 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Exit Strategies for Approximate k-NN Search in Dense Retrieval
Aug 09, 2024Learned dense representations are a popular family of techniques for encoding queries and documents using high-dimensional embeddings, which enable retrieval by performing approximate k nearest-neighbors search (A-kNN). A popular technique for making A-kNN search efficient is based on a two-level index, where the embeddings of documents are clustered offline and, at query processing, a fixed number N of clusters closest to the query is visited exhaustively to compute the result set. In this paper, we build upon state-of-the-art for early exit A-kNN and propose an unsupervised method based on the notion of patience, which can reach competitive effectiveness with large efficiency gains. Moreover, we discuss a cascade approach where we first identify queries that find their nearest neighbor within the closest t << N clusters, and then we decide how many more to visit based on our patience approach or other state-of-the-art strategies. Reproducible experiments employing state-of-the-art dense retrieval models and publicly available resources show that our techniques improve the A-kNN efficiency with up to 5x speedups while achieving negligible effectiveness losses. All the code used is available at https://github.com/francescobusolin/faiss_pEE
Learning Early Exit Strategies for Additive Ranking Ensembles
May 06, 2021
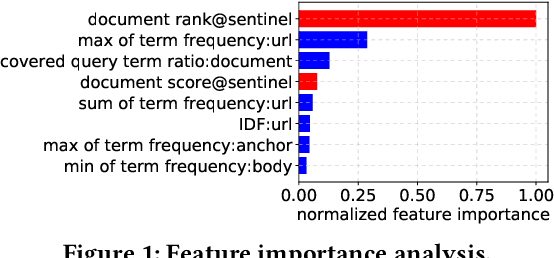


Modern search engine ranking pipelines are commonly based on large machine-learned ensembles of regression trees. We propose LEAR, a novel - learned - technique aimed to reduce the average number of trees traversed by documents to accumulate the scores, thus reducing the overall query response time. LEAR exploits a classifier that predicts whether a document can early exit the ensemble because it is unlikely to be ranked among the final top-k results. The early exit decision occurs at a sentinel point, i.e., after having evaluated a limited number of trees, and the partial scores are exploited to filter out non-promising documents. We evaluate LEAR by deploying it in a production-like setting, adopting a state-of-the-art algorithm for ensembles traversal. We provide a comprehensive experimental evaluation on two public datasets. The experiments show that LEAR has a significant impact on the efficiency of the query processing without hindering its ranking quality. In detail, on a first dataset, LEAR is able to achieve a speedup of 3x without any loss in NDCG1@0, while on a second dataset the speedup is larger than 5x with a negligible NDCG@10 loss (< 0.05%).