 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Decision Tree Ensembles
Oct 06, 2024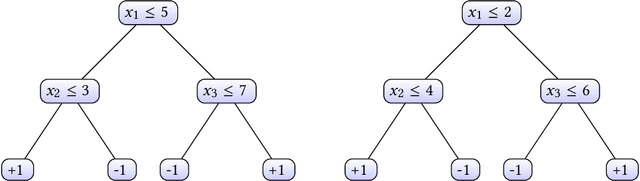


Protecting the intellectual property of machine learning models is a hot topic and many watermarking schemes for deep neural networks have been proposed in the literature. Unfortunately, prior work largely neglected the investigation of watermarking techniques for other types of models, including decision tree ensembles, which are a state-of-the-art model for classification tasks on non-perceptual data. In this paper, we present the first watermarking scheme designed for decision tree ensembles, focusing in particular on random forest models. We discuss watermark creation and verification, presenting a thorough security analysis with respect to possible attacks. We finally perform an experimental evaluation of the proposed scheme, showing excellent results in terms of accuracy and security against the most relevant threats.
Early Exit Strategies for Approximate k-NN Search in Dense Retrieval
Aug 09, 2024Learned dense representations are a popular family of techniques for encoding queries and documents using high-dimensional embeddings, which enable retrieval by performing approximate k nearest-neighbors search (A-kNN). A popular technique for making A-kNN search efficient is based on a two-level index, where the embeddings of documents are clustered offline and, at query processing, a fixed number N of clusters closest to the query is visited exhaustively to compute the result set. In this paper, we build upon state-of-the-art for early exit A-kNN and propose an unsupervised method based on the notion of patience, which can reach competitive effectiveness with large efficiency gains. Moreover, we discuss a cascade approach where we first identify queries that find their nearest neighbor within the closest t << N clusters, and then we decide how many more to visit based on our patience approach or other state-of-the-art strategies. Reproducible experiments employing state-of-the-art dense retrieval models and publicly available resources show that our techniques improve the A-kNN efficiency with up to 5x speedups while achieving negligible effectiveness losses. All the code used is available at https://github.com/francescobusolin/faiss_pEE
ILMART: Interpretable Ranking with Constrained LambdaMART
Jun 01, 2022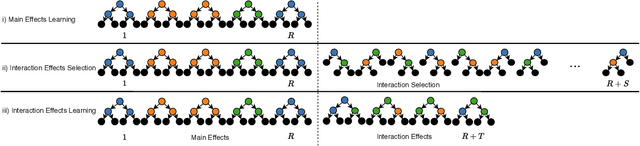



Interpretable Learning to Rank (LtR) is an emerging field within the research area of explainable AI, aiming at developing intelligible and accurate predictive models. While most of the previous research efforts focus on creating post-hoc explanations, in this paper we investigate how to train effective and intrinsically-interpretable ranking models. Developing these models is particularly challenging and it also requires finding a trade-off between ranking quality and model complexity. State-of-the-art rankers, made of either large ensembles of trees or several neural layers, exploit in fact an unlimited number of feature interactions making them black boxes. Previous approaches on intrinsically-interpretable ranking models address this issue by avoiding interactions between features thus paying a significant performance drop with respect to full-complexity models. Conversely, ILMART, our novel and interpretable LtR solution based on LambdaMART, is able to train effective and intelligible models by exploiting a limited and controlled number of pairwise feature interactions. Exhaustive and reproducible experiments conducted on three publicly-available LtR datasets show that ILMART outperforms the current state-of-the-art solution for interpretable ranking of a large margin with a gain of nDCG of up to 8%.
EiFFFeL: Enforcing Fairness in Forests by Flipping Leaves
Dec 29, 2021
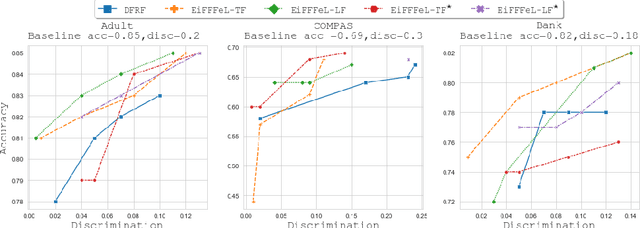

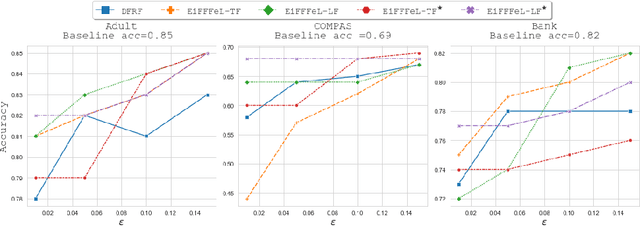
Nowadays Machine Learning (ML) techniques are extensively adopted in many socially sensitive systems, thus requiring to carefully study the fairness of the decisions taken by such systems. Many approaches have been proposed to address and to make sure there is no bias against individuals or specific groups which might originally come from biased training datasets or algorithm design. In this regard, we propose a fairness enforcing approach called EiFFFeL:Enforcing Fairness in Forests by Flipping Leaves which exploits tree-based or leaf-based post-processing strategies to relabel leaves of selected decision trees of a given forest. Experimental results show that our approach achieves a user defined group fairness degree without losing a significant amount of accuracy.
Beyond Robustness: Resilience Verification of Tree-Based Classifiers
Dec 05, 2021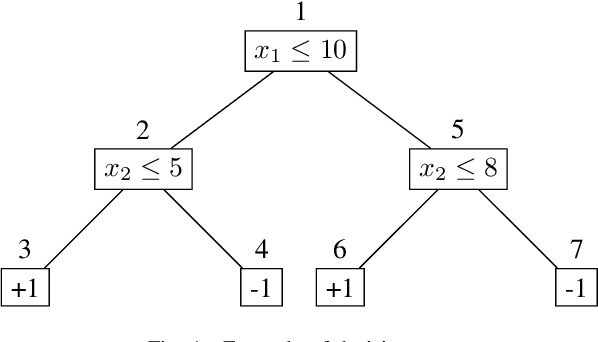
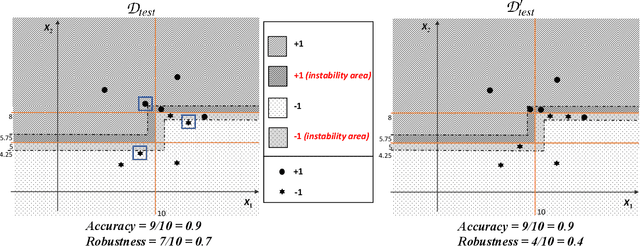

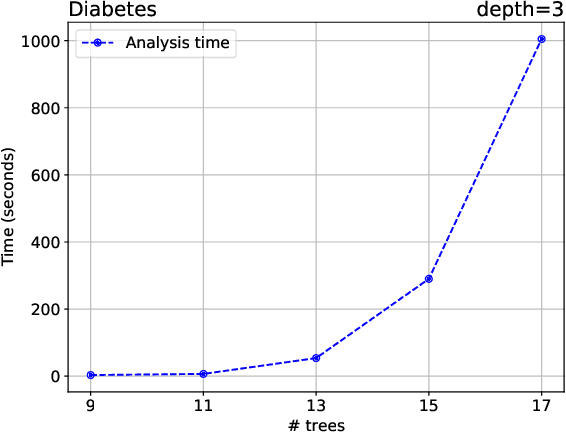
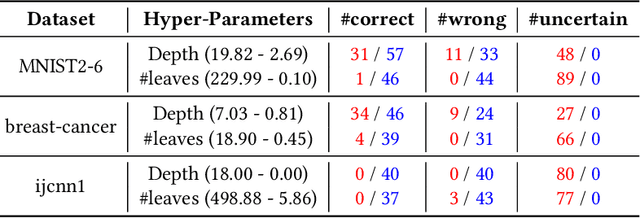
In this paper we criticize the robustness measure traditionally employed to assess the performance of machine learning models deployed in adversarial settings. To mitigate the limitations of robustness, we introduce a new measure called resilience and we focus on its verification. In particular, we discuss how resilience can be verified by combining a traditional robustness verification technique with a data-independent stability analysis, which identifies a subset of the feature space where the model does not change its predictions despite adversarial manipulations. We then introduce a formally sound data-independent stability analysis for decision trees and decision tree ensembles, which we experimentally assess on public datasets and we leverage for resilience verification. Our results show that resilience verification is useful and feasible in practice, yielding a more reliable security assessment of both standard and robust decision tree models.
Learning Early Exit Strategies for Additive Ranking Ensembles
May 06, 2021
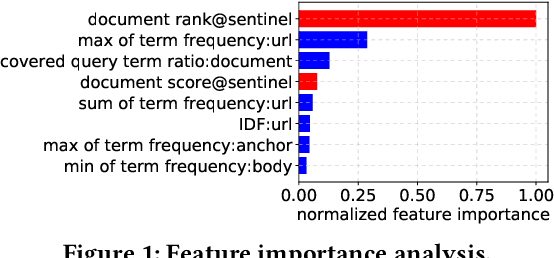


Modern search engine ranking pipelines are commonly based on large machine-learned ensembles of regression trees. We propose LEAR, a novel - learned - technique aimed to reduce the average number of trees traversed by documents to accumulate the scores, thus reducing the overall query response time. LEAR exploits a classifier that predicts whether a document can early exit the ensemble because it is unlikely to be ranked among the final top-k results. The early exit decision occurs at a sentinel point, i.e., after having evaluated a limited number of trees, and the partial scores are exploited to filter out non-promising documents. We evaluate LEAR by deploying it in a production-like setting, adopting a state-of-the-art algorithm for ensembles traversal. We provide a comprehensive experimental evaluation on two public datasets. The experiments show that LEAR has a significant impact on the efficiency of the query processing without hindering its ranking quality. In detail, on a first dataset, LEAR is able to achieve a speedup of 3x without any loss in NDCG1@0, while on a second dataset the speedup is larger than 5x with a negligible NDCG@10 loss (< 0.05%).
Query-level Early Exit for Additive Learning-to-Rank Ensembles
Apr 30, 2020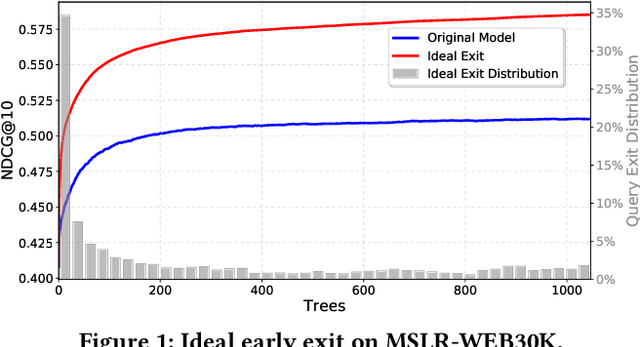



Search engine ranking pipelines are commonly based on large ensembles of machine-learned decision trees. The tight constraints on query response time recently motivated researchers to investigate algorithms to make faster the traversal of the additive ensemble or to early terminate the evaluation of documents that are unlikely to be ranked among the top-k. In this paper, we investigate the novel problem of \textit{query-level early exiting}, aimed at deciding the profitability of early stopping the traversal of the ranking ensemble for all the candidate documents to be scored for a query, by simply returning a ranking based on the additive scores computed by a limited portion of the ensemble. Besides the obvious advantage on query latency and throughput, we address the possible positive impact of query-level early exiting on ranking effectiveness. To this end, we study the actual contribution of incremental portions of the tree ensemble to the ranking of the top-k documents scored for a given query. Our main finding is that queries exhibit different behaviors as scores are accumulated during the traversal of the ensemble and that query-level early stopping can remarkably improve ranking quality. We present a reproducible and comprehensive experimental evaluation, conducted on two public datasets, showing that query-level early exiting achieves an overall gain of up to 7.5% in terms of NDCG@10 with a speedup of the scoring process of up to 2.2x.
Feature Partitioning for Robust Tree Ensembles and their Certification in Adversarial Scenarios
Apr 07, 2020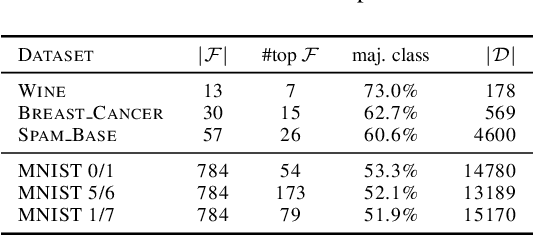
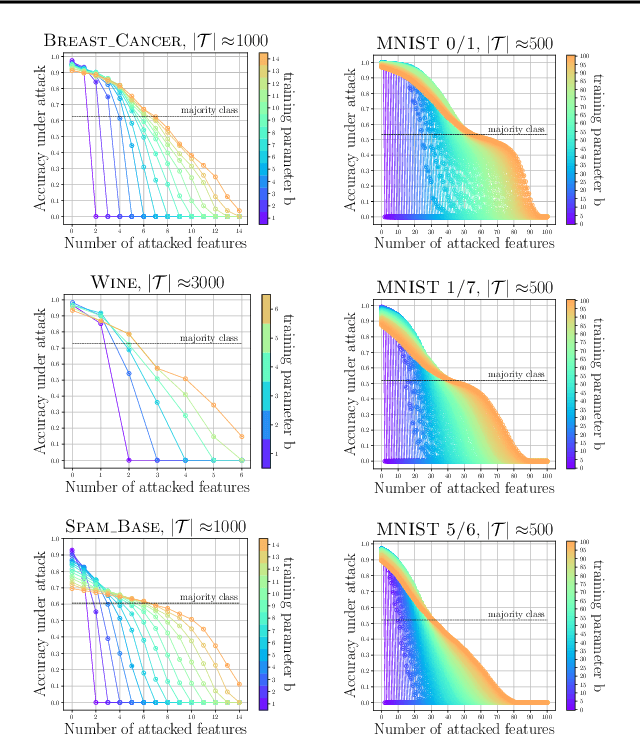
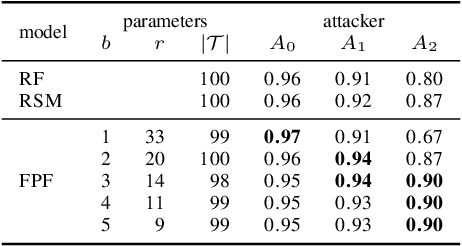

Machine learning algorithms, however effective, are known to be vulnerable in adversarial scenarios where a malicious user may inject manipulated instances. In this work we focus on evasion attacks, where a model is trained in a safe environment and exposed to attacks at test time. The attacker aims at finding a minimal perturbation of a test instance that changes the model outcome. We propose a model-agnostic strategy that builds a robust ensemble by training its basic models on feature-based partitions of the given dataset. Our algorithm guarantees that the majority of the models in the ensemble cannot be affected by the attacker. We experimented the proposed strategy on decision tree ensembles, and we also propose an approximate certification method for tree ensembles that efficiently assess the minimal accuracy of a forest on a given dataset avoiding the costly computation of evasion attacks. Experimental evaluation on publicly available datasets shows that proposed strategy outperforms state-of-the-art adversarial learning algorithms against evasion attacks.
Treant: Training Evasion-Aware Decision Trees
Jul 03, 2019
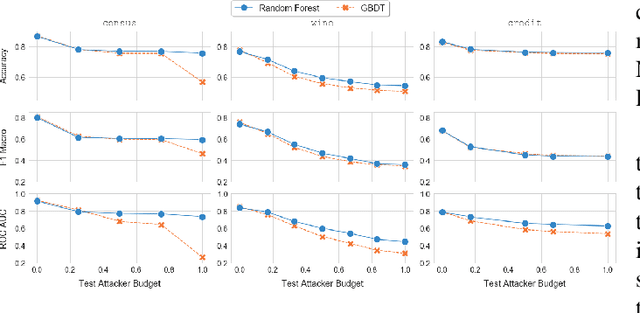
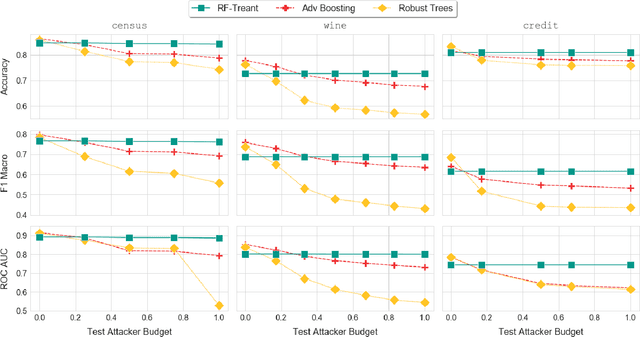

Despite its success and popularity, machine learning is now recognized as vulnerable to evasion attacks, i.e., carefully crafted perturbations of test inputs designed to force prediction errors. In this paper we focus on evasion attacks against decision tree ensembles, which are among the most successful predictive models for dealing with non-perceptual problems. Even though they are powerful and interpretable, decision tree ensembles have received only limited attention by the security and machine learning communities so far, leading to a sub-optimal state of the art for adversarial learning techniques. We thus propose Treant, a novel decision tree learning algorithm that, on the basis of a formal threat model, minimizes an evasion-aware loss function at each step of the tree construction. Treant is based on two key technical ingredients: robust splitting and attack invariance, which jointly guarantee the soundness of the learning process. Experimental results on three publicly available datasets show that Treant is able to generate decision tree ensembles that are at the same time accurate and nearly insensitive to evasion attacks, outperforming state-of-the-art adversarial learning techniques.