 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop overkilling simple tasks with black-box models and use transparent models instead
Feb 06, 2023
In recent years, the employment of deep learning methods has led to several significant breakthroughs in artificial intelligence. Different from traditional machine learning models, deep learning-based approaches are able to extract features autonomously from raw data. This allows for bypassing the feature engineering process, which is generally considered to be both error-prone and tedious. Moreover, deep learning strategies often outperform traditional models in terms of accuracy.
Fruit Ripeness Classification: a Survey
Dec 29, 2022Fruit is a key crop in worldwide agriculture feeding millions of people. The standard supply chain of fruit products involves quality checks to guarantee freshness, taste, and, most of all, safety. An important factor that determines fruit quality is its stage of ripening. This is usually manually classified by experts in the field, which makes it a labor-intensive and error-prone process. Thus, there is an arising need for automation in the process of fruit ripeness classification. Many automatic methods have been proposed that employ a variety of feature descriptors for the food item to be graded. Machine learning and deep learning techniques dominate the top-performing methods. Furthermore, deep learning can operate on raw data and thus relieve the users from having to compute complex engineered features, which are often crop-specific. In this survey, we review the latest methods proposed in the literature to automatize fruit ripeness classification, highlighting the most common feature descriptors they operate on.
A Theoretical Framework for AI Models Explainability
Dec 29, 2022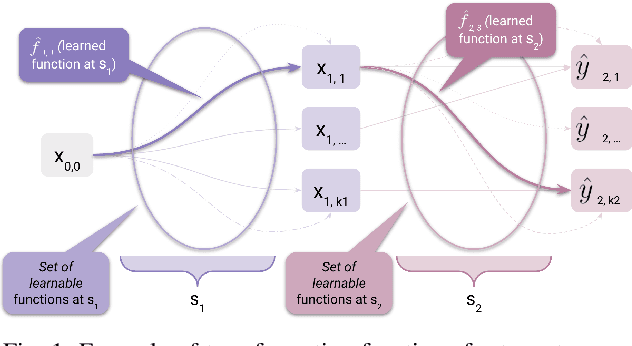
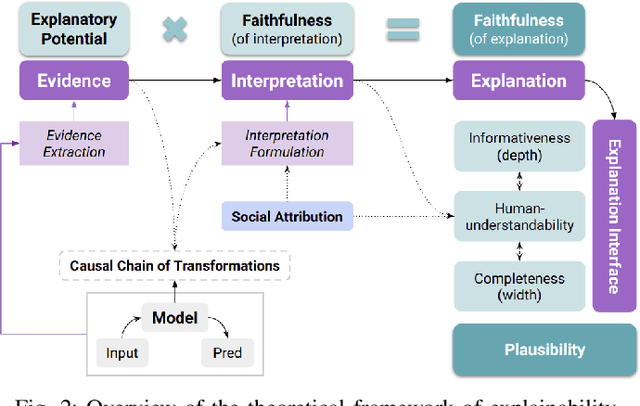
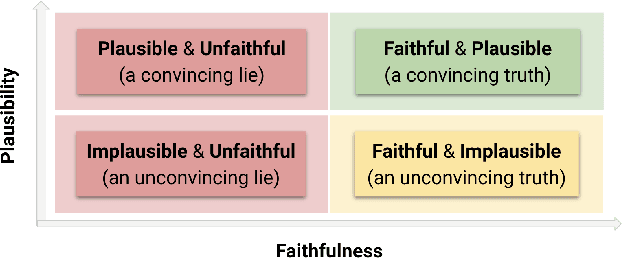
Explainability is a vibrant research topic in the artificial intelligence community, with growing interest across methods and domains. Much has been written about the topic, yet explainability still lacks shared terminology and a framework capable of providing structural soundness to explanations. In our work, we address these issues by proposing a novel definition of explanation that is a synthesis of what can be found in the literature. We recognize that explanations are not atomic but the product of evidence stemming from the model and its input-output and the human interpretation of this evidence. Furthermore, we fit explanations into the properties of faithfulness (i.e., the explanation being a true description of the model's decision-making) and plausibility (i.e., how much the explanation looks convincing to the user). Using our proposed theoretical framework simplifies how these properties are ope rationalized and provide new insight into common explanation methods that we analyze as case studies.
Evaluating the Faithfulness of Saliency-based Explanations for Deep Learning Models for Temporal Colour Constancy
Nov 15, 2022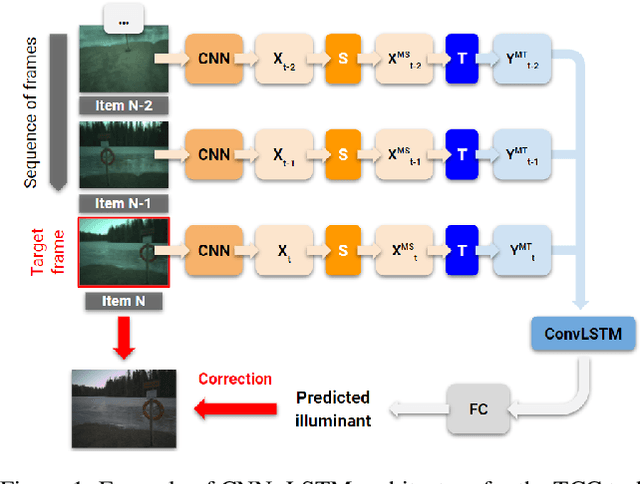
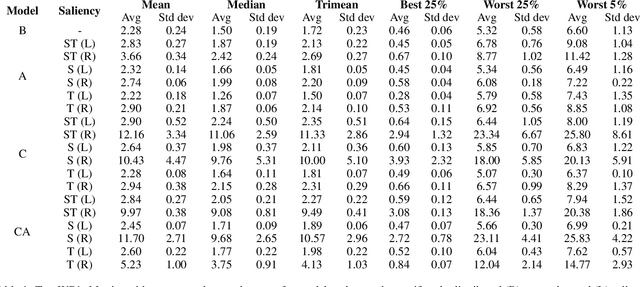

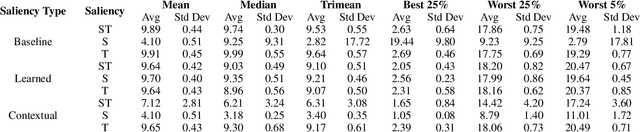
The opacity of deep learning models constrains their debugging and improvement. Augmenting deep models with saliency-based strategies, such as attention, has been claimed to help get a better understanding of the decision-making process of black-box models. However, some recent works challenged saliency's faithfulness in the field of Natural Language Processing (NLP), questioning attention weights' adherence to the true decision-making process of the model. We add to this discussion by evaluating the faithfulness of in-model saliency applied to a video processing task for the first time, namely, temporal colour constancy. We perform the evaluation by adapting to our target task two tests for faithfulness from recent NLP literature, whose methodology we refine as part of our contributions. We show that attention fails to achieve faithfulness, while confidence, a particular type of in-model visual saliency, succeeds.
Cascading Convolutional Temporal Colour Constancy
Jun 15, 2021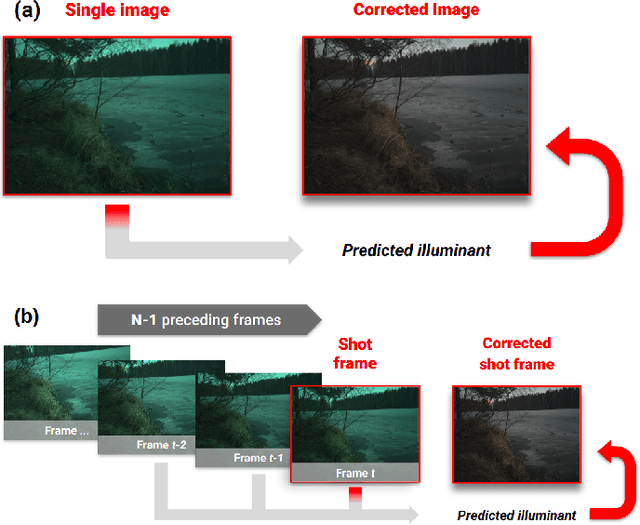
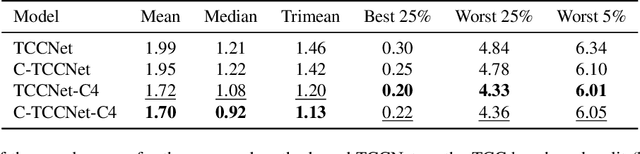
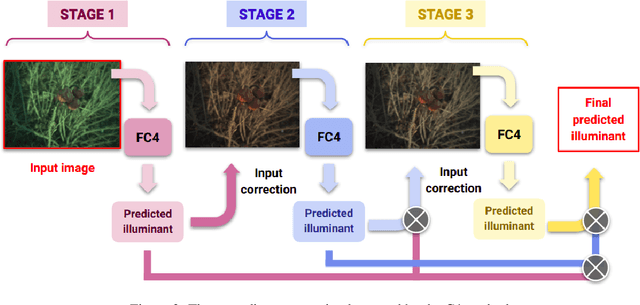
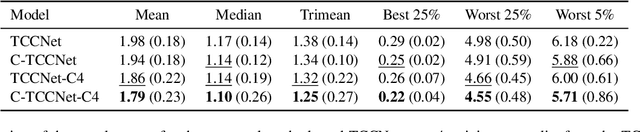
Computational Colour Constancy (CCC) consists of estimating the colour of one or more illuminants in a scene and using them to remove unwanted chromatic distortions. Much research has focused on illuminant estimation for CCC on single images, with few attempts of leveraging the temporal information intrinsic in sequences of correlated images (e.g., the frames in a video), a task known as Temporal Colour Constancy (TCC). The state-of-the-art for TCC is TCCNet, a deep-learning architecture that uses a ConvLSTM for aggregating the encodings produced by CNN submodules for each image in a sequence. We extend this architecture with different models obtained by (i) substituting the TCCNet submodules with C4, the state-of-the-art method for CCC targeting images; (ii) adding a cascading strategy to perform an iterative improvement of the estimate of the illuminant. We tested our models on the recently released TCC benchmark and achieved results that surpass the state-of-the-art. Analyzing the impact of the number of frames involved in illuminant estimation on performance, we show that it is possible to reduce inference time by training the models on few selected frames from the sequences while retaining comparable accuracy.