 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProviding Meaningful Data Summarizations Using Examplar-based Clustering in Industry 4.0
May 25, 2021

Data summarizations are a valuable tool to derive knowledge from large data streams and have proven their usefulness in a great number of applications. Summaries can be found by optimizing submodular functions. These functions map subsets of data to real values, which indicate their "representativeness" and which should be maximized to find a diverse summary of the underlying data. In this paper, we studied Exemplar-based clustering as a submodular function and provide a GPU algorithm to cope with its high computational complexity. We show, that our GPU implementation provides speedups of up to 72x using single-precision and up to 452x using half-precision computation compared to conventional CPU algorithms. We also show, that the GPU algorithm not only provides remarkable runtime benefits with workstation-grade GPUs but also with low-power embedded computation units for which speedups of up to 35x are possible. Furthermore, we apply our algorithm to real-world data from injection molding manufacturing processes and discuss how found summaries help with steering this specific process to cut costs and reduce the manufacturing of bad parts. Beyond pure speedup considerations, we show, that our approach can provide summaries within reasonable time frames for this kind of industrial, real-world data.
GPU-Accelerated Optimizer-Aware Evaluation of Submodular Exemplar Clustering
Jan 21, 2021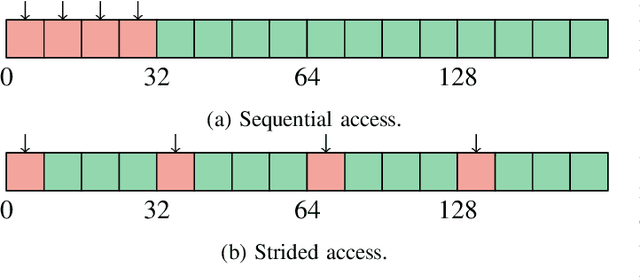
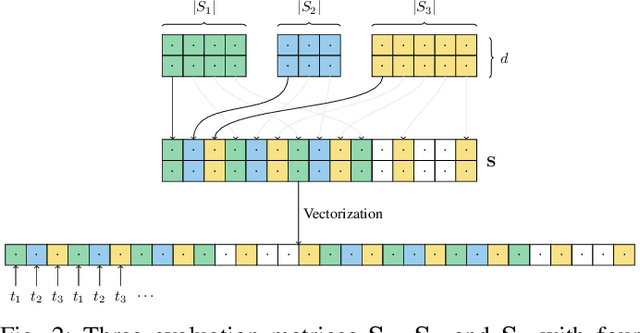
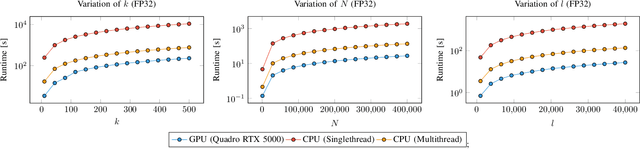

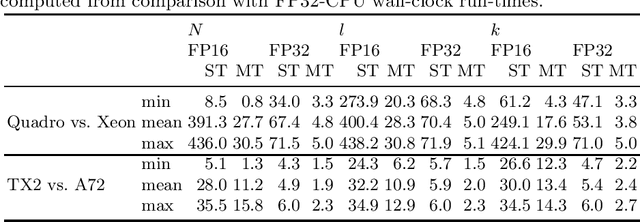
The optimization of submodular functions constitutes a viable way to perform clustering. Strong approximation guarantees and feasible optimization w.r.t. streaming data make this clustering approach favorable. Technically, submodular functions map subsets of data to real values, which indicate how "representative" a specific subset is. Optimal sets might then be used to partition the data space and to infer clusters. Exemplar-based clustering is one of the possible submodular functions, but suffers from high computational complexity. However, for practical applications, the particular real-time or wall-clock run-time is decisive. In this work, we present a novel way to evaluate this particular function on GPUs, which keeps the necessities of optimizers in mind and reduces wall-clock run-time. To discuss our GPU algorithm, we investigated both the impact of different run-time critical problem properties, like data dimensionality and the number of data points in a subset, and the influence of required floating-point precision. In reproducible experiments, our GPU algorithm was able to achieve competitive speedups of up to 72x depending on whether multi-threaded computation on CPUs was used for comparison and the type of floating-point precision required. Half-precision GPU computation led to large speedups of up to 452x compared to single-precision, single-thread CPU computations.
Very Fast Streaming Submodular Function Maximization
Nov 04, 2020


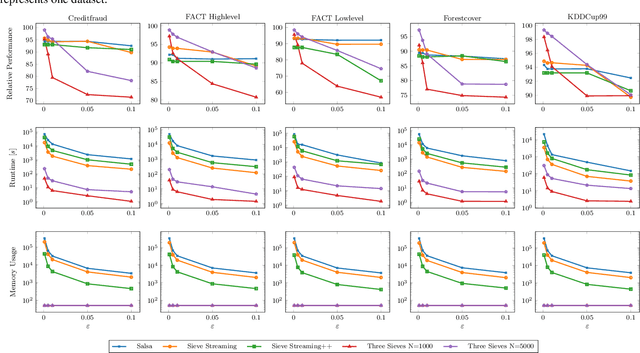
Data summarization has become a valuable tool in understanding even terabytes of data. Due to their compelling theoretical properties, submodular functions have been in the focus of summarization algorithms. These algorithms offer worst-case approximations guarantees to the expense of higher computation and memory requirements. However, many practical applications do not fall under this worst-case, but are usually much more well-behaved. In this paper, we propose a new submodular function maximization algorithm called ThreeSieves, which ignores the worst-case, but delivers a good solution in high probability. It selects the most informative items from a data-stream on the fly and maintains a provable performance on a fixed memory budget. In an extensive evaluation we compare our method against $5$ other methods with over $3895$ hyperparameter configurations. We show that our algorithm outperforms current state-of-the-art algorithms and, at the same time, uses fewer resources. Last, we highlight a real-world use-case of our algorithm for data summarization in gamma-ray astronomy. We make our code publicly available at https://github.com/sbuschjaeger/SubmodularStreamingMaximization