 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Quantization Shapes Bias in Large Language Models
Aug 25, 2025
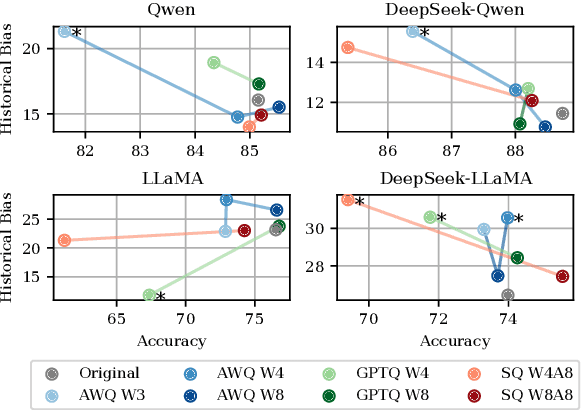
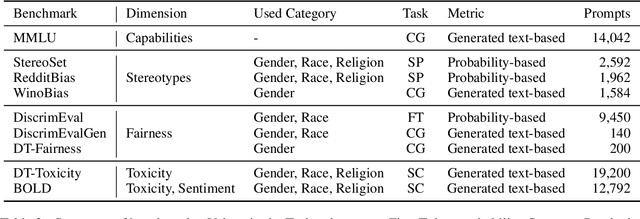
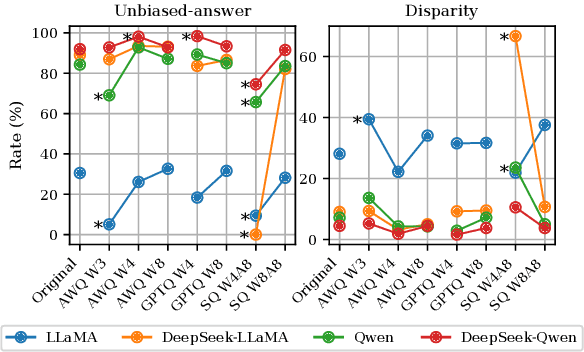
This work presents a comprehensive evaluation of how quantization affects model bias, with particular attention to its impact on individual demographic subgroups. We focus on weight and activation quantization strategies and examine their effects across a broad range of bias types, including stereotypes, toxicity, sentiment, and fairness. We employ both probabilistic and generated text-based metrics across nine benchmarks and evaluate models varying in architecture family and reasoning ability. Our findings show that quantization has a nuanced impact on bias: while it can reduce model toxicity and does not significantly impact sentiment, it tends to slightly increase stereotypes and unfairness in generative tasks, especially under aggressive compression. These trends are generally consistent across demographic categories and model types, although their magnitude depends on the specific setting. Overall, our results highlight the importance of carefully balancing efficiency and ethical considerations when applying quantization in practice.
Explainable Global Fairness Verification of Tree-Based Classifiers
Sep 27, 2022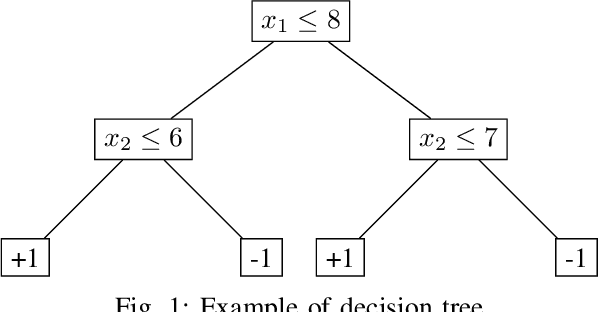
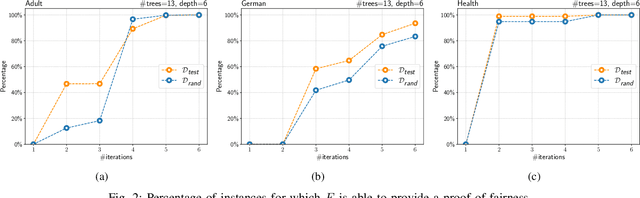
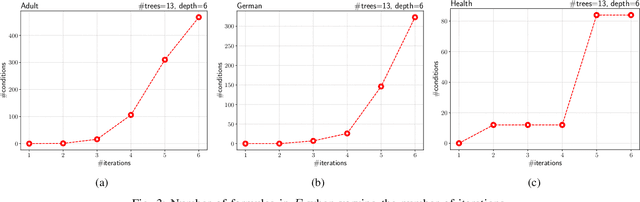
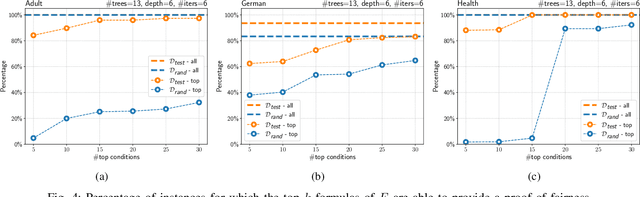
We present a new approach to the global fairness verification of tree-based classifiers. Given a tree-based classifier and a set of sensitive features potentially leading to discrimination, our analysis synthesizes sufficient conditions for fairness, expressed as a set of traditional propositional logic formulas, which are readily understandable by human experts. The verified fairness guarantees are global, in that the formulas predicate over all the possible inputs of the classifier, rather than just a few specific test instances. Our analysis is formally proved both sound and complete. Experimental results on public datasets show that the analysis is precise, explainable to human experts and efficient enough for practical adoption.
Beyond Robustness: Resilience Verification of Tree-Based Classifiers
Dec 05, 2021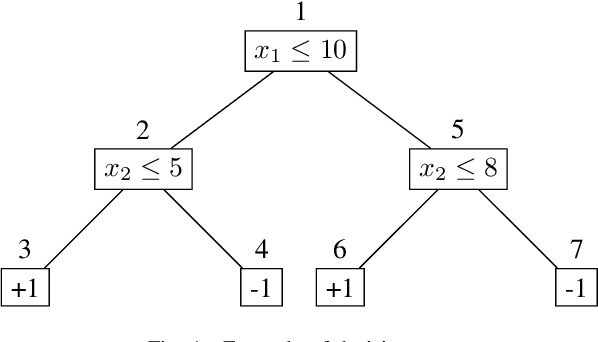
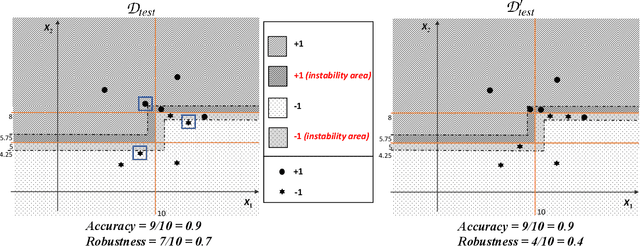

In this paper we criticize the robustness measure traditionally employed to assess the performance of machine learning models deployed in adversarial settings. To mitigate the limitations of robustness, we introduce a new measure called resilience and we focus on its verification. In particular, we discuss how resilience can be verified by combining a traditional robustness verification technique with a data-independent stability analysis, which identifies a subset of the feature space where the model does not change its predictions despite adversarial manipulations. We then introduce a formally sound data-independent stability analysis for decision trees and decision tree ensembles, which we experimentally assess on public datasets and we leverage for resilience verification. Our results show that resilience verification is useful and feasible in practice, yielding a more reliable security assessment of both standard and robust decision tree models.
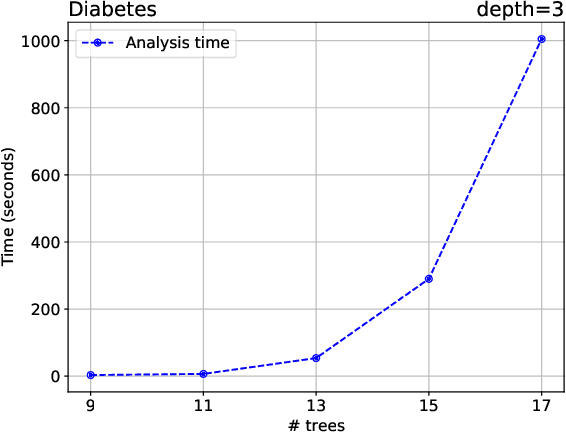
Feature Partitioning for Robust Tree Ensembles and their Certification in Adversarial Scenarios
Apr 07, 2020
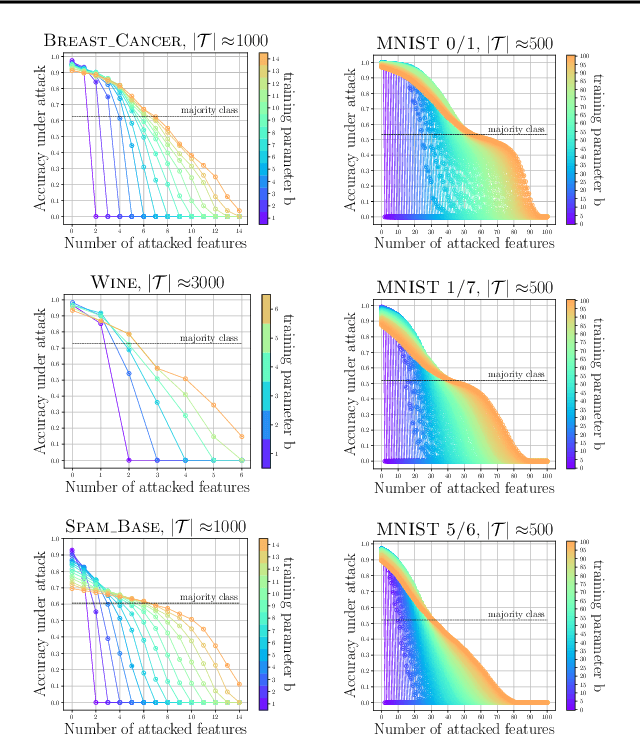
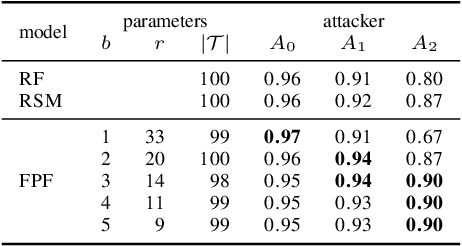

Machine learning algorithms, however effective, are known to be vulnerable in adversarial scenarios where a malicious user may inject manipulated instances. In this work we focus on evasion attacks, where a model is trained in a safe environment and exposed to attacks at test time. The attacker aims at finding a minimal perturbation of a test instance that changes the model outcome. We propose a model-agnostic strategy that builds a robust ensemble by training its basic models on feature-based partitions of the given dataset. Our algorithm guarantees that the majority of the models in the ensemble cannot be affected by the attacker. We experimented the proposed strategy on decision tree ensembles, and we also propose an approximate certification method for tree ensembles that efficiently assess the minimal accuracy of a forest on a given dataset avoiding the costly computation of evasion attacks. Experimental evaluation on publicly available datasets shows that proposed strategy outperforms state-of-the-art adversarial learning algorithms against evasion attacks.