 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAMA: Domain Retrieval using Adaptive Module Allocation
Feb 16, 2026Neural models are increasingly used in Web-scale Information Retrieval (IR). However, relying on these models introduces substantial computational and energy requirements, leading to increasing attention toward their environmental cost and the sustainability of large-scale deployments. While neural IR models deliver high retrieval effectiveness, their scalability is constrained in multi-domain scenarios, where training and maintaining domain-specific models is inefficient and achieving robust cross-domain generalisation within a unified model remains difficult. This paper introduces DRAMA (Domain Retrieval using Adaptive Module Allocation), an energy- and parameter-efficient framework designed to reduce the environmental footprint of neural retrieval. DRAMA integrates domain-specific adapter modules with a dynamic gating mechanism that selects the most relevant domain knowledge for each query. New domains can be added efficiently through lightweight adapter training, avoiding full model retraining. We evaluate DRAMA on multiple Web retrieval benchmarks covering different domains. Our extensive evaluation shows that DRAMA achieves comparable effectiveness to domain-specific models while using only a fraction of their parameters and computational resources. These findings show that energy-aware model design can significantly improve scalability and sustainability in neural IR.
Early-Exit Graph Neural Networks
May 23, 2025Early-exit mechanisms allow deep neural networks to halt inference as soon as classification confidence is high enough, adaptively trading depth for confidence, and thereby cutting latency and energy on easy inputs while retaining full-depth accuracy for harder ones. Similarly, adding early exit mechanisms to Graph Neural Networks (GNNs), the go-to models for graph-structured data, allows for dynamic trading depth for confidence on simple graphs while maintaining full-depth accuracy on harder and more complex graphs to capture intricate relationships. Although early exits have proven effective across various deep learning domains, their potential within GNNs in scenarios that require deep architectures while resisting over-smoothing and over-squashing remains largely unexplored. We unlock that potential by first introducing Symmetric-Anti-Symmetric Graph Neural Networks (SAS-GNN), whose symmetry-based inductive biases mitigate these issues and yield stable intermediate representations that can be useful to allow early exiting in GNNs. Building on this backbone, we present Early-Exit Graph Neural Networks (EEGNNs), which append confidence-aware exit heads that allow on-the-fly termination of propagation based on each node or the entire graph. Experiments show that EEGNNs preserve robust performance as depth grows and deliver competitive accuracy on heterophilic and long-range benchmarks, matching attention-based and asynchronous message-passing models while substantially reducing computation and latency. We plan to release the code to reproduce our experiments.
Efficient Conversational Search via Topical Locality in Dense Retrieval
Apr 30, 2025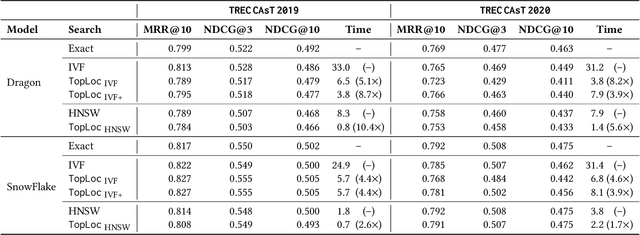
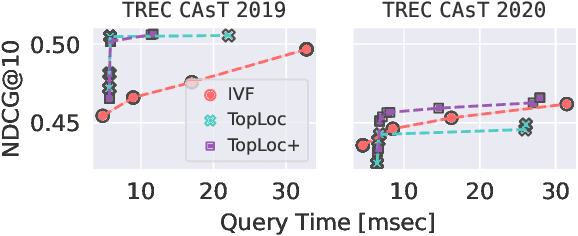
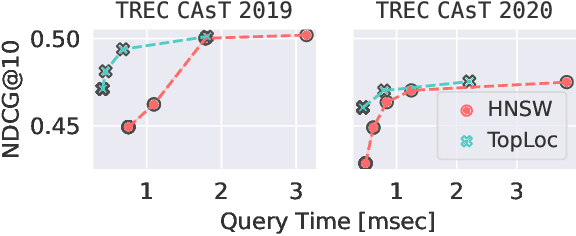
Pre-trained language models have been widely exploited to learn dense representations of documents and queries for information retrieval. While previous efforts have primarily focused on improving effectiveness and user satisfaction, response time remains a critical bottleneck of conversational search systems. To address this, we exploit the topical locality inherent in conversational queries, i.e., the tendency of queries within a conversation to focus on related topics. By leveraging query embedding similarities, we dynamically restrict the search space to semantically relevant document clusters, reducing computational complexity without compromising retrieval quality. We evaluate our approach on the TREC CAsT 2019 and 2020 datasets using multiple embedding models and vector indexes, achieving improvements in processing speed of up to 10.4X with little loss in performance (4.4X without any loss). Our results show that the proposed system effectively handles complex, multiturn queries with high precision and efficiency, offering a practical solution for real-time conversational search.
Towards Robust Expert Finding in Community Question Answering Platforms
Mar 04, 2025This paper introduces TUEF, a topic-oriented user-interaction model for fair Expert Finding in Community Question Answering (CQA) platforms. The Expert Finding task in CQA platforms involves identifying proficient users capable of providing accurate answers to questions from the community. To this aim, TUEF improves the robustness and credibility of the CQA platform through a more precise Expert Finding component. The key idea of TUEF is to exploit diverse types of information, specifically, content and social information, to identify more precisely experts thus improving the robustness of the task. We assess TUEF through reproducible experiments conducted on a large-scale dataset from StackOverflow. The results consistently demonstrate that TUEF outperforms state-of-the-art competitors while promoting transparent expert identification.
Power- and Fragmentation-aware Online Scheduling for GPU Datacenters
Dec 23, 2024



The rise of Artificial Intelligence and Large Language Models is driving increased GPU usage in data centers for complex training and inference tasks, impacting operational costs, energy demands, and the environmental footprint of large-scale computing infrastructures. This work addresses the online scheduling problem in GPU datacenters, which involves scheduling tasks without knowledge of their future arrivals. We focus on two objectives: minimizing GPU fragmentation and reducing power consumption. GPU fragmentation occurs when partial GPU allocations hinder the efficient use of remaining resources, especially as the datacenter nears full capacity. A recent scheduling policy, Fragmentation Gradient Descent (FGD), leverages a fragmentation metric to address this issue. Reducing power consumption is also crucial due to the significant power demands of GPUs. To this end, we propose PWR, a novel scheduling policy to minimize power usage by selecting power-efficient GPU and CPU combinations. This involves a simplified model for measuring power consumption integrated into a Kubernetes score plugin. Through an extensive experimental evaluation in a simulated cluster, we show how PWR, when combined with FGD, achieves a balanced trade-off between reducing power consumption and minimizing GPU fragmentation.
Rewriting Conversational Utterances with Instructed Large Language Models
Oct 10, 2024Many recent studies have shown the ability of large language models (LLMs) to achieve state-of-the-art performance on many NLP tasks, such as question answering, text summarization, coding, and translation. In some cases, the results provided by LLMs are on par with those of human experts. These models' most disruptive innovation is their ability to perform tasks via zero-shot or few-shot prompting. This capability has been successfully exploited to train instructed LLMs, where reinforcement learning with human feedback is used to guide the model to follow the user's requests directly. In this paper, we investigate the ability of instructed LLMs to improve conversational search effectiveness by rewriting user questions in a conversational setting. We study which prompts provide the most informative rewritten utterances that lead to the best retrieval performance. Reproducible experiments are conducted on publicly-available TREC CAST datasets. The results show that rewriting conversational utterances with instructed LLMs achieves significant improvements of up to 25.2% in MRR, 31.7% in Precision@1, 27% in NDCG@3, and 11.5% in Recall@500 over state-of-the-art techniques.
Early Exit Strategies for Approximate k-NN Search in Dense Retrieval
Aug 09, 2024Learned dense representations are a popular family of techniques for encoding queries and documents using high-dimensional embeddings, which enable retrieval by performing approximate k nearest-neighbors search (A-kNN). A popular technique for making A-kNN search efficient is based on a two-level index, where the embeddings of documents are clustered offline and, at query processing, a fixed number N of clusters closest to the query is visited exhaustively to compute the result set. In this paper, we build upon state-of-the-art for early exit A-kNN and propose an unsupervised method based on the notion of patience, which can reach competitive effectiveness with large efficiency gains. Moreover, we discuss a cascade approach where we first identify queries that find their nearest neighbor within the closest t << N clusters, and then we decide how many more to visit based on our patience approach or other state-of-the-art strategies. Reproducible experiments employing state-of-the-art dense retrieval models and publicly available resources show that our techniques improve the A-kNN efficiency with up to 5x speedups while achieving negligible effectiveness losses. All the code used is available at https://github.com/francescobusolin/faiss_pEE
Understanding and Addressing Gender Bias in Expert Finding Task
Jul 07, 2024



The Expert Finding (EF) task is critical in community Question&Answer (CQ&A) platforms, significantly enhancing user engagement by improving answer quality and reducing response times. However, biases, especially gender biases, have been identified in these platforms. This study investigates gender bias in state-of-the-art EF models and explores methods to mitigate it. Utilizing a comprehensive dataset from StackOverflow, the largest community in the StackExchange network, we conduct extensive experiments to analyze how EF models' candidate identification processes influence gender representation. Our findings reveal that models relying on reputation metrics and activity levels disproportionately favor male users, who are more active on the platform. This bias results in the underrepresentation of female experts in the ranking process. We propose adjustments to EF models that incorporate a more balanced preprocessing strategy and leverage content-based and social network-based information, with the aim to provide a fairer representation of genders among identified experts. Our analysis shows that integrating these methods can significantly enhance gender balance without compromising model accuracy. To the best of our knowledge, this study is the first to focus on detecting and mitigating gender bias in EF methods.
Leveraging Topic Specificity and Social Relationships for Expert Finding in Community Question Answering Platforms
Jul 04, 2024



Online Community Question Answering (CQA) platforms have become indispensable tools for users seeking expert solutions to their technical queries. The effectiveness of these platforms relies on their ability to identify and direct questions to the most knowledgeable users within the community, a process known as Expert Finding (EF). EF accuracy is crucial for increasing user engagement and the reliability of provided answers. Despite recent advancements in EF methodologies, blending the diverse information sources available on CQA platforms for effective expert identification remains challenging. In this paper, we present TUEF, a Topic-oriented User-Interaction model for Expert Finding, which aims to fully and transparently leverage the heterogeneous information available within online question-answering communities. TUEF integrates content and social data by constructing a multi-layer graph that maps out user relationships based on their answering patterns on specific topics. By combining these sources of information, TUEF identifies the most relevant and knowledgeable users for any given question and ranks them using learning-to-rank techniques. Our findings indicate that TUEF's topic-oriented model significantly enhances performance, particularly in large communities discussing well-defined topics. Additionally, we show that the interpretable learning-to-rank algorithm integrated into TUEF offers transparency and explainability with minimal performance trade-offs. The exhaustive experiments conducted on six different CQA communities of Stack Exchange show that TUEF outperforms all competitors with a minimum performance boost of 42.42% in P@1, 32.73% in NDCG@3, 21.76% in R@5, and 29.81% in MRR, excelling in both the evaluation approaches present in the previous literature.
DESIRE-ME: Domain-Enhanced Supervised Information REtrieval using Mixture-of-Experts
Mar 20, 2024Open-domain question answering requires retrieval systems able to cope with the diverse and varied nature of questions, providing accurate answers across a broad spectrum of query types and topics. To deal with such topic heterogeneity through a unique model, we propose DESIRE-ME, a neural information retrieval model that leverages the Mixture-of-Experts framework to combine multiple specialized neural models. We rely on Wikipedia data to train an effective neural gating mechanism that classifies the incoming query and that weighs the predictions of the different domain-specific experts correspondingly. This allows DESIRE-ME to specialize adaptively in multiple domains. Through extensive experiments on publicly available datasets, we show that our proposal can effectively generalize domain-enhanced neural models. DESIRE-ME excels in handling open-domain questions adaptively, boosting by up to 12% in NDCG@10 and 22% in P@1, the underlying state-of-the-art dense retrieval model.