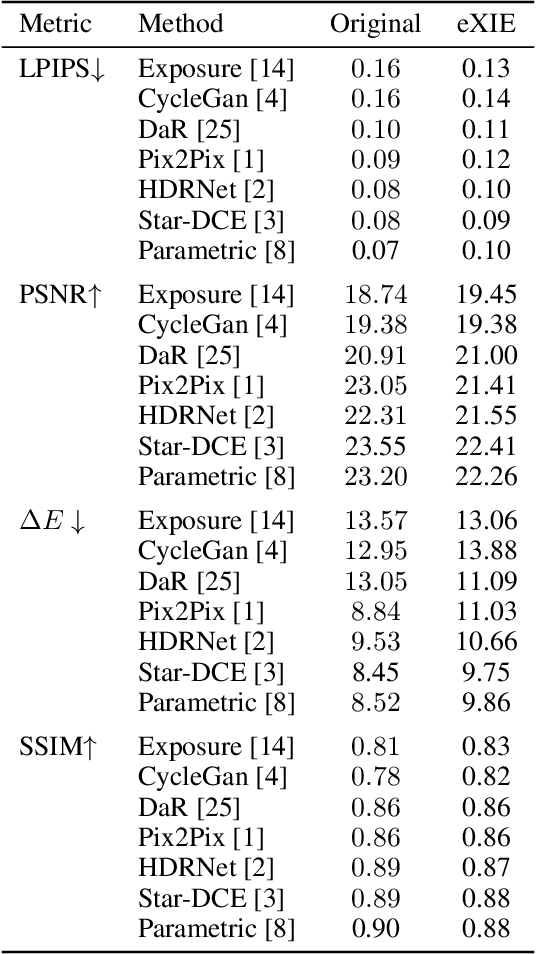
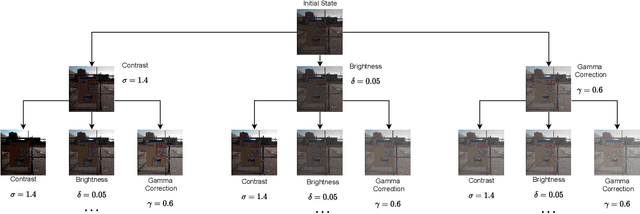
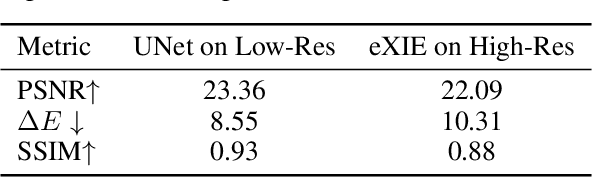
Nowadays, image-to-image translation methods, are the state of the art for the enhancement of natural images. Even if they usually show high performance in terms of accuracy, they often suffer from several limitations such as the generation of artifacts and the scalability to high resolutions. Moreover, their main drawback is the completely black-box approach that does not allow to provide the final user with any insight about the enhancement processes applied. In this paper we present a path planning algorithm which provides a step-by-step explanation of the output produced by state of the art enhancement methods, overcoming black-box limitation. This algorithm, called eXIE, uses a variant of the A* algorithm to emulate the enhancement process of another method through the application of an equivalent sequence of enhancing operators. We applied eXIE to explain the output of several state-of-the-art models trained on the Five-K dataset, obtaining sequences of enhancing operators able to produce very similar results in terms of performance and overcoming the huge limitation of poor interpretability of the best performing algorithms.
Offset equivariant networks and their applications
Jul 01, 2022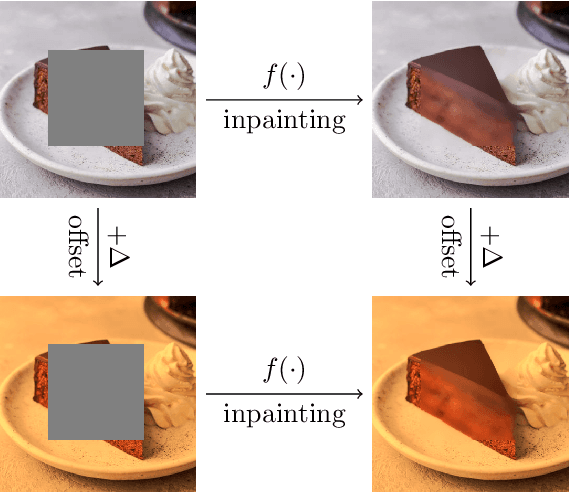
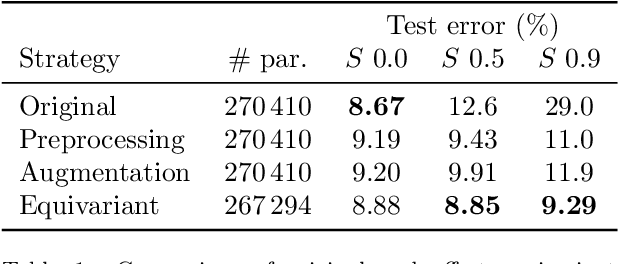

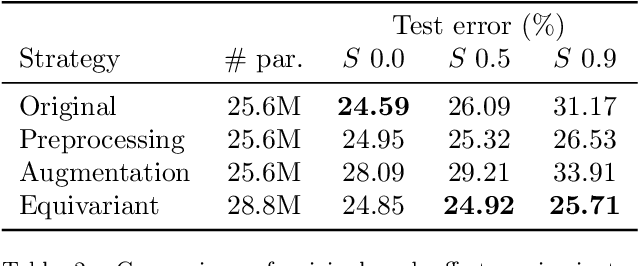
In this paper we present a framework for the design and implementation of offset equivariant networks, that is, neural networks that preserve in their output uniform increments in the input. In a suitable color space this kind of networks achieves equivariance with respect to the photometric transformations that characterize changes in the lighting conditions. We verified the framework on three different problems: image recognition, illuminant estimation, and image inpainting. Our experiments show that the performance of offset equivariant networks are comparable to those in the state of the art on regular data. Differently from conventional networks, however, equivariant networks do behave consistently well when the color of the illuminant changes.
* 13 pages
TreEnhance: An Automatic Tree-Search Based Method for Low-Light Image Enhancement
May 25, 2022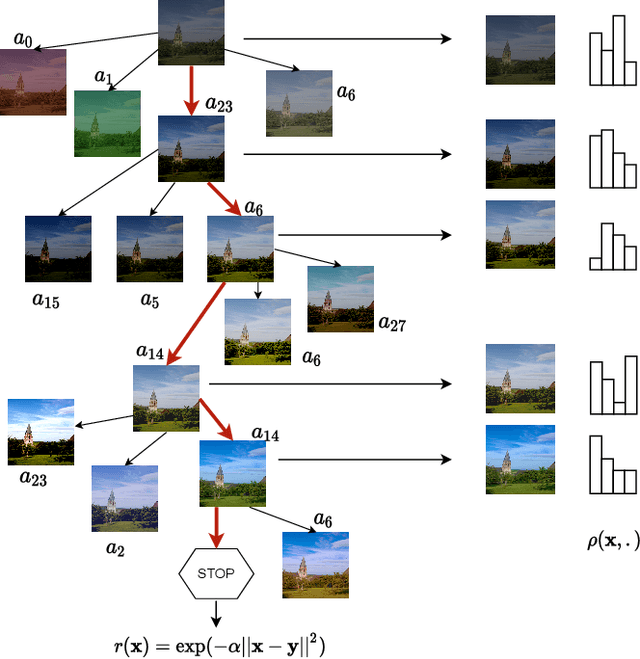
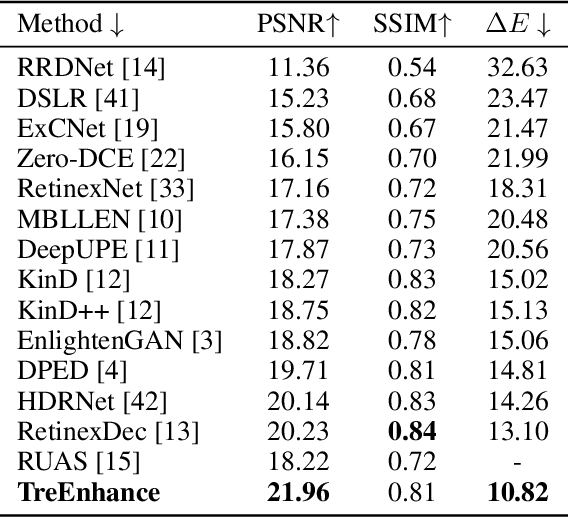
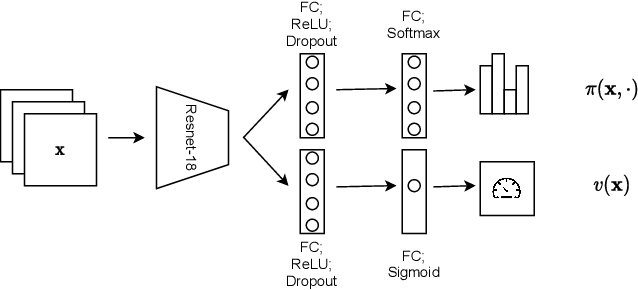

In this paper we present TreEnhance, an automatic method for low-light image enhancement capable of improving the quality of digital images. The method combines tree search theory, and in particular the Monte Carlo Tree Search (MCTS) algorithm, with deep reinforcement learning. Given as input a low-light image, TreEnhance produces as output its enhanced version together with the sequence of image editing operations used to obtain it. The method repeatedly alternates two main phases. In the generation phase a modified version of MCTS explores the space of image editing operations and selects the most promising sequence. In the optimization phase the parameters of a neural network, implementing the enhancement policy, are updated. After training, two different inference solutions are proposed for the enhancement of new images: one is based on MCTS and is more accurate but more time and memory consuming; the other directly applies the learned policy and is faster but slightly less precise. Unlike other methods from the state of the art, TreEnhance does not pose any constraint on the image resolution and can be used in a variety of scenarios with minimal tuning. We tested the method on two datasets: the Low-Light dataset and the Adobe Five-K dataset obtaining good results from both a qualitative and a quantitative point of view.