 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Faithfulness of Saliency-based Explanations for Deep Learning Models for Temporal Colour Constancy
Paper and Code
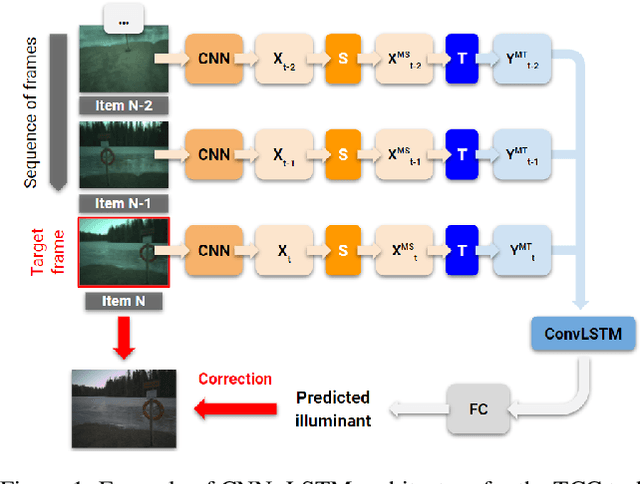
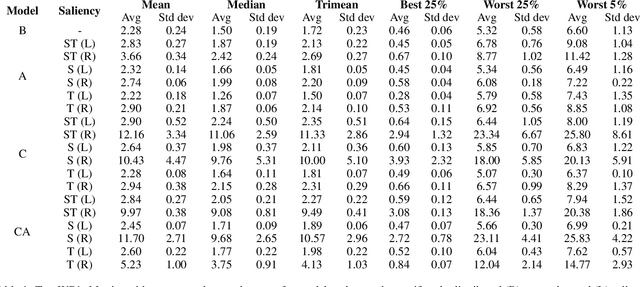

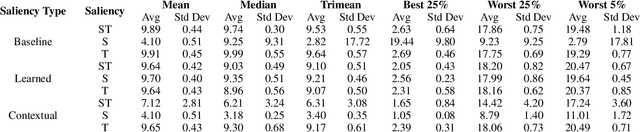
The opacity of deep learning models constrains their debugging and improvement. Augmenting deep models with saliency-based strategies, such as attention, has been claimed to help get a better understanding of the decision-making process of black-box models. However, some recent works challenged saliency's faithfulness in the field of Natural Language Processing (NLP), questioning attention weights' adherence to the true decision-making process of the model. We add to this discussion by evaluating the faithfulness of in-model saliency applied to a video processing task for the first time, namely, temporal colour constancy. We perform the evaluation by adapting to our target task two tests for faithfulness from recent NLP literature, whose methodology we refine as part of our contributions. We show that attention fails to achieve faithfulness, while confidence, a particular type of in-model visual saliency, succeeds.