 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Early Exit Strategies for Additive Ranking Ensembles
Paper and Code

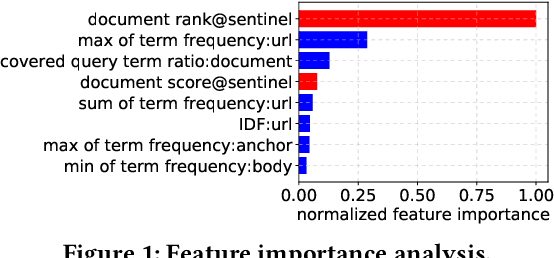


Modern search engine ranking pipelines are commonly based on large machine-learned ensembles of regression trees. We propose LEAR, a novel - learned - technique aimed to reduce the average number of trees traversed by documents to accumulate the scores, thus reducing the overall query response time. LEAR exploits a classifier that predicts whether a document can early exit the ensemble because it is unlikely to be ranked among the final top-k results. The early exit decision occurs at a sentinel point, i.e., after having evaluated a limited number of trees, and the partial scores are exploited to filter out non-promising documents. We evaluate LEAR by deploying it in a production-like setting, adopting a state-of-the-art algorithm for ensembles traversal. We provide a comprehensive experimental evaluation on two public datasets. The experiments show that LEAR has a significant impact on the efficiency of the query processing without hindering its ranking quality. In detail, on a first dataset, LEAR is able to achieve a speedup of 3x without any loss in NDCG1@0, while on a second dataset the speedup is larger than 5x with a negligible NDCG@10 loss (< 0.05%).