 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Exit Strategies for Approximate k-NN Search in Dense Retrieval
Aug 09, 2024Learned dense representations are a popular family of techniques for encoding queries and documents using high-dimensional embeddings, which enable retrieval by performing approximate k nearest-neighbors search (A-kNN). A popular technique for making A-kNN search efficient is based on a two-level index, where the embeddings of documents are clustered offline and, at query processing, a fixed number N of clusters closest to the query is visited exhaustively to compute the result set. In this paper, we build upon state-of-the-art for early exit A-kNN and propose an unsupervised method based on the notion of patience, which can reach competitive effectiveness with large efficiency gains. Moreover, we discuss a cascade approach where we first identify queries that find their nearest neighbor within the closest t << N clusters, and then we decide how many more to visit based on our patience approach or other state-of-the-art strategies. Reproducible experiments employing state-of-the-art dense retrieval models and publicly available resources show that our techniques improve the A-kNN efficiency with up to 5x speedups while achieving negligible effectiveness losses. All the code used is available at https://github.com/francescobusolin/faiss_pEE
A Learning-to-Rank Formulation of Clustering-Based Approximate Nearest Neighbor Search
Apr 17, 2024


A critical piece of the modern information retrieval puzzle is approximate nearest neighbor search. Its objective is to return a set of $k$ data points that are closest to a query point, with its accuracy measured by the proportion of exact nearest neighbors captured in the returned set. One popular approach to this question is clustering: The indexing algorithm partitions data points into non-overlapping subsets and represents each partition by a point such as its centroid. The query processing algorithm first identifies the nearest clusters -- a process known as routing -- then performs a nearest neighbor search over those clusters only. In this work, we make a simple observation: The routing function solves a ranking problem. Its quality can therefore be assessed with a ranking metric, making the function amenable to learning-to-rank. Interestingly, ground-truth is often freely available: Given a query distribution in a top-$k$ configuration, the ground-truth is the set of clusters that contain the exact top-$k$ vectors. We develop this insight and apply it to Maximum Inner Product Search (MIPS). As we demonstrate empirically on various datasets, learning a simple linear function consistently improves the accuracy of clustering-based MIPS.
Verifiable Boosted Tree Ensembles
Feb 22, 2024Verifiable learning advocates for training machine learning models amenable to efficient security verification. Prior research demonstrated that specific classes of decision tree ensembles -- called large-spread ensembles -- allow for robustness verification in polynomial time against any norm-based attacker. This study expands prior work on verifiable learning from basic ensemble methods (i.e., hard majority voting) to advanced boosted tree ensembles, such as those trained using XGBoost or LightGBM. Our formal results indicate that robustness verification is achievable in polynomial time when considering attackers based on the $L_\infty$-norm, but remains NP-hard for other norm-based attackers. Nevertheless, we present a pseudo-polynomial time algorithm to verify robustness against attackers based on the $L_p$-norm for any $p \in \mathbb{N} \cup \{0\}$, which in practice grants excellent performance. Our experimental evaluation shows that large-spread boosted ensembles are accurate enough for practical adoption, while being amenable to efficient security verification.
Efficient and Effective Tree-based and Neural Learning to Rank
May 15, 2023This monograph takes a step towards promoting the study of efficiency in the era of neural information retrieval by offering a comprehensive survey of the literature on efficiency and effectiveness in ranking, and to a limited extent, retrieval. This monograph was inspired by the parallels that exist between the challenges in neural network-based ranking solutions and their predecessors, decision forest-based learning to rank models, as well as the connections between the solutions the literature to date has to offer. We believe that by understanding the fundamentals underpinning these algorithmic and data structure solutions for containing the contentious relationship between efficiency and effectiveness, one can better identify future directions and more efficiently determine the merits of ideas. We also present what we believe to be important research directions in the forefront of efficiency and effectiveness in retrieval and ranking.
Fast Inference of Tree Ensembles on ARM Devices
May 15, 2023With the ongoing integration of Machine Learning models into everyday life, e.g. in the form of the Internet of Things (IoT), the evaluation of learned models becomes more and more an important issue. Tree ensembles are one of the best black-box classifiers available and routinely outperform more complex classifiers. While the fast application of tree ensembles has already been studied in the literature for Intel CPUs, they have not yet been studied in the context of ARM CPUs which are more dominant for IoT applications. In this paper, we convert the popular QuickScorer algorithm and its siblings from Intel's AVX to ARM's NEON instruction set. Second, we extend our implementation from ranking models to classification models such as Random Forests. Third, we investigate the effects of using fixed-point quantization in Random Forests. Our study shows that a careful implementation of tree traversal on ARM CPUs leads to a speed-up of up to 9.4 compared to a reference implementation. Moreover, quantized models seem to outperform models using floating-point values in terms of speed in almost all cases, with a neglectable impact on the predictive performance of the model. Finally, our study highlights architectural differences between ARM and Intel CPUs and between different ARM devices that imply that the best implementation depends on both the specific forest as well as the specific device used for deployment.
A Theoretical Framework for AI Models Explainability
Dec 29, 2022
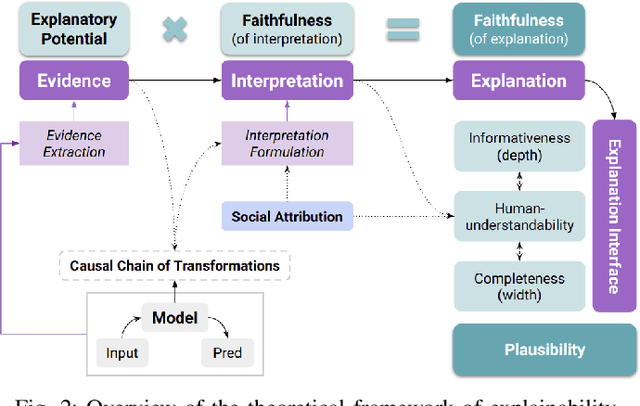
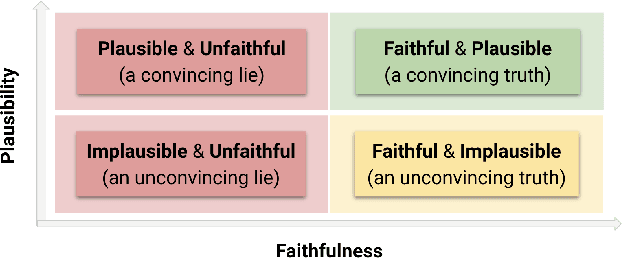
Explainability is a vibrant research topic in the artificial intelligence community, with growing interest across methods and domains. Much has been written about the topic, yet explainability still lacks shared terminology and a framework capable of providing structural soundness to explanations. In our work, we address these issues by proposing a novel definition of explanation that is a synthesis of what can be found in the literature. We recognize that explanations are not atomic but the product of evidence stemming from the model and its input-output and the human interpretation of this evidence. Furthermore, we fit explanations into the properties of faithfulness (i.e., the explanation being a true description of the model's decision-making) and plausibility (i.e., how much the explanation looks convincing to the user). Using our proposed theoretical framework simplifies how these properties are ope rationalized and provide new insight into common explanation methods that we analyze as case studies.
Explainable Global Fairness Verification of Tree-Based Classifiers
Sep 27, 2022
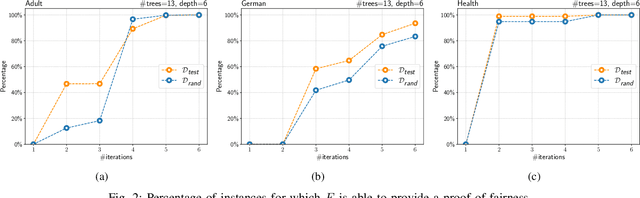
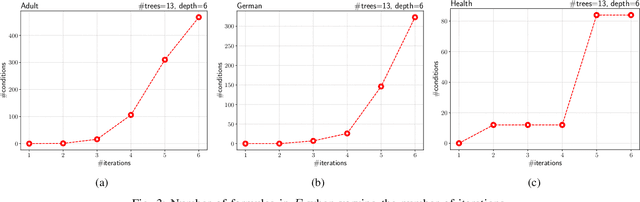
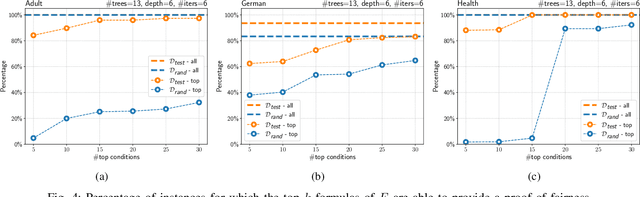
We present a new approach to the global fairness verification of tree-based classifiers. Given a tree-based classifier and a set of sensitive features potentially leading to discrimination, our analysis synthesizes sufficient conditions for fairness, expressed as a set of traditional propositional logic formulas, which are readily understandable by human experts. The verified fairness guarantees are global, in that the formulas predicate over all the possible inputs of the classifier, rather than just a few specific test instances. Our analysis is formally proved both sound and complete. Experimental results on public datasets show that the analysis is precise, explainable to human experts and efficient enough for practical adoption.
ILMART: Interpretable Ranking with Constrained LambdaMART
Jun 01, 2022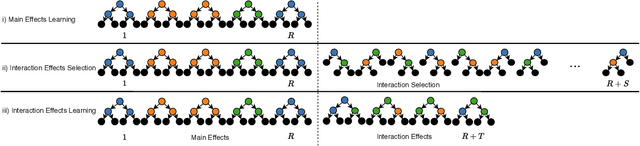



Interpretable Learning to Rank (LtR) is an emerging field within the research area of explainable AI, aiming at developing intelligible and accurate predictive models. While most of the previous research efforts focus on creating post-hoc explanations, in this paper we investigate how to train effective and intrinsically-interpretable ranking models. Developing these models is particularly challenging and it also requires finding a trade-off between ranking quality and model complexity. State-of-the-art rankers, made of either large ensembles of trees or several neural layers, exploit in fact an unlimited number of feature interactions making them black boxes. Previous approaches on intrinsically-interpretable ranking models address this issue by avoiding interactions between features thus paying a significant performance drop with respect to full-complexity models. Conversely, ILMART, our novel and interpretable LtR solution based on LambdaMART, is able to train effective and intelligible models by exploiting a limited and controlled number of pairwise feature interactions. Exhaustive and reproducible experiments conducted on three publicly-available LtR datasets show that ILMART outperforms the current state-of-the-art solution for interpretable ranking of a large margin with a gain of nDCG of up to 8%.
EiFFFeL: Enforcing Fairness in Forests by Flipping Leaves
Dec 29, 2021
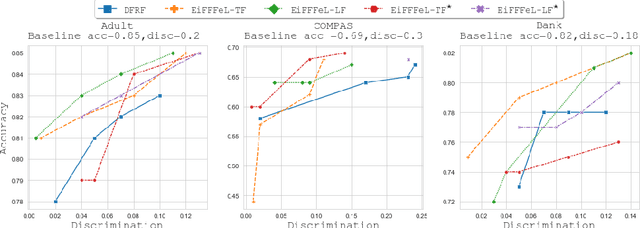

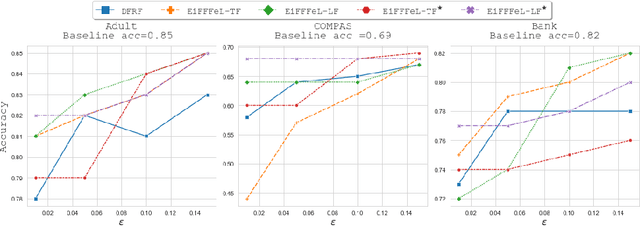
Nowadays Machine Learning (ML) techniques are extensively adopted in many socially sensitive systems, thus requiring to carefully study the fairness of the decisions taken by such systems. Many approaches have been proposed to address and to make sure there is no bias against individuals or specific groups which might originally come from biased training datasets or algorithm design. In this regard, we propose a fairness enforcing approach called EiFFFeL:Enforcing Fairness in Forests by Flipping Leaves which exploits tree-based or leaf-based post-processing strategies to relabel leaves of selected decision trees of a given forest. Experimental results show that our approach achieves a user defined group fairness degree without losing a significant amount of accuracy.
Beyond Robustness: Resilience Verification of Tree-Based Classifiers
Dec 05, 2021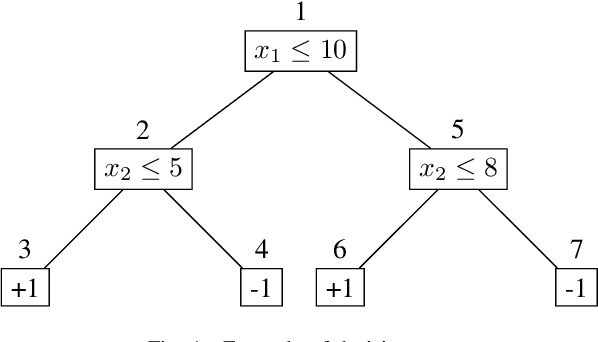
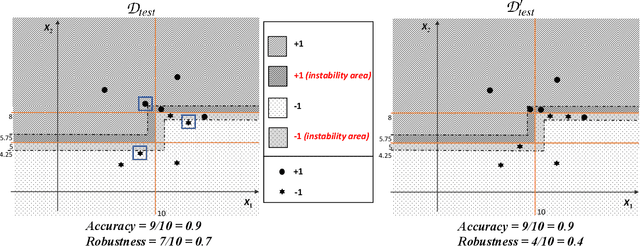

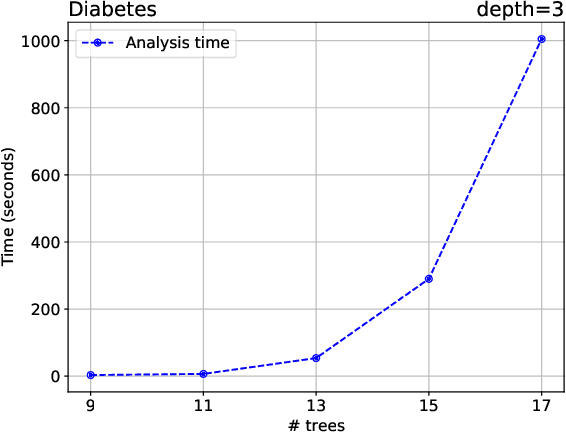
In this paper we criticize the robustness measure traditionally employed to assess the performance of machine learning models deployed in adversarial settings. To mitigate the limitations of robustness, we introduce a new measure called resilience and we focus on its verification. In particular, we discuss how resilience can be verified by combining a traditional robustness verification technique with a data-independent stability analysis, which identifies a subset of the feature space where the model does not change its predictions despite adversarial manipulations. We then introduce a formally sound data-independent stability analysis for decision trees and decision tree ensembles, which we experimentally assess on public datasets and we leverage for resilience verification. Our results show that resilience verification is useful and feasible in practice, yielding a more reliable security assessment of both standard and robust decision tree models.