 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Decision Tree Ensembles
Oct 06, 2024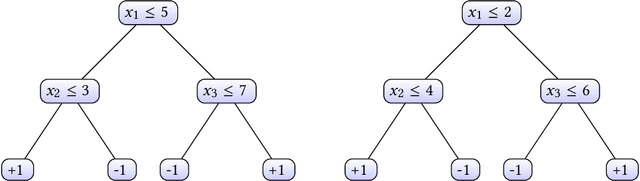


Protecting the intellectual property of machine learning models is a hot topic and many watermarking schemes for deep neural networks have been proposed in the literature. Unfortunately, prior work largely neglected the investigation of watermarking techniques for other types of models, including decision tree ensembles, which are a state-of-the-art model for classification tasks on non-perceptual data. In this paper, we present the first watermarking scheme designed for decision tree ensembles, focusing in particular on random forest models. We discuss watermark creation and verification, presenting a thorough security analysis with respect to possible attacks. We finally perform an experimental evaluation of the proposed scheme, showing excellent results in terms of accuracy and security against the most relevant threats.
Timber! Poisoning Decision Trees
Oct 01, 2024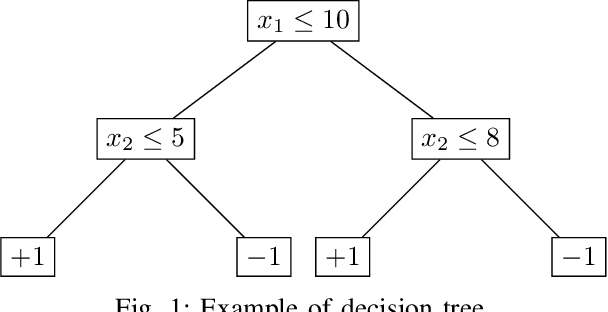
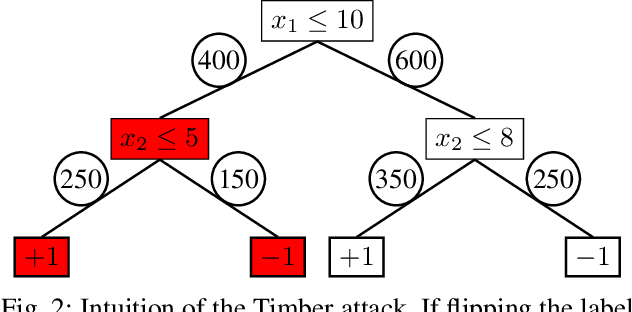

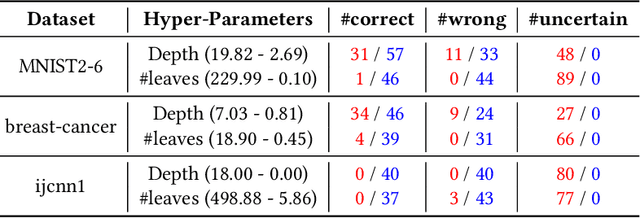
We present Timber, the first white-box poisoning attack targeting decision trees. Timber is based on a greedy attack strategy leveraging sub-tree retraining to efficiently estimate the damage performed by poisoning a given training instance. The attack relies on a tree annotation procedure which enables sorting training instances so that they are processed in increasing order of computational cost of sub-tree retraining. This sorting yields a variant of Timber supporting an early stopping criterion designed to make poisoning attacks more efficient and feasible on larger datasets. We also discuss an extension of Timber to traditional random forest models, which is useful because decision trees are normally combined into ensembles to improve their predictive power. Our experimental evaluation on public datasets shows that our attacks outperform existing baselines in terms of effectiveness, efficiency or both. Moreover, we show that two representative defenses can mitigate the effect of our attacks, but fail at effectively thwarting them.
Verifiable Boosted Tree Ensembles
Feb 22, 2024Verifiable learning advocates for training machine learning models amenable to efficient security verification. Prior research demonstrated that specific classes of decision tree ensembles -- called large-spread ensembles -- allow for robustness verification in polynomial time against any norm-based attacker. This study expands prior work on verifiable learning from basic ensemble methods (i.e., hard majority voting) to advanced boosted tree ensembles, such as those trained using XGBoost or LightGBM. Our formal results indicate that robustness verification is achievable in polynomial time when considering attackers based on the $L_\infty$-norm, but remains NP-hard for other norm-based attackers. Nevertheless, we present a pseudo-polynomial time algorithm to verify robustness against attackers based on the $L_p$-norm for any $p \in \mathbb{N} \cup \{0\}$, which in practice grants excellent performance. Our experimental evaluation shows that large-spread boosted ensembles are accurate enough for practical adoption, while being amenable to efficient security verification.
Verifiable Learning for Robust Tree Ensembles
May 05, 2023Verifying the robustness of machine learning models against evasion attacks at test time is an important research problem. Unfortunately, prior work established that this problem is NP-hard for decision tree ensembles, hence bound to be intractable for specific inputs. In this paper, we identify a restricted class of decision tree ensembles, called large-spread ensembles, which admit a security verification algorithm running in polynomial time. We then propose a new approach called verifiable learning, which advocates the training of such restricted model classes which are amenable for efficient verification. We show the benefits of this idea by designing a new training algorithm that automatically learns a large-spread decision tree ensemble from labelled data, thus enabling its security verification in polynomial time. Experimental results on publicly available datasets confirm that large-spread ensembles trained using our algorithm can be verified in a matter of seconds, using standard commercial hardware. Moreover, large-spread ensembles are more robust than traditional ensembles against evasion attacks, while incurring in just a relatively small loss of accuracy in the non-adversarial setting.
Explainable Global Fairness Verification of Tree-Based Classifiers
Sep 27, 2022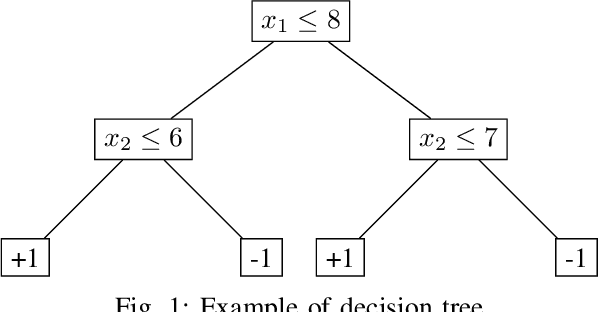
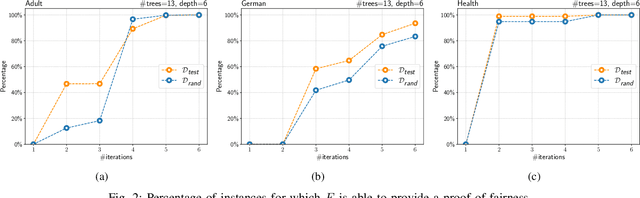
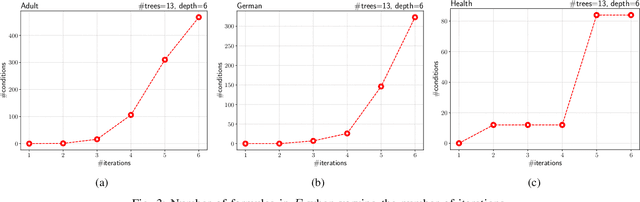
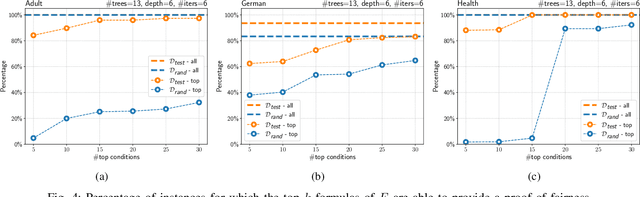
We present a new approach to the global fairness verification of tree-based classifiers. Given a tree-based classifier and a set of sensitive features potentially leading to discrimination, our analysis synthesizes sufficient conditions for fairness, expressed as a set of traditional propositional logic formulas, which are readily understandable by human experts. The verified fairness guarantees are global, in that the formulas predicate over all the possible inputs of the classifier, rather than just a few specific test instances. Our analysis is formally proved both sound and complete. Experimental results on public datasets show that the analysis is precise, explainable to human experts and efficient enough for practical adoption.
Beyond Robustness: Resilience Verification of Tree-Based Classifiers
Dec 05, 2021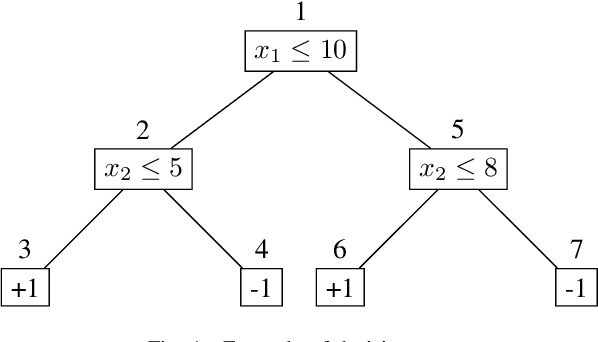
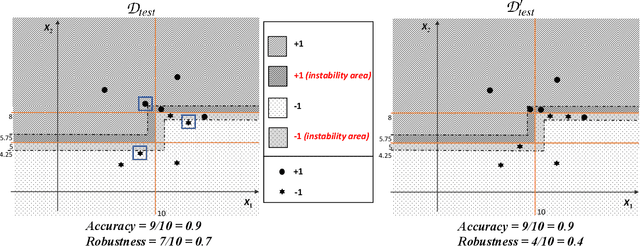

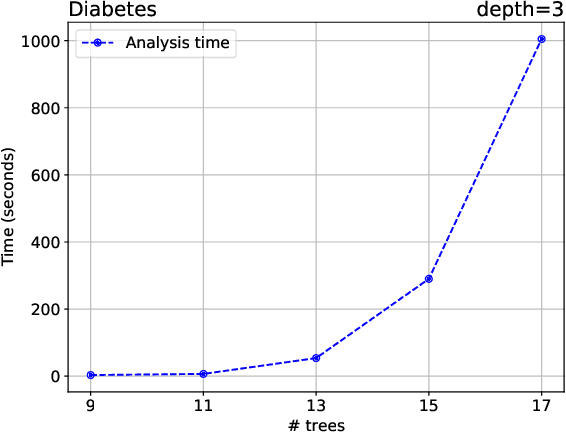
In this paper we criticize the robustness measure traditionally employed to assess the performance of machine learning models deployed in adversarial settings. To mitigate the limitations of robustness, we introduce a new measure called resilience and we focus on its verification. In particular, we discuss how resilience can be verified by combining a traditional robustness verification technique with a data-independent stability analysis, which identifies a subset of the feature space where the model does not change its predictions despite adversarial manipulations. We then introduce a formally sound data-independent stability analysis for decision trees and decision tree ensembles, which we experimentally assess on public datasets and we leverage for resilience verification. Our results show that resilience verification is useful and feasible in practice, yielding a more reliable security assessment of both standard and robust decision tree models.
Certifying Decision Trees Against Evasion Attacks by Program Analysis
Jul 06, 2020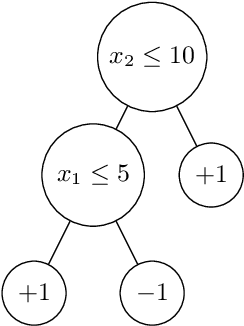


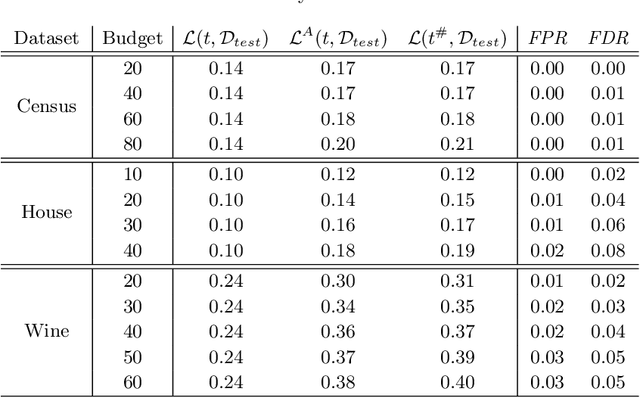
Machine learning has proved invaluable for a range of different tasks, yet it also proved vulnerable to evasion attacks, i.e., maliciously crafted perturbations of input data designed to force mispredictions. In this paper we propose a novel technique to verify the security of decision tree models against evasion attacks with respect to an expressive threat model, where the attacker can be represented by an arbitrary imperative program. Our approach exploits the interpretability property of decision trees to transform them into imperative programs, which are amenable for traditional program analysis techniques. By leveraging the abstract interpretation framework, we are able to soundly verify the security guarantees of decision tree models trained over publicly available datasets. Our experiments show that our technique is both precise and efficient, yielding only a minimal number of false positives and scaling up to cases which are intractable for a competitor approach.
Feature Partitioning for Robust Tree Ensembles and their Certification in Adversarial Scenarios
Apr 07, 2020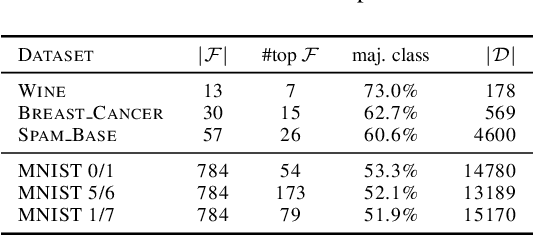
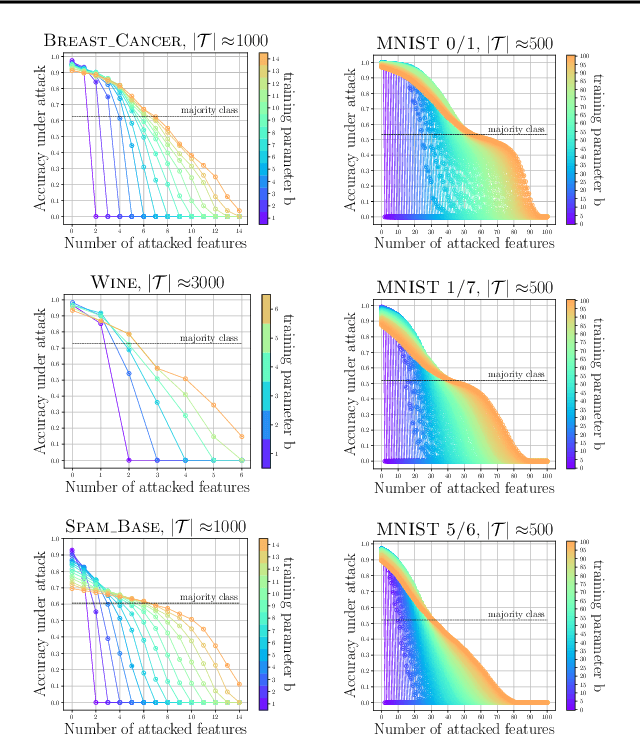
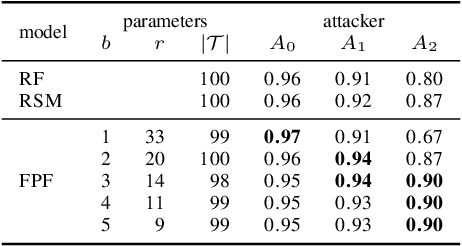

Machine learning algorithms, however effective, are known to be vulnerable in adversarial scenarios where a malicious user may inject manipulated instances. In this work we focus on evasion attacks, where a model is trained in a safe environment and exposed to attacks at test time. The attacker aims at finding a minimal perturbation of a test instance that changes the model outcome. We propose a model-agnostic strategy that builds a robust ensemble by training its basic models on feature-based partitions of the given dataset. Our algorithm guarantees that the majority of the models in the ensemble cannot be affected by the attacker. We experimented the proposed strategy on decision tree ensembles, and we also propose an approximate certification method for tree ensembles that efficiently assess the minimal accuracy of a forest on a given dataset avoiding the costly computation of evasion attacks. Experimental evaluation on publicly available datasets shows that proposed strategy outperforms state-of-the-art adversarial learning algorithms against evasion attacks.
Treant: Training Evasion-Aware Decision Trees
Jul 03, 2019
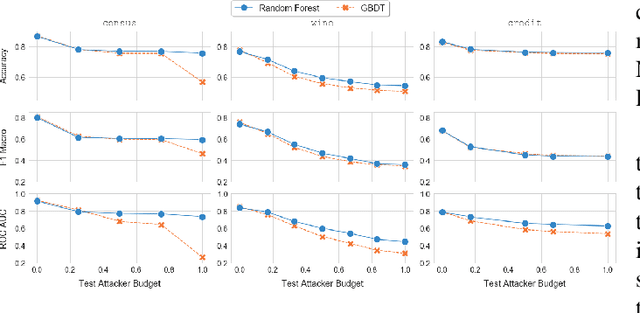
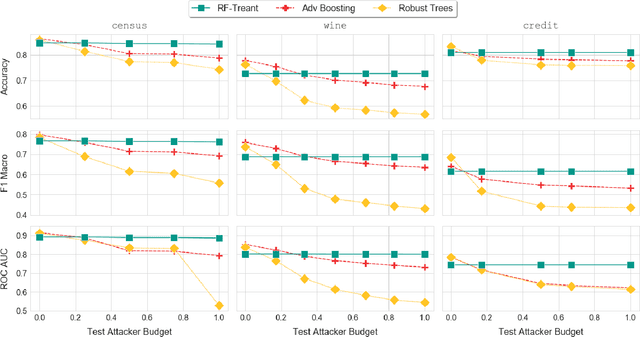

Despite its success and popularity, machine learning is now recognized as vulnerable to evasion attacks, i.e., carefully crafted perturbations of test inputs designed to force prediction errors. In this paper we focus on evasion attacks against decision tree ensembles, which are among the most successful predictive models for dealing with non-perceptual problems. Even though they are powerful and interpretable, decision tree ensembles have received only limited attention by the security and machine learning communities so far, leading to a sub-optimal state of the art for adversarial learning techniques. We thus propose Treant, a novel decision tree learning algorithm that, on the basis of a formal threat model, minimizes an evasion-aware loss function at each step of the tree construction. Treant is based on two key technical ingredients: robust splitting and attack invariance, which jointly guarantee the soundness of the learning process. Experimental results on three publicly available datasets show that Treant is able to generate decision tree ensembles that are at the same time accurate and nearly insensitive to evasion attacks, outperforming state-of-the-art adversarial learning techniques.