 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Bias in Online Communities through Large-Scale Language Models
Jun 04, 2023Progress in natural language generation research has been shaped by the ever-growing size of language models. While large language models pre-trained on web data can generate human-sounding text, they also reproduce social biases and contribute to the propagation of harmful stereotypes. This work utilises the flaw of bias in language models to explore the biases of six different online communities. In order to get an insight into the communities' viewpoints, we fine-tune GPT-Neo 1.3B with six social media datasets. The bias of the resulting models is evaluated by prompting the models with different demographics and comparing the sentiment and toxicity values of these generations. Together, these methods reveal that bias differs in type and intensity for the various models. This work not only affirms how easily bias is absorbed from training data but also presents a scalable method to identify and compare the bias of different datasets or communities. Additionally, the examples generated for this work demonstrate the limitations of using automated sentiment and toxicity classifiers in bias research.
Explaining Deep Learning Representations by Tracing the Training Process
Sep 13, 2021



We propose a novel explanation method that explains the decisions of a deep neural network by investigating how the intermediate representations at each layer of the deep network were refined during the training process. This way we can a) find the most influential training examples during training and b) analyze which classes attributed most to the final representation. Our method is general: it can be wrapped around any iterative optimization procedure and covers a variety of neural network architectures, including feed-forward networks and convolutional neural networks. We first propose a method for stochastic training with single training instances, but continue to also derive a variant for the common mini-batch training. In experimental evaluations, we show that our method identifies highly representative training instances that can be used as an explanation. Additionally, we propose a visualization that provides explanations in the form of aggregated statistics over the whole training process.
Noisy Labels for Weakly Supervised Gamma Hadron Classification
Aug 30, 2021



Gamma hadron classification, a central machine learning task in gamma ray astronomy, is conventionally tackled with supervised learning. However, the supervised approach requires annotated training data to be produced in sophisticated and costly simulations. We propose to instead solve gamma hadron classification with a noisy label approach that only uses unlabeled data recorded by the real telescope. To this end, we employ the significance of detection as a learning criterion which addresses this form of weak supervision. We show that models which are based on the significance of detection deliver state-of-the-art results, despite being exclusively trained with noisy labels; put differently, our models do not require the costly simulated ground-truth labels that astronomers otherwise employ for classifier training. Our weakly supervised models exhibit competitive performances also on imbalanced data sets that stem from a variety of other application domains. In contrast to existing work on class-conditional label noise, we assume that only one of the class-wise noise rates is known.
Bit Error Tolerance Metrics for Binarized Neural Networks
Feb 02, 2021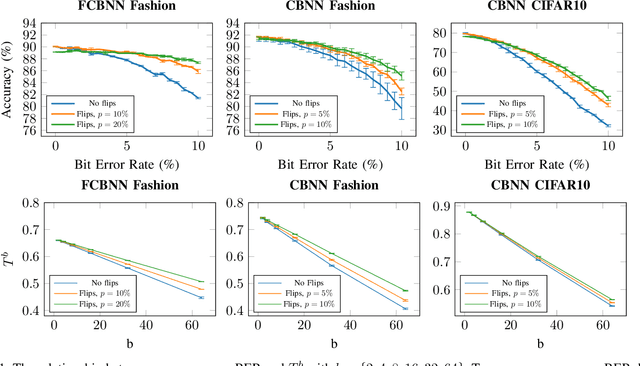
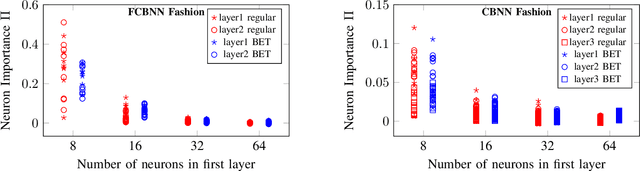

To reduce the resource demand of neural network (NN) inference systems, it has been proposed to use approximate memory, in which the supply voltage and the timing parameters are tuned trading accuracy with energy consumption and performance. Tuning these parameters aggressively leads to bit errors, which can be tolerated by NNs when bit flips are injected during training. However, bit flip training, which is the state of the art for achieving bit error tolerance, does not scale well; it leads to massive overheads and cannot be applied for high bit error rates (BERs). Alternative methods to achieve bit error tolerance in NNs are needed, but the underlying principles behind the bit error tolerance of NNs have not been reported yet. With this lack of understanding, further progress in the research on NN bit error tolerance will be restrained. In this study, our objective is to investigate the internal changes in the NNs that bit flip training causes, with a focus on binarized NNs (BNNs). To this end, we quantify the properties of bit error tolerant BNNs with two metrics. First, we propose a neuron-level bit error tolerance metric, which calculates the margin between the pre-activation values and batch normalization thresholds. Secondly, to capture the effects of bit error tolerance on the interplay of neurons, we propose an inter-neuron bit error tolerance metric, which measures the importance of each neuron and computes the variance over all importance values. Our experimental results support that these two metrics are strongly related to bit error tolerance.
Generalized Negative Correlation Learning for Deep Ensembling
Nov 05, 2020
Ensemble algorithms offer state of the art performance in many machine learning applications. A common explanation for their excellent performance is due to the bias-variance decomposition of the mean squared error which shows that the algorithm's error can be decomposed into its bias and variance. Both quantities are often opposed to each other and ensembles offer an effective way to manage them as they reduce the variance through a diverse set of base learners while keeping the bias low at the same time. Even though there have been numerous works on decomposing other loss functions, the exact mathematical connection is rarely exploited explicitly for ensembling, but merely used as a guiding principle. In this paper, we formulate a generalized bias-variance decomposition for arbitrary twice differentiable loss functions and study it in the context of Deep Learning. We use this decomposition to derive a Generalized Negative Correlation Learning (GNCL) algorithm which offers explicit control over the ensemble's diversity and smoothly interpolates between the two extremes of independent training and the joint training of the ensemble. We show how GNCL encapsulates many previous works and discuss under which circumstances training of an ensemble of Neural Networks might fail and what ensembling method should be favored depending on the choice of the individual networks.
Towards Explainable Bit Error Tolerance of Resistive RAM-Based Binarized Neural Networks
Feb 03, 2020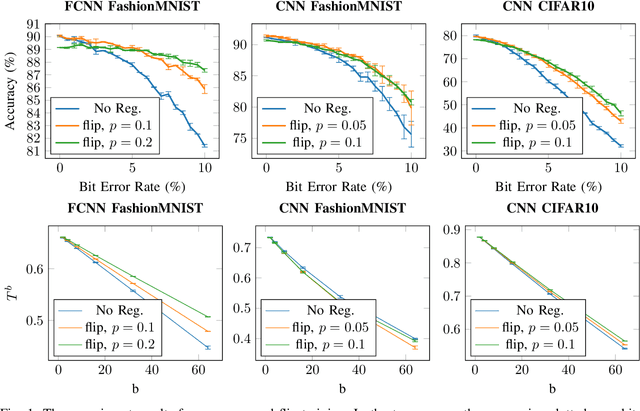
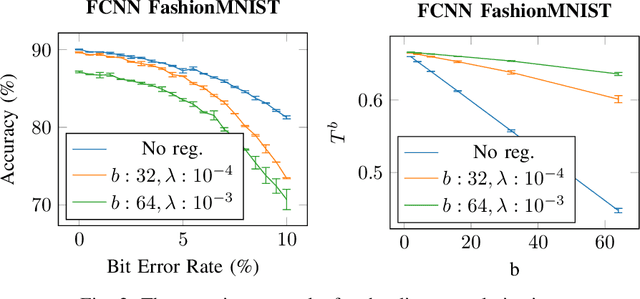

Non-volatile memory, such as resistive RAM (RRAM), is an emerging energy-efficient storage, especially for low-power machine learning models on the edge. It is reported, however, that the bit error rate of RRAMs can be up to 3.3% in the ultra low-power setting, which might be crucial for many use cases. Binary neural networks (BNNs), a resource efficient variant of neural networks (NNs), can tolerate a certain percentage of errors without a loss in accuracy and demand lower resources in computation and storage. The bit error tolerance (BET) in BNNs can be achieved by flipping the weight signs during training, as proposed by Hirtzlin et al., but their method has a significant drawback, especially for fully connected neural networks (FCNN): The FCNNs overfit to the error rate used in training, which leads to low accuracy under lower error rates. In addition, the underlying principles of BET are not investigated. In this work, we improve the training for BET of BNNs and aim to explain this property. We propose straight-through gradient approximation to improve the weight-sign-flip training, by which BNNs adapt less to the bit error rates. To explain the achieved robustness, we define a metric that aims to measure BET without fault injection. We evaluate the metric and find that it correlates with accuracy over error rate for all FCNNs tested. Finally, we explore the influence of a novel regularizer that optimizes with respect to this metric, with the aim of providing a configurable trade-off in accuracy and BET.