 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Inference of Tree Ensembles on ARM Devices
May 15, 2023With the ongoing integration of Machine Learning models into everyday life, e.g. in the form of the Internet of Things (IoT), the evaluation of learned models becomes more and more an important issue. Tree ensembles are one of the best black-box classifiers available and routinely outperform more complex classifiers. While the fast application of tree ensembles has already been studied in the literature for Intel CPUs, they have not yet been studied in the context of ARM CPUs which are more dominant for IoT applications. In this paper, we convert the popular QuickScorer algorithm and its siblings from Intel's AVX to ARM's NEON instruction set. Second, we extend our implementation from ranking models to classification models such as Random Forests. Third, we investigate the effects of using fixed-point quantization in Random Forests. Our study shows that a careful implementation of tree traversal on ARM CPUs leads to a speed-up of up to 9.4 compared to a reference implementation. Moreover, quantized models seem to outperform models using floating-point values in terms of speed in almost all cases, with a neglectable impact on the predictive performance of the model. Finally, our study highlights architectural differences between ARM and Intel CPUs and between different ARM devices that imply that the best implementation depends on both the specific forest as well as the specific device used for deployment.
Energy Efficiency Considerations for Popular AI Benchmarks
Apr 17, 2023Advances in artificial intelligence need to become more resource-aware and sustainable. This requires clear assessment and reporting of energy efficiency trade-offs, like sacrificing fast running time for higher predictive performance. While first methods for investigating efficiency have been proposed, we still lack comprehensive results for popular methods and data sets. In this work, we attempt to fill this information gap by providing empiric insights for popular AI benchmarks, with a total of 100 experiments. Our findings are evidence of how different data sets all have their own efficiency landscape, and show that methods can be more or less likely to act efficiently.
Shrub Ensembles for Online Classification
Dec 07, 2021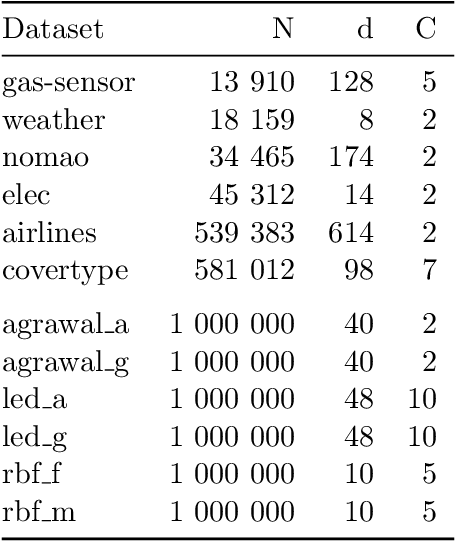
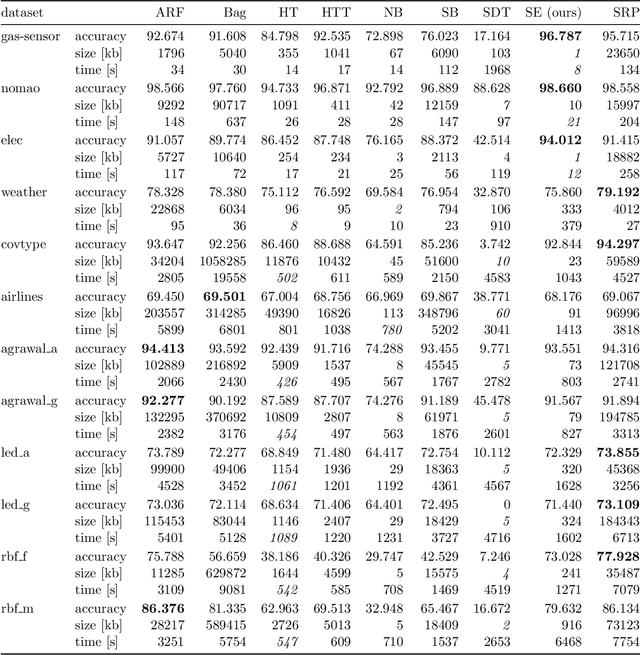
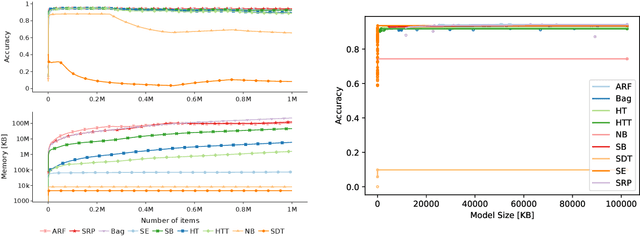
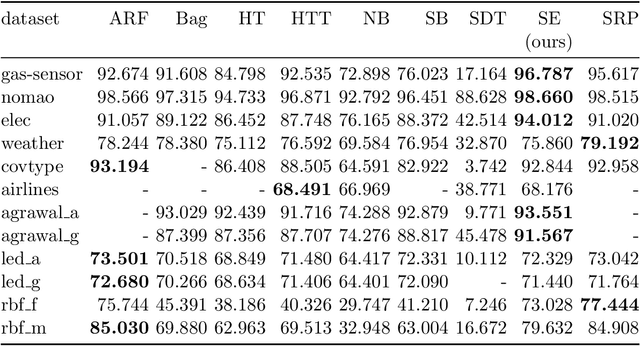
Online learning algorithms have become a ubiquitous tool in the machine learning toolbox and are frequently used in small, resource-constraint environments. Among the most successful online learning methods are Decision Tree (DT) ensembles. DT ensembles provide excellent performance while adapting to changes in the data, but they are not resource efficient. Incremental tree learners keep adding new nodes to the tree but never remove old ones increasing the memory consumption over time. Gradient-based tree learning, on the other hand, requires the computation of gradients over the entire tree which is costly for even moderately sized trees. In this paper, we propose a novel memory-efficient online classification ensemble called shrub ensembles for resource-constraint systems. Our algorithm trains small to medium-sized decision trees on small windows and uses stochastic proximal gradient descent to learn the ensemble weights of these `shrubs'. We provide a theoretical analysis of our algorithm and include an extensive discussion on the behavior of our approach in the online setting. In a series of 2~959 experiments on 12 different datasets, we compare our method against 8 state-of-the-art methods. Our Shrub Ensembles retain an excellent performance even when only little memory is available. We show that SE offers a better accuracy-memory trade-off in 7 of 12 cases, while having a statistically significant better performance than most other methods. Our implementation is available under https://github.com/sbuschjaeger/se-online .
There is no Double-Descent in Random Forests
Nov 08, 2021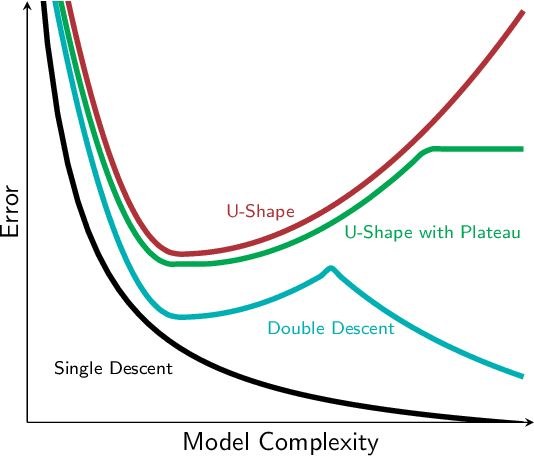


Random Forests (RFs) are among the state-of-the-art in machine learning and offer excellent performance with nearly zero parameter tuning. Remarkably, RFs seem to be impervious to overfitting even though their basic building blocks are well-known to overfit. Recently, a broadly received study argued that a RF exhibits a so-called double-descent curve: First, the model overfits the data in a u-shaped curve and then, once a certain model complexity is reached, it suddenly improves its performance again. In this paper, we challenge the notion that model capacity is the correct tool to explain the success of RF and argue that the algorithm which trains the model plays a more important role than previously thought. We show that a RF does not exhibit a double-descent curve but rather has a single descent. Hence, it does not overfit in the classic sense. We further present a RF variation that also does not overfit although its decision boundary approximates that of an overfitted DT. Similar, we show that a DT which approximates the decision boundary of a RF will still overfit. Last, we study the diversity of an ensemble as a tool the estimate its performance. To do so, we introduce Negative Correlation Forest (NCForest) which allows for precise control over the diversity in the ensemble. We show, that the diversity and the bias indeed have a crucial impact on the performance of the RF. Having too low diversity collapses the performance of the RF into a a single tree, whereas having too much diversity means that most trees do not produce correct outputs anymore. However, in-between these two extremes we find a large range of different trade-offs with all roughly equal performance. Hence, the specific trade-off between bias and diversity does not matter as long as the algorithm reaches this good trade-off regime.
Improving the Accuracy-Memory Trade-Off of Random Forests Via Leaf-Refinement
Oct 19, 2021


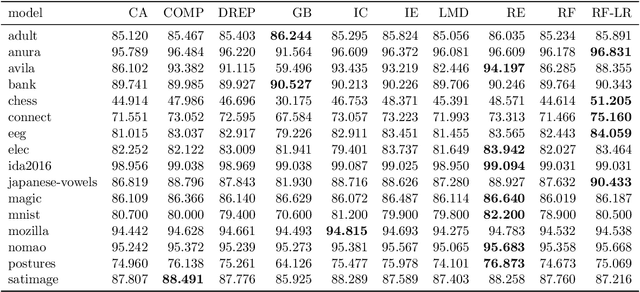
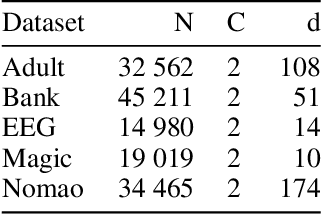
Random Forests (RF) are among the state-of-the-art in many machine learning applications. With the ongoing integration of ML models into everyday life, the deployment and continuous application of models becomes more and more an important issue. Hence, small models which offer good predictive performance but use small amounts of memory are required. Ensemble pruning is a standard technique to remove unnecessary classifiers from an ensemble to reduce the overall resource consumption and sometimes even improve the performance of the original ensemble. In this paper, we revisit ensemble pruning in the context of `modernly' trained Random Forests where trees are very large. We show that the improvement effects of pruning diminishes for ensembles of large trees but that pruning has an overall better accuracy-memory trade-off than RF. However, pruning does not offer fine-grained control over this trade-off because it removes entire trees from the ensemble. To further improve the accuracy-memory trade-off we present a simple, yet surprisingly effective algorithm that refines the predictions in the leaf nodes in the forest via stochastic gradient descent. We evaluate our method against 7 state-of-the-art pruning methods and show that our method outperforms the other methods on 11 of 16 datasets with a statistically significant better accuracy-memory trade-off compared to most methods. We conclude our experimental evaluation with a case study showing that our method can be applied in a real-world setting.
Explaining Deep Learning Representations by Tracing the Training Process
Sep 13, 2021



We propose a novel explanation method that explains the decisions of a deep neural network by investigating how the intermediate representations at each layer of the deep network were refined during the training process. This way we can a) find the most influential training examples during training and b) analyze which classes attributed most to the final representation. Our method is general: it can be wrapped around any iterative optimization procedure and covers a variety of neural network architectures, including feed-forward networks and convolutional neural networks. We first propose a method for stochastic training with single training instances, but continue to also derive a variant for the common mini-batch training. In experimental evaluations, we show that our method identifies highly representative training instances that can be used as an explanation. Additionally, we propose a visualization that provides explanations in the form of aggregated statistics over the whole training process.
Noisy Labels for Weakly Supervised Gamma Hadron Classification
Aug 30, 2021



Gamma hadron classification, a central machine learning task in gamma ray astronomy, is conventionally tackled with supervised learning. However, the supervised approach requires annotated training data to be produced in sophisticated and costly simulations. We propose to instead solve gamma hadron classification with a noisy label approach that only uses unlabeled data recorded by the real telescope. To this end, we employ the significance of detection as a learning criterion which addresses this form of weak supervision. We show that models which are based on the significance of detection deliver state-of-the-art results, despite being exclusively trained with noisy labels; put differently, our models do not require the costly simulated ground-truth labels that astronomers otherwise employ for classifier training. Our weakly supervised models exhibit competitive performances also on imbalanced data sets that stem from a variety of other application domains. In contrast to existing work on class-conditional label noise, we assume that only one of the class-wise noise rates is known.
The Care Label Concept: A Certification Suite for Trustworthy and Resource-Aware Machine Learning
Jun 01, 2021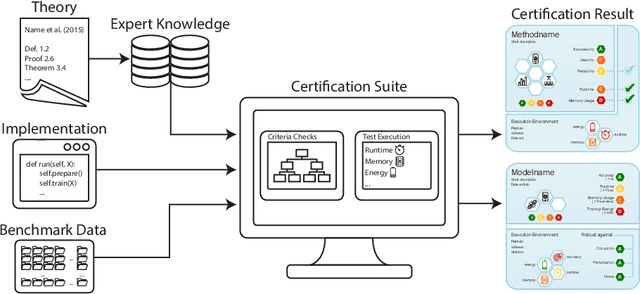
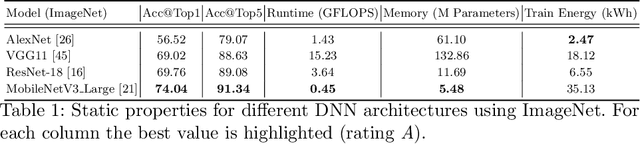
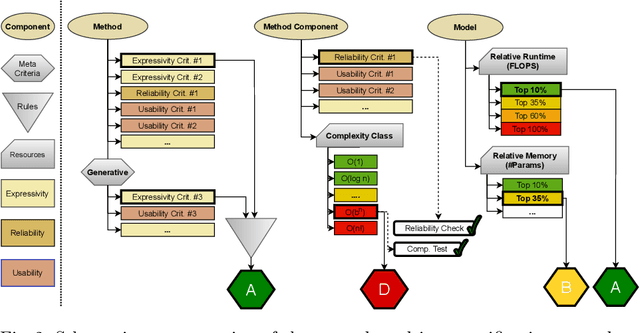
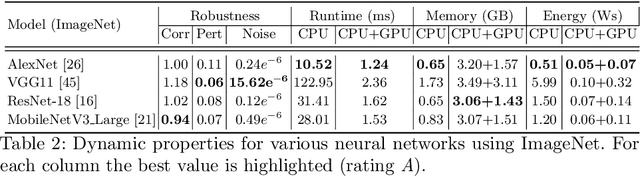
Machine learning applications have become ubiquitous. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. For those who do not want to invest time into understanding the method or the learned model, we offer care labels: easy to understand at a glance, allowing for method or model comparisons, and, at the same time, scientifically well-based. On one hand, this transforms descriptions as given by, e.g., Fact Sheets or Model Cards, into a form that is well-suited for end-users. On the other hand, care labels are the result of a certification suite that tests whether stated guarantees hold. In this paper, we present two experiments with our certification suite. One shows the care labels for configurations of Markov random fields (MRFs). Based on the underlying theory of MRFs, each choice leads to its specific rating of static properties like, e.g., expressivity and reliability. In addition, the implementation is tested and resource consumption is measured yielding dynamic properties. This two-level procedure is followed by another experiment certifying deep neural network (DNN) models. There, we draw the static properties from the literature on a particular model and data set. At the second level, experiments are generated that deliver measurements of robustness against certain attacks. We illustrate this by ResNet-18 and MobileNetV3 applied to ImageNet.
Providing Meaningful Data Summarizations Using Examplar-based Clustering in Industry 4.0
May 25, 2021

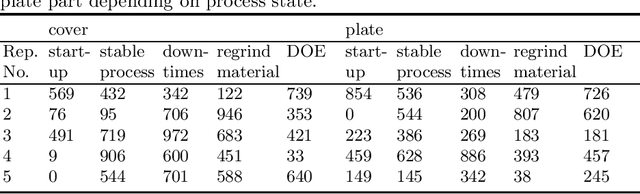
Data summarizations are a valuable tool to derive knowledge from large data streams and have proven their usefulness in a great number of applications. Summaries can be found by optimizing submodular functions. These functions map subsets of data to real values, which indicate their "representativeness" and which should be maximized to find a diverse summary of the underlying data. In this paper, we studied Exemplar-based clustering as a submodular function and provide a GPU algorithm to cope with its high computational complexity. We show, that our GPU implementation provides speedups of up to 72x using single-precision and up to 452x using half-precision computation compared to conventional CPU algorithms. We also show, that the GPU algorithm not only provides remarkable runtime benefits with workstation-grade GPUs but also with low-power embedded computation units for which speedups of up to 35x are possible. Furthermore, we apply our algorithm to real-world data from injection molding manufacturing processes and discuss how found summaries help with steering this specific process to cut costs and reduce the manufacturing of bad parts. Beyond pure speedup considerations, we show, that our approach can provide summaries within reasonable time frames for this kind of industrial, real-world data.
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021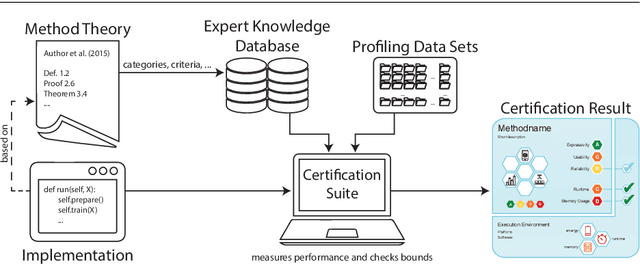
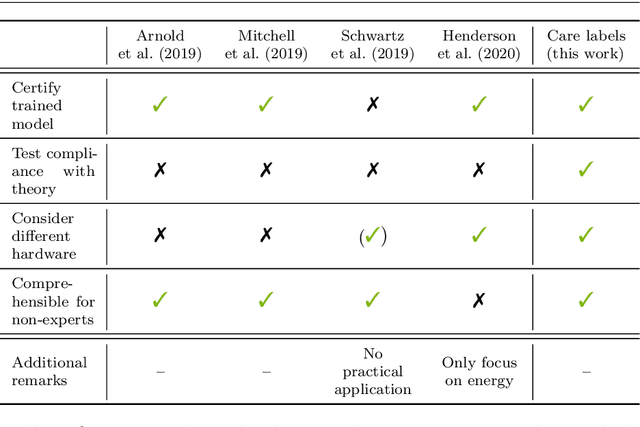
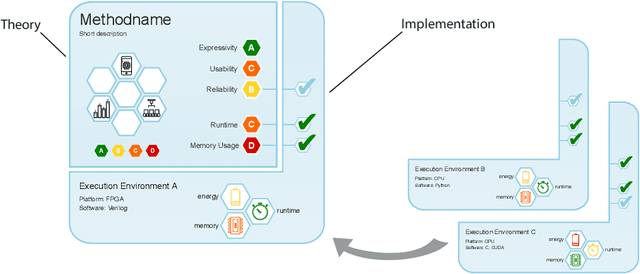
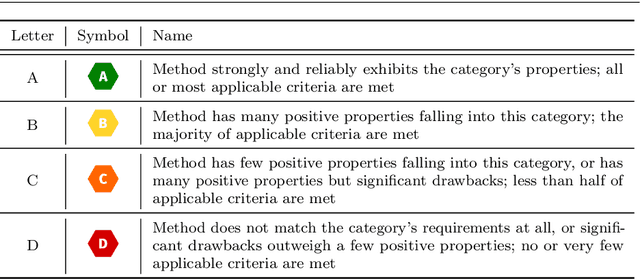
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.