 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower- and Fragmentation-aware Online Scheduling for GPU Datacenters
Dec 23, 2024



The rise of Artificial Intelligence and Large Language Models is driving increased GPU usage in data centers for complex training and inference tasks, impacting operational costs, energy demands, and the environmental footprint of large-scale computing infrastructures. This work addresses the online scheduling problem in GPU datacenters, which involves scheduling tasks without knowledge of their future arrivals. We focus on two objectives: minimizing GPU fragmentation and reducing power consumption. GPU fragmentation occurs when partial GPU allocations hinder the efficient use of remaining resources, especially as the datacenter nears full capacity. A recent scheduling policy, Fragmentation Gradient Descent (FGD), leverages a fragmentation metric to address this issue. Reducing power consumption is also crucial due to the significant power demands of GPUs. To this end, we propose PWR, a novel scheduling policy to minimize power usage by selecting power-efficient GPU and CPU combinations. This involves a simplified model for measuring power consumption integrated into a Kubernetes score plugin. Through an extensive experimental evaluation in a simulated cluster, we show how PWR, when combined with FGD, achieves a balanced trade-off between reducing power consumption and minimizing GPU fragmentation.
Early Exit Strategies for Approximate k-NN Search in Dense Retrieval
Aug 09, 2024Learned dense representations are a popular family of techniques for encoding queries and documents using high-dimensional embeddings, which enable retrieval by performing approximate k nearest-neighbors search (A-kNN). A popular technique for making A-kNN search efficient is based on a two-level index, where the embeddings of documents are clustered offline and, at query processing, a fixed number N of clusters closest to the query is visited exhaustively to compute the result set. In this paper, we build upon state-of-the-art for early exit A-kNN and propose an unsupervised method based on the notion of patience, which can reach competitive effectiveness with large efficiency gains. Moreover, we discuss a cascade approach where we first identify queries that find their nearest neighbor within the closest t << N clusters, and then we decide how many more to visit based on our patience approach or other state-of-the-art strategies. Reproducible experiments employing state-of-the-art dense retrieval models and publicly available resources show that our techniques improve the A-kNN efficiency with up to 5x speedups while achieving negligible effectiveness losses. All the code used is available at https://github.com/francescobusolin/faiss_pEE
Neural Network Compression using Binarization and Few Full-Precision Weights
Jun 15, 2023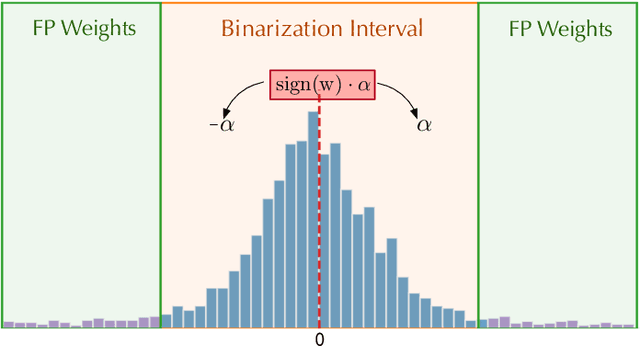
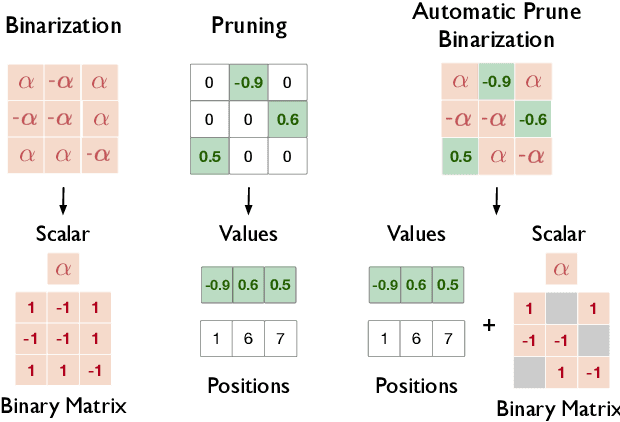
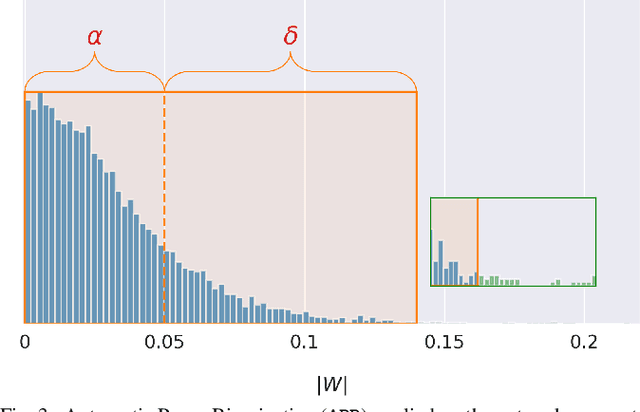
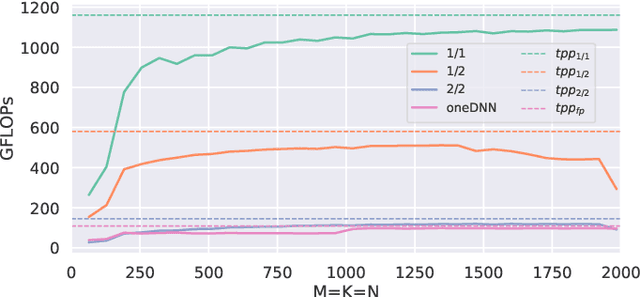
Quantization and pruning are known to be two effective Deep Neural Networks model compression methods. In this paper, we propose Automatic Prune Binarization (APB), a novel compression technique combining quantization with pruning. APB enhances the representational capability of binary networks using a few full-precision weights. Our technique jointly maximizes the accuracy of the network while minimizing its memory impact by deciding whether each weight should be binarized or kept in full precision. We show how to efficiently perform a forward pass through layers compressed using APB by decomposing it into a binary and a sparse-dense matrix multiplication. Moreover, we design two novel efficient algorithms for extremely quantized matrix multiplication on CPU, leveraging highly efficient bitwise operations. The proposed algorithms are 6.9x and 1.5x faster than available state-of-the-art solutions. We perform an extensive evaluation of APB on two widely adopted model compression datasets, namely CIFAR10 and ImageNet. APB shows to deliver better accuracy/memory trade-off compared to state-of-the-art methods based on i) quantization, ii) pruning, and iii) combination of pruning and quantization. APB outperforms quantization also in the accuracy/efficiency trade-off, being up to 2x faster than the 2-bits quantized model with no loss in accuracy.
Learning Early Exit Strategies for Additive Ranking Ensembles
May 06, 2021
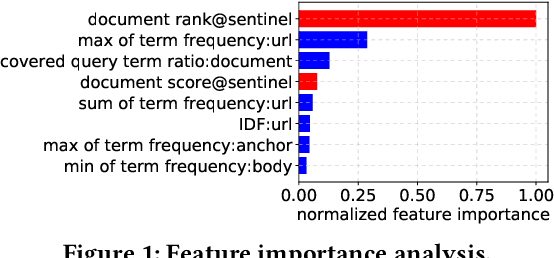


Modern search engine ranking pipelines are commonly based on large machine-learned ensembles of regression trees. We propose LEAR, a novel - learned - technique aimed to reduce the average number of trees traversed by documents to accumulate the scores, thus reducing the overall query response time. LEAR exploits a classifier that predicts whether a document can early exit the ensemble because it is unlikely to be ranked among the final top-k results. The early exit decision occurs at a sentinel point, i.e., after having evaluated a limited number of trees, and the partial scores are exploited to filter out non-promising documents. We evaluate LEAR by deploying it in a production-like setting, adopting a state-of-the-art algorithm for ensembles traversal. We provide a comprehensive experimental evaluation on two public datasets. The experiments show that LEAR has a significant impact on the efficiency of the query processing without hindering its ranking quality. In detail, on a first dataset, LEAR is able to achieve a speedup of 3x without any loss in NDCG1@0, while on a second dataset the speedup is larger than 5x with a negligible NDCG@10 loss (< 0.05%).
Query-level Early Exit for Additive Learning-to-Rank Ensembles
Apr 30, 2020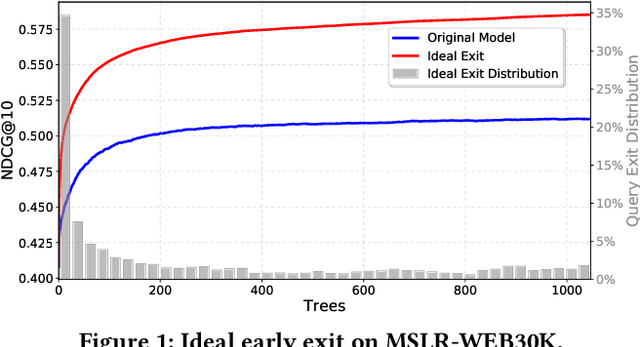



Search engine ranking pipelines are commonly based on large ensembles of machine-learned decision trees. The tight constraints on query response time recently motivated researchers to investigate algorithms to make faster the traversal of the additive ensemble or to early terminate the evaluation of documents that are unlikely to be ranked among the top-k. In this paper, we investigate the novel problem of \textit{query-level early exiting}, aimed at deciding the profitability of early stopping the traversal of the ranking ensemble for all the candidate documents to be scored for a query, by simply returning a ranking based on the additive scores computed by a limited portion of the ensemble. Besides the obvious advantage on query latency and throughput, we address the possible positive impact of query-level early exiting on ranking effectiveness. To this end, we study the actual contribution of incremental portions of the tree ensemble to the ranking of the top-k documents scored for a given query. Our main finding is that queries exhibit different behaviors as scores are accumulated during the traversal of the ensemble and that query-level early stopping can remarkably improve ranking quality. We present a reproducible and comprehensive experimental evaluation, conducted on two public datasets, showing that query-level early exiting achieves an overall gain of up to 7.5% in terms of NDCG@10 with a speedup of the scoring process of up to 2.2x.