 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORABLES: A Benchmark for Assessing Abstract Moral Reasoning in LLMs with Fables
Sep 15, 2025As LLMs excel on standard reading comprehension benchmarks, attention is shifting toward evaluating their capacity for complex abstract reasoning and inference. Literature-based benchmarks, with their rich narrative and moral depth, provide a compelling framework for evaluating such deeper comprehension skills. Here, we present MORABLES, a human-verified benchmark built from fables and short stories drawn from historical literature. The main task is structured as multiple-choice questions targeting moral inference, with carefully crafted distractors that challenge models to go beyond shallow, extractive question answering. To further stress-test model robustness, we introduce adversarial variants designed to surface LLM vulnerabilities and shortcuts due to issues such as data contamination. Our findings show that, while larger models outperform smaller ones, they remain susceptible to adversarial manipulation and often rely on superficial patterns rather than true moral reasoning. This brittleness results in significant self-contradiction, with the best models refuting their own answers in roughly 20% of cases depending on the framing of the moral choice. Interestingly, reasoning-enhanced models fail to bridge this gap, suggesting that scale - not reasoning ability - is the primary driver of performance.
Stop overkilling simple tasks with black-box models and use transparent models instead
Feb 06, 2023
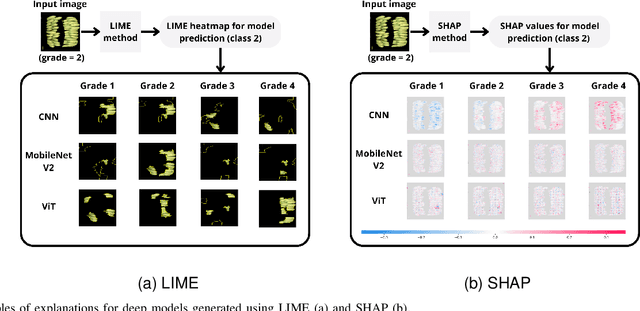
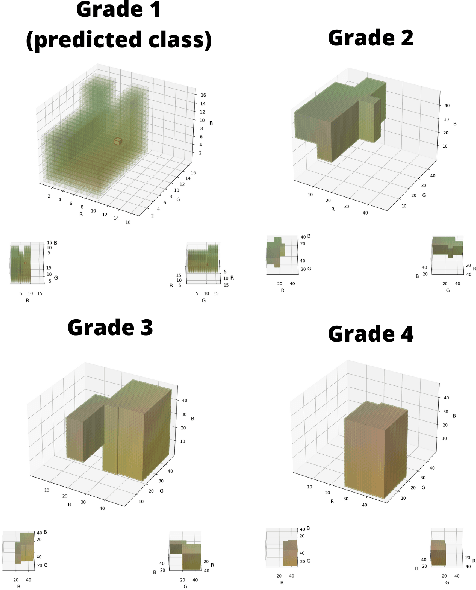
In recent years, the employment of deep learning methods has led to several significant breakthroughs in artificial intelligence. Different from traditional machine learning models, deep learning-based approaches are able to extract features autonomously from raw data. This allows for bypassing the feature engineering process, which is generally considered to be both error-prone and tedious. Moreover, deep learning strategies often outperform traditional models in terms of accuracy.
Fruit Ripeness Classification: a Survey
Dec 29, 2022Fruit is a key crop in worldwide agriculture feeding millions of people. The standard supply chain of fruit products involves quality checks to guarantee freshness, taste, and, most of all, safety. An important factor that determines fruit quality is its stage of ripening. This is usually manually classified by experts in the field, which makes it a labor-intensive and error-prone process. Thus, there is an arising need for automation in the process of fruit ripeness classification. Many automatic methods have been proposed that employ a variety of feature descriptors for the food item to be graded. Machine learning and deep learning techniques dominate the top-performing methods. Furthermore, deep learning can operate on raw data and thus relieve the users from having to compute complex engineered features, which are often crop-specific. In this survey, we review the latest methods proposed in the literature to automatize fruit ripeness classification, highlighting the most common feature descriptors they operate on.
A Theoretical Framework for AI Models Explainability
Dec 29, 2022
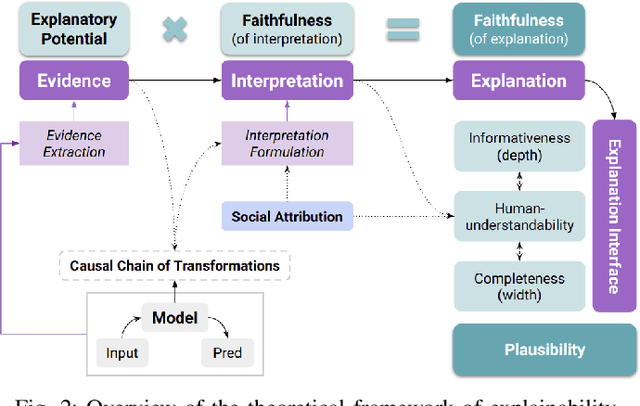
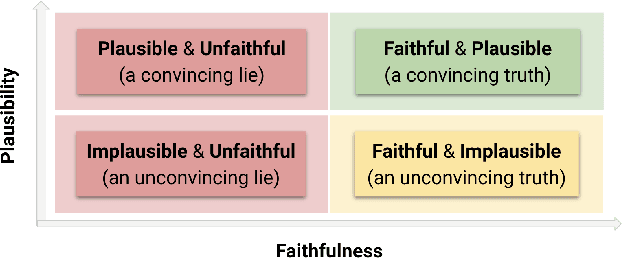
Explainability is a vibrant research topic in the artificial intelligence community, with growing interest across methods and domains. Much has been written about the topic, yet explainability still lacks shared terminology and a framework capable of providing structural soundness to explanations. In our work, we address these issues by proposing a novel definition of explanation that is a synthesis of what can be found in the literature. We recognize that explanations are not atomic but the product of evidence stemming from the model and its input-output and the human interpretation of this evidence. Furthermore, we fit explanations into the properties of faithfulness (i.e., the explanation being a true description of the model's decision-making) and plausibility (i.e., how much the explanation looks convincing to the user). Using our proposed theoretical framework simplifies how these properties are ope rationalized and provide new insight into common explanation methods that we analyze as case studies.
Unsupervised semantic discovery through visual patterns detection
Feb 24, 2021
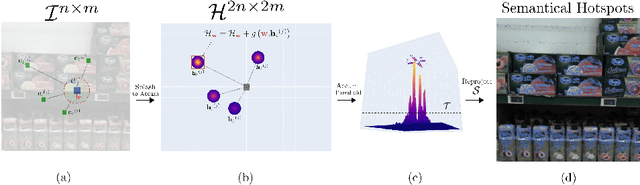
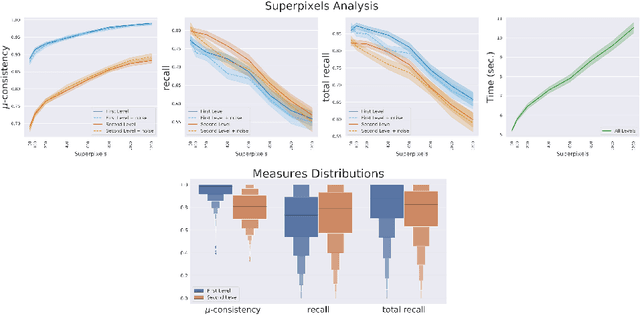

We propose a new fast fully unsupervised method to discover semantic patterns. Our algorithm is able to hierarchically find visual categories and produce a segmentation mask where previous methods fail. Through the modeling of what is a visual pattern in an image, we introduce the notion of "semantic levels" and devise a conceptual framework along with measures and a dedicated benchmark dataset for future comparisons. Our algorithm is composed by two phases. A filtering phase, which selects semantical hotsposts by means of an accumulator space, then a clustering phase which propagates the semantic properties of the hotspots on a superpixels basis. We provide both qualitative and quantitative experimental validation, achieving optimal results in terms of robustness to noise and semantic consistency. We also made code and dataset publicly available.