 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISE: A Rust Library for Inverted Index Search Engines
Jun 05, 2026Inverted indexes are a crucial data structure for efficient information retrieval in large text corpora. They enable fast full-text search by mapping each term to the documents in which it appears, on top of which efficient algorithms quickly retrieve the documents relevant to a user query. We present RISE, a novel inverted index library implemented in Rust, designed to deliver high performance and efficiency for information retrieval tasks. RISE leverages Rust's safety and performance to provide a robust solution for building and querying inverted indexes, while offering accessible extensibility through its expressive trait system. While developing RISE, we revisited the inverted-index literature, thereby reproducing numerous prior works using this new test bench. We evaluated RISE against existing libraries, demonstrating competitive query performance across various datasets and workloads, with speedups of up to 2x over the current state of the art. Our results indicate that RISE is a promising tool for researchers and practitioners in the field of information retrieval.
Sparton: Fast and Memory-Efficient Triton Kernel for Learned Sparse Retrieval
Mar 26, 2026State-of-the-art Learned Sparse Retrieval (LSR) models, such as Splade, typically employ a Language Modeling (LM) head to project latent hidden states into a lexically-anchored logit matrix. This intermediate matrix is subsequently transformed into a sparse lexical representation through element-wise operations (ReLU, Log1P) and max-pooling over the sequence dimension. Despite its effectiveness, the LM head creates a massive memory bottleneck due to the sheer size of the vocabulary (V), which can range from 30,000 to over 250,000 tokens in recent models. Materializing this matrix creates a significant memory bottleneck, limiting model scaling. The resulting I/O overhead between operators further throttles throughput and runtime performance. In this paper, we propose Sparton, a fast memory-efficient Triton kernel tailored for the LM head in LSR models. Sparton utilizes a fused approach that integrates the tiled matrix multiplication, ReLU, Log1P, and max-reduction into a single GPU kernel. By performing an early online reduction directly on raw logit tiles, Sparton avoids materializing the full logit matrix in memory. Our experiments demonstrate that the Sparton kernel, in isolation, achieves up to a 4.8x speedup and an order-of-magnitude reduction in peak memory usage compared to PyTorch baselines. Integrated into Splade (|V| ~ 30k), Sparton enables a 33% larger batch size and 14% faster training with no effectiveness loss. On a multilingual backbone (|V| ~ 250k), these gains jump to a 26x larger batch size and 2.5x faster training.
Forward Index Compression for Learned Sparse Retrieval
Feb 05, 2026Text retrieval using learned sparse representations of queries and documents has, over the years, evolved into a highly effective approach to search. It is thanks to recent advances in approximate nearest neighbor search-with the emergence of highly efficient algorithms such as the inverted index-based Seismic and the graph-based Hnsw-that retrieval with sparse representations became viable in practice. In this work, we scrutinize the efficiency of sparse retrieval algorithms and focus particularly on the size of a data structure that is common to all algorithmic flavors and that constitutes a substantial fraction of the overall index size: the forward index. In particular, we seek compression techniques to reduce the storage footprint of the forward index without compromising search quality or inner product computation latency. In our examination with various integer compression techniques, we report that StreamVByte achieves the best trade-off between memory footprint, retrieval accuracy, and latency. We then improve StreamVByte by introducing DotVByte, a new algorithm tailored to inner product computation. Experiments on MsMarco show that our improvements lead to significant space savings while maintaining retrieval efficiency.
Multivector Reranking in the Era of Strong First-Stage Retrievers
Jan 08, 2026Learned multivector representations power modern search systems with strong retrieval effectiveness, but their real-world use is limited by the high cost of exhaustive token-level retrieval. Therefore, most systems adopt a \emph{gather-and-refine} strategy, where a lightweight gather phase selects candidates for full scoring. However, this approach requires expensive searches over large token-level indexes and often misses the documents that would rank highest under full similarity. In this paper, we reproduce several state-of-the-art multivector retrieval methods on two publicly available datasets, providing a clear picture of the current multivector retrieval field and observing the inefficiency of token-level gathering. Building on top of that, we show that replacing the token-level gather phase with a single-vector document retriever -- specifically, a learned sparse retriever (LSR) -- produces a smaller and more semantically coherent candidate set. This recasts the gather-and-refine pipeline into the well-established two-stage retrieval architecture. As retrieval latency decreases, query encoding with two neural encoders becomes the dominant computational bottleneck. To mitigate this, we integrate recent inference-free LSR methods, demonstrating that they preserve the retrieval effectiveness of the dual-encoder pipeline while substantially reducing query encoding time. Finally, we investigate multiple reranking configurations that balance efficiency, memory, and effectiveness, and we introduce two optimization techniques that prune low-quality candidates early. Empirical results show that these techniques improve retrieval efficiency by up to 1.8$\times$ with no loss in quality. Overall, our two-stage approach achieves over $24\times$ speedup over the state-of-the-art multivector retrieval systems, while maintaining comparable or superior retrieval quality.
Effective Inference-Free Retrieval for Learned Sparse Representations
Apr 30, 2025Learned Sparse Retrieval (LSR) is an effective IR approach that exploits pre-trained language models for encoding text into a learned bag of words. Several efforts in the literature have shown that sparsity is key to enabling a good trade-off between the efficiency and effectiveness of the query processor. To induce the right degree of sparsity, researchers typically use regularization techniques when training LSR models. Recently, new efficient -- inverted index-based -- retrieval engines have been proposed, leading to a natural question: has the role of regularization changed in training LSR models? In this paper, we conduct an extended evaluation of regularization approaches for LSR where we discuss their effectiveness, efficiency, and out-of-domain generalization capabilities. We first show that regularization can be relaxed to produce more effective LSR encoders. We also show that query encoding is now the bottleneck limiting the overall query processor performance. To remove this bottleneck, we advance the state-of-the-art of inference-free LSR by proposing Learned Inference-free Retrieval (Li-LSR). At training time, Li-LSR learns a score for each token, casting the query encoding step into a seamless table lookup. Our approach yields state-of-the-art effectiveness for both in-domain and out-of-domain evaluation, surpassing Splade-v3-Doc by 1 point of mRR@10 on MS MARCO and 1.8 points of nDCG@10 on BEIR.
Investigating the Scalability of Approximate Sparse Retrieval Algorithms to Massive Datasets
Jan 20, 2025


Learned sparse text embeddings have gained popularity due to their effectiveness in top-k retrieval and inherent interpretability. Their distributional idiosyncrasies, however, have long hindered their use in real-world retrieval systems. That changed with the recent development of approximate algorithms that leverage the distributional properties of sparse embeddings to speed up retrieval. Nonetheless, in much of the existing literature, evaluation has been limited to datasets with only a few million documents such as MSMARCO. It remains unclear how these systems behave on much larger datasets and what challenges lurk in larger scales. To bridge that gap, we investigate the behavior of state-of-the-art retrieval algorithms on massive datasets. We compare and contrast the recently-proposed Seismic and graph-based solutions adapted from dense retrieval. We extensively evaluate Splade embeddings of 138M passages from MsMarco-v2 and report indexing time and other efficiency and effectiveness metrics.
kANNolo: Sweet and Smooth Approximate k-Nearest Neighbors Search
Jan 10, 2025Approximate Nearest Neighbors (ANN) search is a crucial task in several applications like recommender systems and information retrieval. Current state-of-the-art ANN libraries, although being performance-oriented, often lack modularity and ease of use. This translates into them not being fully suitable for easy prototyping and testing of research ideas, an important feature to enable. We address these limitations by introducing kANNolo, a novel research-oriented ANN library written in Rust and explicitly designed to combine usability with performance effectively. kANNolo is the first ANN library that supports dense and sparse vector representations made available on top of different similarity measures, e.g., euclidean distance and inner product. Moreover, it also supports vector quantization techniques, e.g., Product Quantization, on top of the indexing strategies implemented. These functionalities are managed through Rust traits, allowing shared behaviors to be handled abstractly. This abstraction ensures flexibility and facilitates an easy integration of new components. In this work, we detail the architecture of kANNolo and demonstrate that its flexibility does not compromise performance. The experimental analysis shows that kANNolo achieves state-of-the-art performance in terms of speed-accuracy trade-off while allowing fast and easy prototyping, thus making kANNolo a valuable tool for advancing ANN research. Source code available on GitHub: https://github.com/TusKANNy/kannolo.
Pairing Clustered Inverted Indexes with kNN Graphs for Fast Approximate Retrieval over Learned Sparse Representations
Aug 08, 2024



Learned sparse representations form an effective and interpretable class of embeddings for text retrieval. While exact top-k retrieval over such embeddings faces efficiency challenges, a recent algorithm called Seismic has enabled remarkably fast, highly-accurate approximate retrieval. Seismic statically prunes inverted lists, organizes each list into geometrically-cohesive blocks, and augments each block with a summary vector. At query time, each inverted list associated with a query term is traversed one block at a time in an arbitrary order, with the inner product between the query and summaries determining if a block must be evaluated. When a block is deemed promising, its documents are fully evaluated with a forward index. Seismic is one to two orders of magnitude faster than state-of-the-art inverted index-based solutions and significantly outperforms the winning graph-based submissions to the BigANN 2023 Challenge. In this work, we speed up Seismic further by introducing two innovations to its query processing subroutine. First, we traverse blocks in order of importance, rather than arbitrarily. Second, we take the list of documents retrieved by Seismic and expand it to include the neighbors of each document using an offline k-regular nearest neighbor graph; the expanded list is then ranked to produce the final top-k set. Experiments on two public datasets show that our extension, named SeismicWave, can reach almost-exact accuracy levels and is up to 2.2x faster than Seismic.
Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations
Apr 29, 2024



Learned sparse representations form an attractive class of contextual embeddings for text retrieval. That is so because they are effective models of relevance and are interpretable by design. Despite their apparent compatibility with inverted indexes, however, retrieval over sparse embeddings remains challenging. That is due to the distributional differences between learned embeddings and term frequency-based lexical models of relevance such as BM25. Recognizing this challenge, a great deal of research has gone into, among other things, designing retrieval algorithms tailored to the properties of learned sparse representations, including approximate retrieval systems. In fact, this task featured prominently in the latest BigANN Challenge at NeurIPS 2023, where approximate algorithms were evaluated on a large benchmark dataset by throughput and recall. In this work, we propose a novel organization of the inverted index that enables fast yet effective approximate retrieval over learned sparse embeddings. Our approach organizes inverted lists into geometrically-cohesive blocks, each equipped with a summary vector. During query processing, we quickly determine if a block must be evaluated using the summaries. As we show experimentally, single-threaded query processing using our method, Seismic, reaches sub-millisecond per-query latency on various sparse embeddings of the MS MARCO dataset while maintaining high recall. Our results indicate that Seismic is one to two orders of magnitude faster than state-of-the-art inverted index-based solutions and further outperforms the winning (graph-based) submissions to the BigANN Challenge by a significant margin.
Efficient Multi-Vector Dense Retrieval Using Bit Vectors
Apr 03, 2024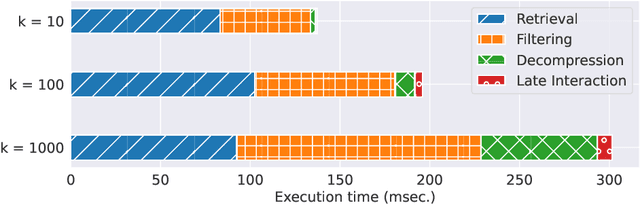
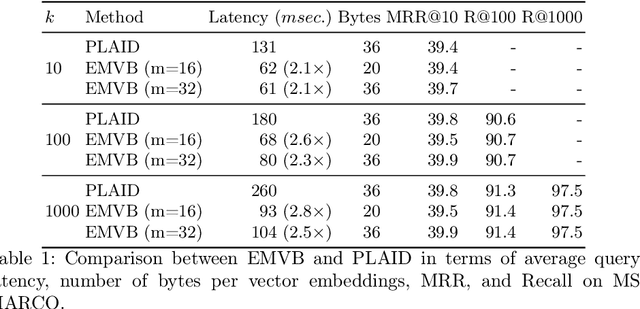
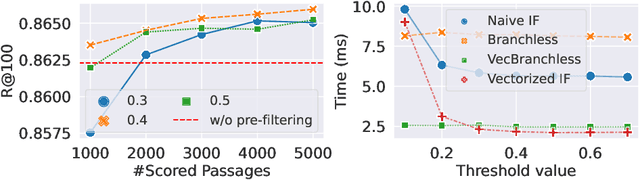

Dense retrieval techniques employ pre-trained large language models to build a high-dimensional representation of queries and passages. These representations compute the relevance of a passage w.r.t. to a query using efficient similarity measures. In this line, multi-vector representations show improved effectiveness at the expense of a one-order-of-magnitude increase in memory footprint and query latency by encoding queries and documents on a per-token level. Recently, PLAID has tackled these problems by introducing a centroid-based term representation to reduce the memory impact of multi-vector systems. By exploiting a centroid interaction mechanism, PLAID filters out non-relevant documents, thus reducing the cost of the successive ranking stages. This paper proposes ``Efficient Multi-Vector dense retrieval with Bit vectors'' (EMVB), a novel framework for efficient query processing in multi-vector dense retrieval. First, EMVB employs a highly efficient pre-filtering step of passages using optimized bit vectors. Second, the computation of the centroid interaction happens column-wise, exploiting SIMD instructions, thus reducing its latency. Third, EMVB leverages Product Quantization (PQ) to reduce the memory footprint of storing vector representations while jointly allowing for fast late interaction. Fourth, we introduce a per-document term filtering method that further improves the efficiency of the last step. Experiments on MS MARCO and LoTTE show that EMVB is up to 2.8x faster while reducing the memory footprint by 1.8x with no loss in retrieval accuracy compared to PLAID.