 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Exemplar-Free Continual Learning in Vision Transformers: an Account of Attention, Functional and Weight Regularization
Paper and Code
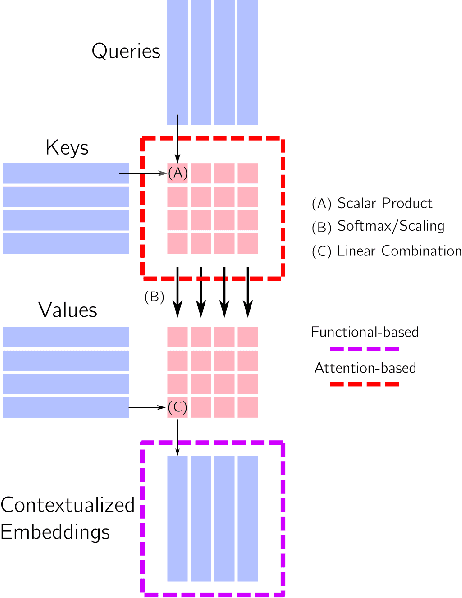
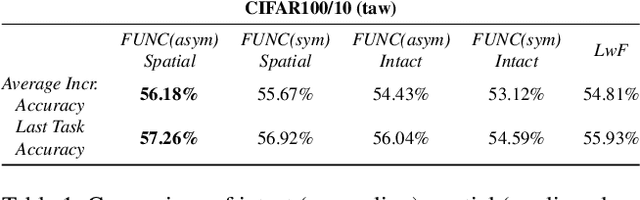
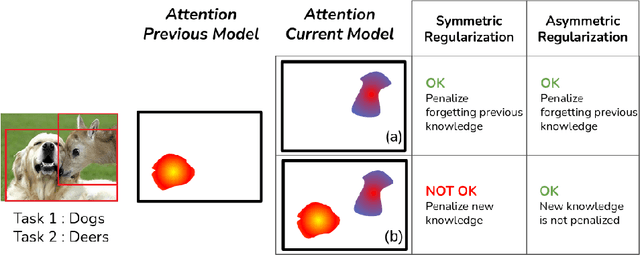
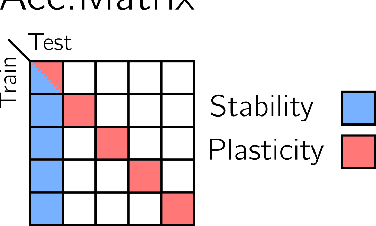
In this paper, we investigate the continual learning of Vision Transformers (ViT) for the challenging exemplar-free scenario, with special focus on how to efficiently distill the knowledge of its crucial self-attention mechanism (SAM). Our work takes an initial step towards a surgical investigation of SAM for designing coherent continual learning methods in ViTs. We first carry out an evaluation of established continual learning regularization techniques. We then examine the effect of regularization when applied to two key enablers of SAM: (a) the contextualized embedding layers, for their ability to capture well-scaled representations with respect to the values, and (b) the prescaled attention maps, for carrying value-independent global contextual information. We depict the perks of each distilling strategy on two image recognition benchmarks (CIFAR100 and ImageNet-32) -- while (a) leads to a better overall accuracy, (b) helps enhance the rigidity by maintaining competitive performances. Furthermore, we identify the limitation imposed by the symmetric nature of regularization losses. To alleviate this, we propose an asymmetric variant and apply it to the pooled output distillation (POD) loss adapted for ViTs. Our experiments confirm that introducing asymmetry to POD boosts its plasticity while retaining stability across (a) and (b). Moreover, we acknowledge low forgetting measures for all the compared methods, indicating that ViTs might be naturally inclined continual learner