 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Generation via Spectral Diffusion
Feb 29, 2024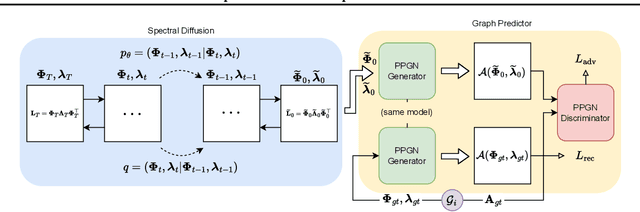
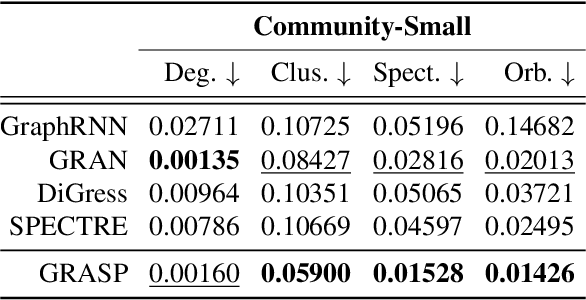
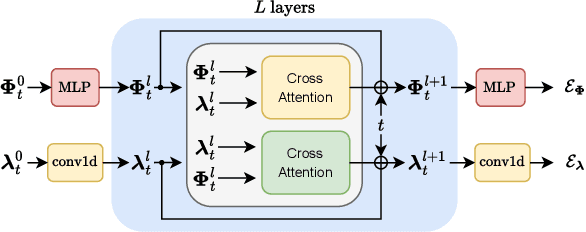
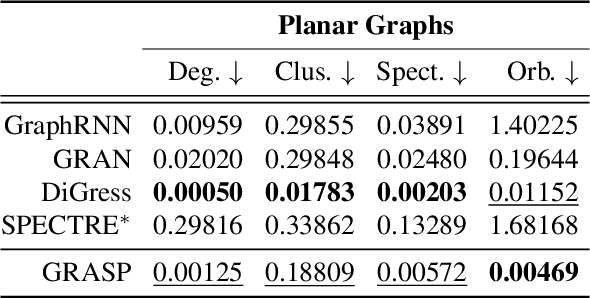
In this paper, we present GRASP, a novel graph generative model based on 1) the spectral decomposition of the graph Laplacian matrix and 2) a diffusion process. Specifically, we propose to use a denoising model to sample eigenvectors and eigenvalues from which we can reconstruct the graph Laplacian and adjacency matrix. Our permutation invariant model can also handle node features by concatenating them to the eigenvectors of each node. Using the Laplacian spectrum allows us to naturally capture the structural characteristics of the graph and work directly in the node space while avoiding the quadratic complexity bottleneck that limits the applicability of other methods. This is achieved by truncating the spectrum, which as we show in our experiments results in a faster yet accurate generative process. An extensive set of experiments on both synthetic and real world graphs demonstrates the strengths of our model against state-of-the-art alternatives.
GNN-LoFI: a Novel Graph Neural Network through Localized Feature-based Histogram Intersection
Jan 17, 2024Graph neural networks are increasingly becoming the framework of choice for graph-based machine learning. In this paper, we propose a new graph neural network architecture that substitutes classical message passing with an analysis of the local distribution of node features. To this end, we extract the distribution of features in the egonet for each local neighbourhood and compare them against a set of learned label distributions by taking the histogram intersection kernel. The similarity information is then propagated to other nodes in the network, effectively creating a message passing-like mechanism where the message is determined by the ensemble of the features. We perform an ablation study to evaluate the network's performance under different choices of its hyper-parameters. Finally, we test our model on standard graph classification and regression benchmarks, and we find that it outperforms widely used alternative approaches, including both graph kernels and graph neural networks.
Deep Demosaicing for Polarimetric Filter Array Cameras
Nov 24, 2022Polarisation Filter Array (PFA) cameras allow the analysis of light polarisation state in a simple and cost-effective manner. Such filter arrays work as the Bayer pattern for colour cameras, sharing similar advantages and drawbacks. Among the others, the raw image must be demosaiced considering the local variations of the PFA and the characteristics of the imaged scene. Non-linear effects, like the cross-talk among neighbouring pixels, are difficult to explicitly model and suggest the potential advantage of a data-driven learning approach. However, the PFA cannot be removed from the sensor, making it difficult to acquire the ground-truth polarization state for training. In this work we propose a novel CNN-based model which directly demosaics the raw camera image to a per-pixel Stokes vector. Our contribution is twofold. First, we propose a network architecture composed by a sequence of Mosaiced Convolutions operating coherently with the local arrangement of the different filters. Second, we introduce a new method, employing a consumer LCD screen, to effectively acquire real-world data for training. The process is designed to be invariant by monitor gamma and external lighting conditions. We extensively compared our method against algorithmic and learning-based demosaicing techniques, obtaining a consistently lower error especially in terms of polarisation angle.
Towards Exemplar-Free Continual Learning in Vision Transformers: an Account of Attention, Functional and Weight Regularization
Mar 28, 2022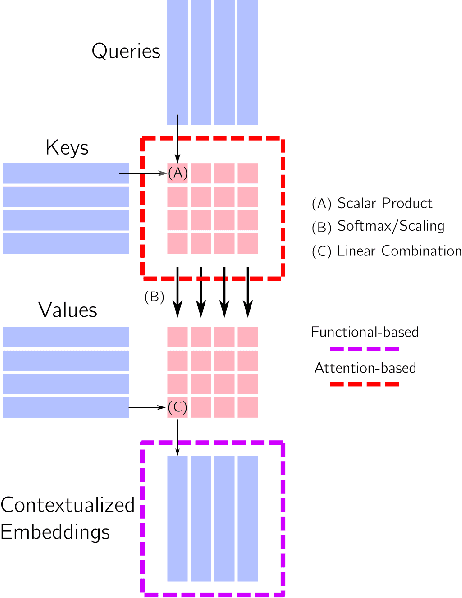
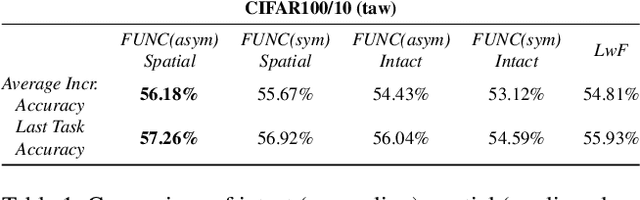
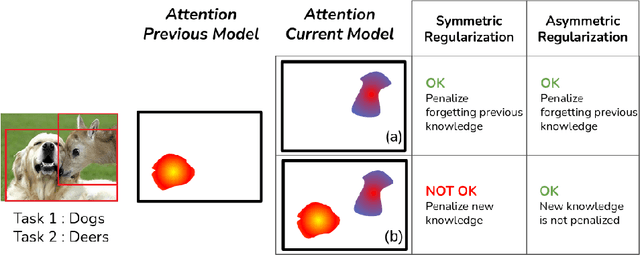
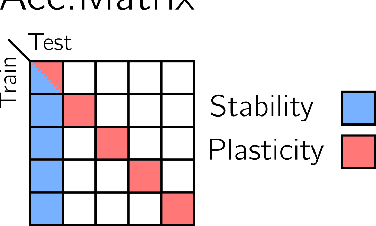
In this paper, we investigate the continual learning of Vision Transformers (ViT) for the challenging exemplar-free scenario, with special focus on how to efficiently distill the knowledge of its crucial self-attention mechanism (SAM). Our work takes an initial step towards a surgical investigation of SAM for designing coherent continual learning methods in ViTs. We first carry out an evaluation of established continual learning regularization techniques. We then examine the effect of regularization when applied to two key enablers of SAM: (a) the contextualized embedding layers, for their ability to capture well-scaled representations with respect to the values, and (b) the prescaled attention maps, for carrying value-independent global contextual information. We depict the perks of each distilling strategy on two image recognition benchmarks (CIFAR100 and ImageNet-32) -- while (a) leads to a better overall accuracy, (b) helps enhance the rigidity by maintaining competitive performances. Furthermore, we identify the limitation imposed by the symmetric nature of regularization losses. To alleviate this, we propose an asymmetric variant and apply it to the pooled output distillation (POD) loss adapted for ViTs. Our experiments confirm that introducing asymmetry to POD boosts its plasticity while retaining stability across (a) and (b). Moreover, we acknowledge low forgetting measures for all the compared methods, indicating that ViTs might be naturally inclined continual learner
Graph Kernel Neural Networks
Dec 14, 2021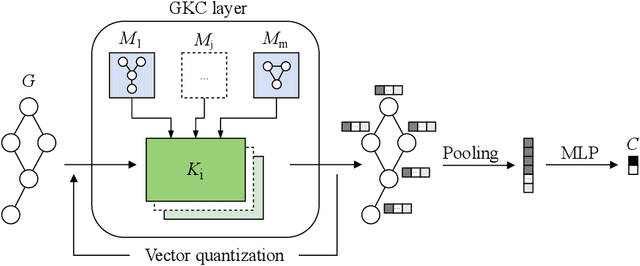
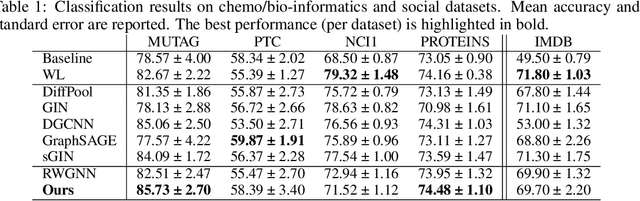

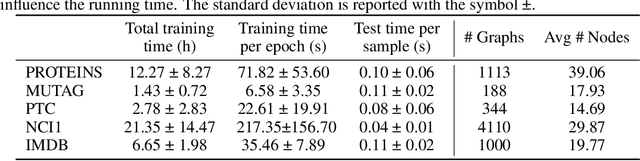
The convolution operator at the core of many modern neural architectures can effectively be seen as performing a dot product between an input matrix and a filter. While this is readily applicable to data such as images, which can be represented as regular grids in the Euclidean space, extending the convolution operator to work on graphs proves more challenging, due to their irregular structure. In this paper, we propose to use graph kernels, i.e., kernel functions that compute an inner product on graphs, to extend the standard convolution operator to the graph domain. This allows us to define an entirely structural model that does not require computing the embedding of the input graph. Our architecture allows to plug-in any type and number of graph kernels and has the added benefit of providing some interpretability in terms of the structural masks that are learned during the training process, similarly to what happens for convolutional masks in traditional convolutional neural networks. We perform an extensive ablation study to investigate the impact of the model hyper-parameters and we show that our model achieves competitive performance on standard graph classification datasets.
More Is Better: An Analysis of Instance Quantity/Quality Trade-off in Rehearsal-based Continual Learning
Jun 04, 2021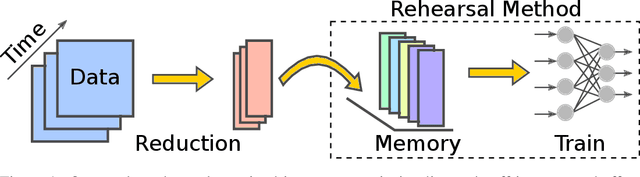
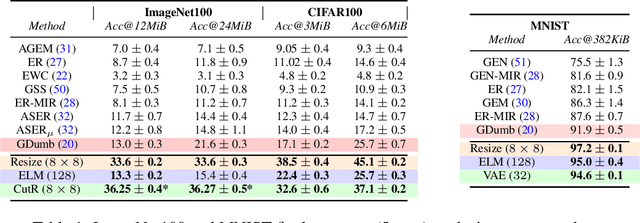
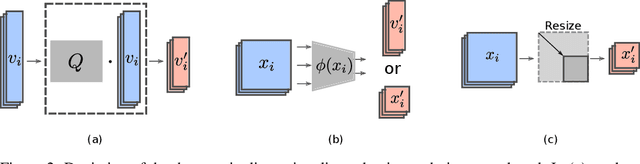
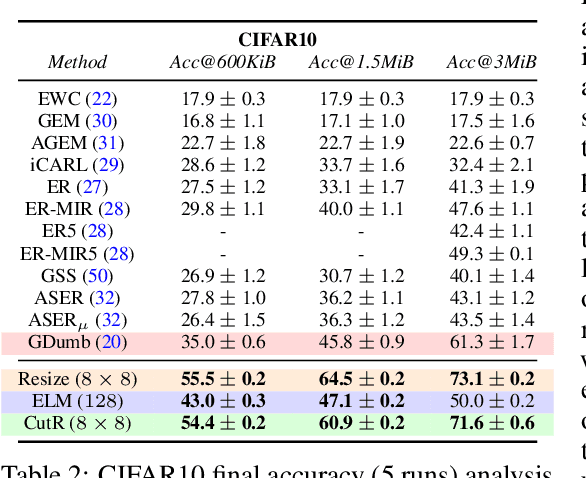
The design of machines and algorithms capable of learning in a dynamically changing environment has become an increasingly topical problem with the increase of the size and heterogeneity of data available to learning systems. As a consequence, the key issue of Continual Learning has become that of addressing the stability-plasticity dilemma of connectionist systems, as they need to adapt their model without forgetting previously acquired knowledge. Within this context, rehearsal-based methods i.e., solutions in where the learner exploits memory to revisit past data, has proven to be very effective, leading to performance at the state-of-the-art. In our study, we propose an analysis of the memory quantity/quality trade-off adopting various data reduction approaches to increase the number of instances storable in memory. In particular, we investigate complex instance compression techniques such as deep encoders, but also trivial approaches such as image resizing and linear dimensionality reduction. Our findings suggest that the optimal trade-off is severely skewed toward instance quantity, where rehearsal approaches with several heavily compressed instances easily outperform state-of-the-art approaches with the same amount of memory at their disposal. Further, in high memory configurations, deep approaches extracting spatial structure combined with extreme resizing (of the order of $8\times8$ images) yield the best results, while in memory-constrained configurations where deep approaches cannot be used due to their memory requirement in training, Extreme Learning Machines (ELM) offer a clear advantage.
Unsupervised semantic discovery through visual patterns detection
Feb 24, 2021
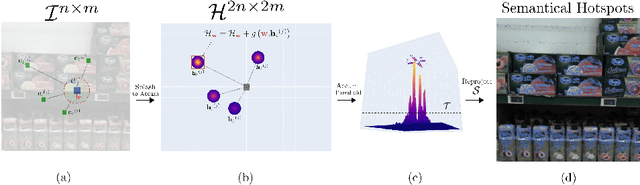
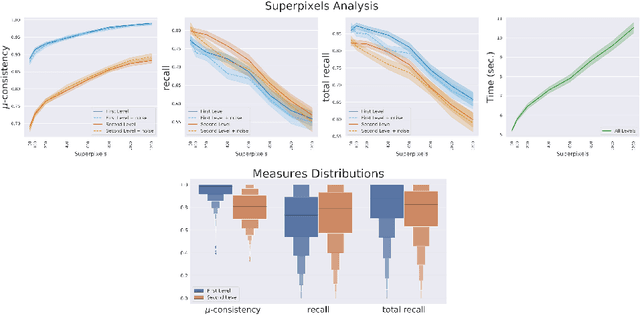

We propose a new fast fully unsupervised method to discover semantic patterns. Our algorithm is able to hierarchically find visual categories and produce a segmentation mask where previous methods fail. Through the modeling of what is a visual pattern in an image, we introduce the notion of "semantic levels" and devise a conceptual framework along with measures and a dedicated benchmark dataset for future comparisons. Our algorithm is composed by two phases. A filtering phase, which selects semantical hotsposts by means of an accumulator space, then a clustering phase which propagates the semantic properties of the hotspots on a superpixels basis. We provide both qualitative and quantitative experimental validation, achieving optimal results in terms of robustness to noise and semantic consistency. We also made code and dataset publicly available.
Partial Functional Correspondence
Dec 22, 2015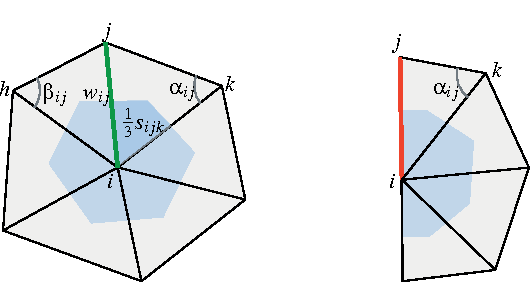
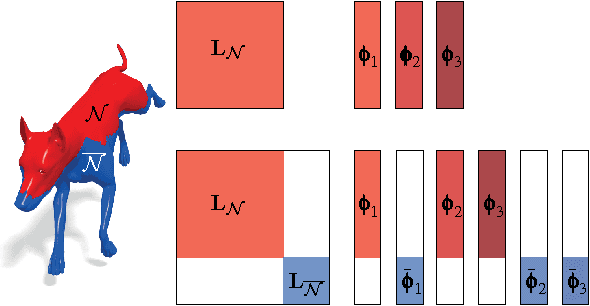
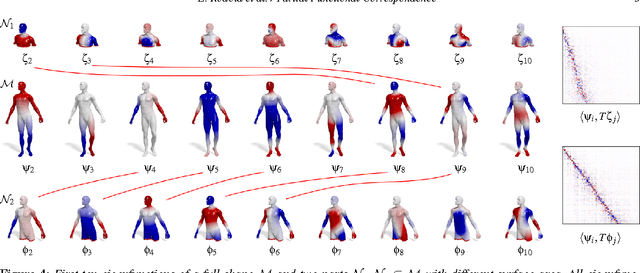
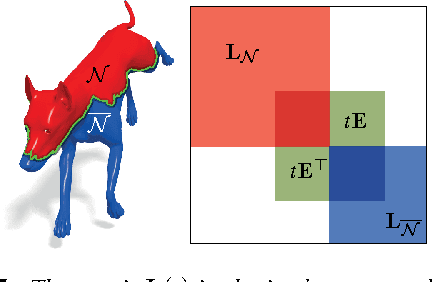
In this paper, we propose a method for computing partial functional correspondence between non-rigid shapes. We use perturbation analysis to show how removal of shape parts changes the Laplace-Beltrami eigenfunctions, and exploit it as a prior on the spectral representation of the correspondence. Corresponding parts are optimization variables in our problem and are used to weight the functional correspondence; we are looking for the largest and most regular (in the Mumford-Shah sense) parts that minimize correspondence distortion. We show that our approach can cope with very challenging correspondence settings.