 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Box-Guided Diffusion for Synthesizing Industrial Images and Segmentation Map
May 06, 2025



Synthetic dataset generation in Computer Vision, particularly for industrial applications, is still underexplored. Industrial defect segmentation, for instance, requires highly accurate labels, yet acquiring such data is costly and time-consuming. To address this challenge, we propose a novel diffusion-based pipeline for generating high-fidelity industrial datasets with minimal supervision. Our approach conditions the diffusion model on enriched bounding box representations to produce precise segmentation masks, ensuring realistic and accurately localized defect synthesis. Compared to existing layout-conditioned generative methods, our approach improves defect consistency and spatial accuracy. We introduce two quantitative metrics to evaluate the effectiveness of our method and assess its impact on a downstream segmentation task trained on real and synthetic data. Our results demonstrate that diffusion-based synthesis can bridge the gap between artificial and real-world industrial data, fostering more reliable and cost-efficient segmentation models. The code is publicly available at https://github.com/covisionlab/diffusion_labeling.
Dynamic Label Injection for Imbalanced Industrial Defect Segmentation
Aug 19, 2024In this work, we propose a simple yet effective method to tackle the problem of imbalanced multi-class semantic segmentation in deep learning systems. One of the key properties for a good training set is the balancing among the classes. When the input distribution is heavily imbalanced in the number of instances, the learning process could be hindered or difficult to carry on. To this end, we propose a Dynamic Label Injection (DLI) algorithm to impose a uniform distribution in the input batch. Our algorithm computes the current batch defect distribution and re-balances it by transferring defects using a combination of Poisson-based seamless image cloning and cut-paste techniques. A thorough experimental section on the Magnetic Tiles dataset shows better results of DLI compared to other balancing loss approaches also in the challenging weakly-supervised setup. The code is available at https://github.com/covisionlab/dynamic-label-injection.git
MIND: Multi-Task Incremental Network Distillation
Dec 20, 2023
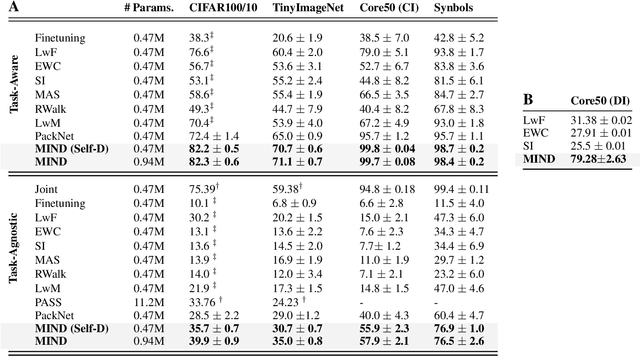


The recent surge of pervasive devices that generate dynamic data streams has underscored the necessity for learning systems to adapt continually to data distributional shifts. To tackle this challenge, the research community has put forth a spectrum of methodologies, including the demanding pursuit of class-incremental learning without replay data. In this study, we present MIND, a parameter isolation method that aims to significantly enhance the performance of replay-free solutions and achieve state-of-the-art results on several widely studied datasets. Our approach introduces two main contributions: two alternative distillation procedures that significantly improve the efficiency of MIND increasing the accumulated knowledge of each sub-network, and the optimization of the BachNorm layers across tasks inside the sub-networks. Overall, MIND outperforms all the state-of-the-art methods for rehearsal-free Class-Incremental learning (with an increment in classification accuracy of approx. +6% on CIFAR-100/10 and +10% on TinyImageNet/10) reaching up to approx. +40% accuracy in Domain-Incremental scenarios. Moreover, we ablated each contribution to demonstrate its impact on performance improvement. Our results showcase the superior performance of MIND indicating its potential for addressing the challenges posed by Class-incremental and Domain-Incremental learning in resource-constrained environments.
DUCK: Distance-based Unlearning via Centroid Kinematics
Dec 04, 2023



Machine Unlearning is rising as a new field, driven by the pressing necessity of ensuring privacy in modern artificial intelligence models. This technique primarily aims to eradicate any residual influence of a specific subset of data from the knowledge acquired by a neural model during its training. This work introduces a novel unlearning algorithm, denoted as Distance-based Unlearning via Centroid Kinematics (DUCK), which employs metric learning to guide the removal of samples matching the nearest incorrect centroid in the embedding space. Evaluation of the algorithm's performance is conducted across various benchmark datasets in two distinct scenarios, class removal, and homogeneous sampling removal, obtaining state-of-the-art performance. We introduce a novel metric, called Adaptive Unlearning Score (AUS), encompassing not only the efficacy of the unlearning process in forgetting target data but also quantifying the performance loss relative to the original model. Moreover, we propose a novel membership inference attack to assess the algorithm's capacity to erase previously acquired knowledge, designed to be adaptable to future methodologies.
Dissecting Continual Learning a Structural and Data Analysis
Jan 03, 2023


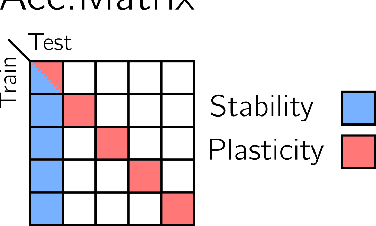
Continual Learning (CL) is a field dedicated to devise algorithms able to achieve lifelong learning. Overcoming the knowledge disruption of previously acquired concepts, a drawback affecting deep learning models and that goes by the name of catastrophic forgetting, is a hard challenge. Currently, deep learning methods can attain impressive results when the data modeled does not undergo a considerable distributional shift in subsequent learning sessions, but whenever we expose such systems to this incremental setting, performance drop very quickly. Overcoming this limitation is fundamental as it would allow us to build truly intelligent systems showing stability and plasticity. Secondly, it would allow us to overcome the onerous limitation of retraining these architectures from scratch with the new updated data. In this thesis, we tackle the problem from multiple directions. In a first study, we show that in rehearsal-based techniques (systems that use memory buffer), the quantity of data stored in the rehearsal buffer is a more important factor over the quality of the data. Secondly, we propose one of the early works of incremental learning on ViTs architectures, comparing functional, weight and attention regularization approaches and propose effective novel a novel asymmetric loss. At the end we conclude with a study on pretraining and how it affects the performance in Continual Learning, raising some questions about the effective progression of the field. We then conclude with some future directions and closing remarks.
Simpler is Better: off-the-shelf Continual Learning Through Pretrained Backbones
May 03, 2022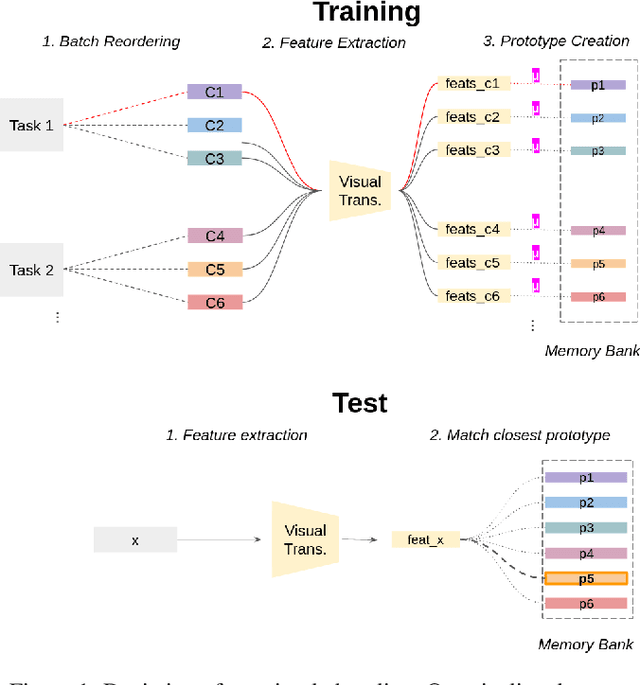
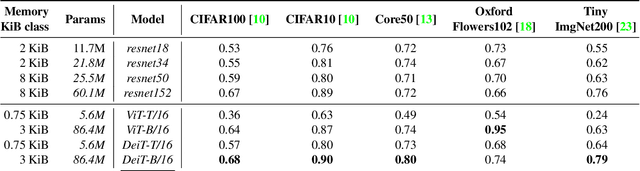
In this short paper, we propose a baseline (off-the-shelf) for Continual Learning of Computer Vision problems, by leveraging the power of pretrained models. By doing so, we devise a simple approach achieving strong performance for most of the common benchmarks. Our approach is fast since requires no parameters updates and has minimal memory requirements (order of KBytes). In particular, the "training" phase reorders data and exploit the power of pretrained models to compute a class prototype and fill a memory bank. At inference time we match the closest prototype through a knn-like approach, providing us the prediction. We will see how this naive solution can act as an off-the-shelf continual learning system. In order to better consolidate our results, we compare the devised pipeline with common CNN models and show the superiority of Vision Transformers, suggesting that such architectures have the ability to produce features of higher quality. Moreover, this simple pipeline, raises the same questions raised by previous works \cite{gdumb} on the effective progresses made by the CL community especially in the dataset considered and the usage of pretrained models. Code is live at https://github.com/francesco-p/off-the-shelf-cl
Towards Exemplar-Free Continual Learning in Vision Transformers: an Account of Attention, Functional and Weight Regularization
Mar 28, 2022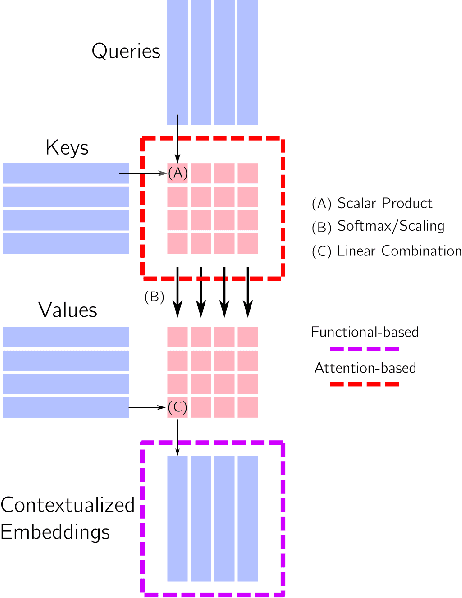
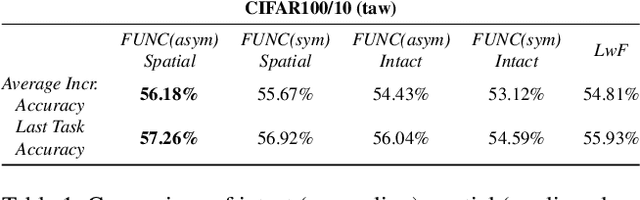
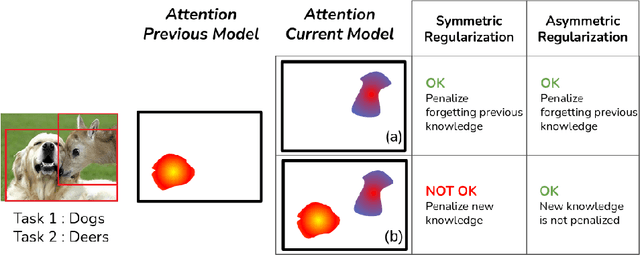
In this paper, we investigate the continual learning of Vision Transformers (ViT) for the challenging exemplar-free scenario, with special focus on how to efficiently distill the knowledge of its crucial self-attention mechanism (SAM). Our work takes an initial step towards a surgical investigation of SAM for designing coherent continual learning methods in ViTs. We first carry out an evaluation of established continual learning regularization techniques. We then examine the effect of regularization when applied to two key enablers of SAM: (a) the contextualized embedding layers, for their ability to capture well-scaled representations with respect to the values, and (b) the prescaled attention maps, for carrying value-independent global contextual information. We depict the perks of each distilling strategy on two image recognition benchmarks (CIFAR100 and ImageNet-32) -- while (a) leads to a better overall accuracy, (b) helps enhance the rigidity by maintaining competitive performances. Furthermore, we identify the limitation imposed by the symmetric nature of regularization losses. To alleviate this, we propose an asymmetric variant and apply it to the pooled output distillation (POD) loss adapted for ViTs. Our experiments confirm that introducing asymmetry to POD boosts its plasticity while retaining stability across (a) and (b). Moreover, we acknowledge low forgetting measures for all the compared methods, indicating that ViTs might be naturally inclined continual learner
More Is Better: An Analysis of Instance Quantity/Quality Trade-off in Rehearsal-based Continual Learning
Jun 04, 2021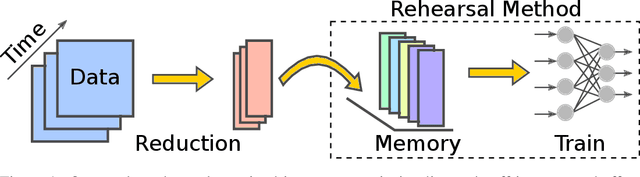
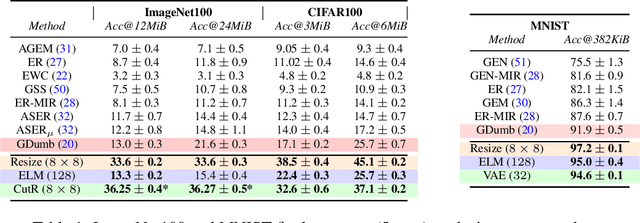
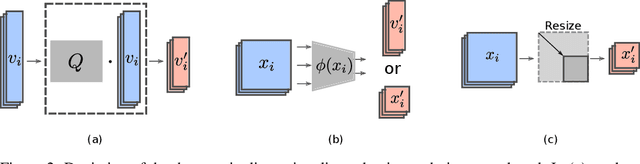
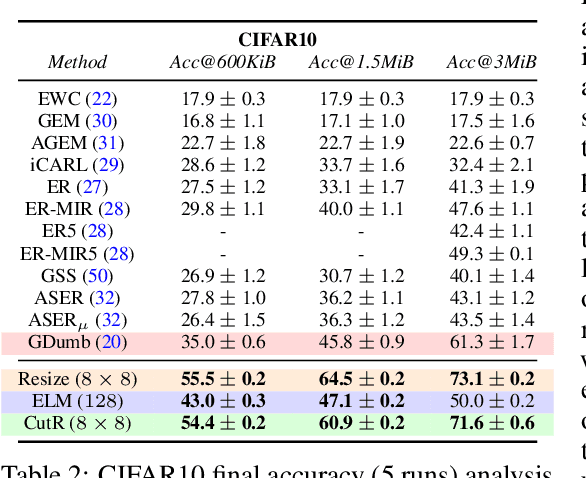
The design of machines and algorithms capable of learning in a dynamically changing environment has become an increasingly topical problem with the increase of the size and heterogeneity of data available to learning systems. As a consequence, the key issue of Continual Learning has become that of addressing the stability-plasticity dilemma of connectionist systems, as they need to adapt their model without forgetting previously acquired knowledge. Within this context, rehearsal-based methods i.e., solutions in where the learner exploits memory to revisit past data, has proven to be very effective, leading to performance at the state-of-the-art. In our study, we propose an analysis of the memory quantity/quality trade-off adopting various data reduction approaches to increase the number of instances storable in memory. In particular, we investigate complex instance compression techniques such as deep encoders, but also trivial approaches such as image resizing and linear dimensionality reduction. Our findings suggest that the optimal trade-off is severely skewed toward instance quantity, where rehearsal approaches with several heavily compressed instances easily outperform state-of-the-art approaches with the same amount of memory at their disposal. Further, in high memory configurations, deep approaches extracting spatial structure combined with extreme resizing (of the order of $8\times8$ images) yield the best results, while in memory-constrained configurations where deep approaches cannot be used due to their memory requirement in training, Extreme Learning Machines (ELM) offer a clear advantage.
Unsupervised semantic discovery through visual patterns detection
Feb 24, 2021
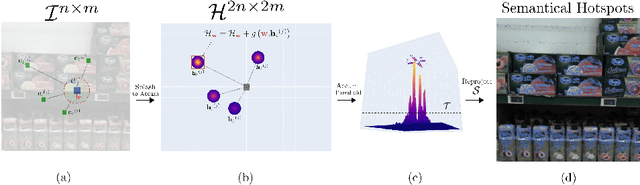
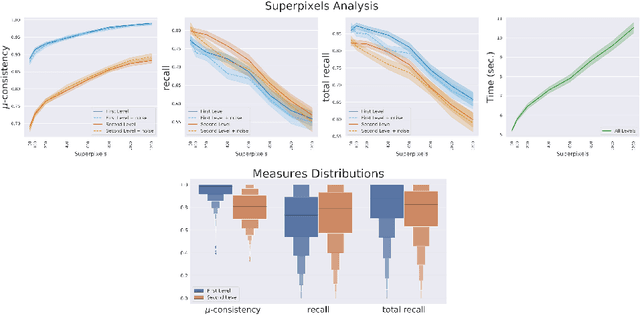

We propose a new fast fully unsupervised method to discover semantic patterns. Our algorithm is able to hierarchically find visual categories and produce a segmentation mask where previous methods fail. Through the modeling of what is a visual pattern in an image, we introduce the notion of "semantic levels" and devise a conceptual framework along with measures and a dedicated benchmark dataset for future comparisons. Our algorithm is composed by two phases. A filtering phase, which selects semantical hotsposts by means of an accumulator space, then a clustering phase which propagates the semantic properties of the hotspots on a superpixels basis. We provide both qualitative and quantitative experimental validation, achieving optimal results in terms of robustness to noise and semantic consistency. We also made code and dataset publicly available.