 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMPDiff: Temporal Mixed-Precision for Diffusion Models
Mar 14, 2026Diffusion models are the go-to method for Text-to-Image generation, but their iterative denoising processes has high inference latency. Quantization reduces compute time by using lower bitwidths, but applies a fixed precision across all denoising timesteps, leaving an entire optimization axis unexplored. We propose TMPDiff, a temporal mixed-precision framework for diffusion models that assigns different numeric precision to different denoising timesteps. We hypothesize that quantization errors accumulate additively across timesteps, which we then validate experimentally. Based on our observations, we develop an adaptive bisectioning-based algorithm, which assigns per-step precisions with linear evaluation complexity, reducing an otherwise exponential search problem. Across four state-of-the-art diffusion models and three datasets, TMPDiff consistently outperforms uniform-precision baselines at matched speedup, achieving 10 to 20% improvement in perceptual quality. On FLUX.1-dev, TMPDiff achieves 90% SSIM relative to the full-precision model at a speedup of 2.5x over 16-bit inference.
Jump Like A Squirrel: Optimized Execution Step Order for Anytime Random Forest Inference
Mar 02, 2026Due to their efficiency and small size, decision trees and random forests are popular machine learning models used for classification on resource-constrained systems. In such systems, the available execution time for inference in a random forest might not be sufficient for a complete model execution. Ideally, the already gained prediction confidence should be retained. An anytime algorithm is designed to be able to be aborted anytime, while giving a result with an increasing quality over time. Previous approaches have realized random forests as anytime algorithms on the granularity of trees, stopping after some but not all trees of a forest have been executed. However, due to the way decision trees subdivide the sample space in every step, an increase in prediction quality is achieved with every additional step in one tree. In this paper, we realize decision trees and random forest as anytime algorithms on the granularity of single steps in trees. This approach opens a design space to define the step order in a forest, which has the potential to optimize the mean accuracy. We propose the Optimal Order, which finds a step order with a maximal mean accuracy in exponential runtime and the polynomial runtime heuristics Forward Squirrel Order and Backward Squirrel Order, which greedily maximize the accuracy for each additional step taken down and up the trees, respectively. Our evaluation shows, that the Backward Squirrel Order performs $\sim94\%$ as well as the Optimal Order and $\sim99\%$ as well as all other step orders.
CertMask: Certifiable Defense Against Adversarial Patches via Theoretically Optimal Mask Coverage
Nov 13, 2025Adversarial patch attacks inject localized perturbations into images to mislead deep vision models. These attacks can be physically deployed, posing serious risks to real-world applications. In this paper, we propose CertMask, a certifiably robust defense that constructs a provably sufficient set of binary masks to neutralize patch effects with strong theoretical guarantees. While the state-of-the-art approach (PatchCleanser) requires two rounds of masking and incurs $O(n^2)$ inference cost, CertMask performs only a single round of masking with $O(n)$ time complexity, where $n$ is the cardinality of the mask set to cover an input image. Our proposed mask set is computed using a mathematically rigorous coverage strategy that ensures each possible patch location is covered at least $k$ times, providing both efficiency and robustness. We offer a theoretical analysis of the coverage condition and prove its sufficiency for certification. Experiments on ImageNet, ImageNette, and CIFAR-10 show that CertMask improves certified robust accuracy by up to +13.4\% over PatchCleanser, while maintaining clean accuracy nearly identical to the vanilla model.
WCDT: Systematic WCET Optimization for Decision Tree Implementations
Jan 29, 2025



Machine-learning models are increasingly deployed on resource-constrained embedded systems with strict timing constraints. In such scenarios, the worst-case execution time (WCET) of the models is required to ensure safe operation. Specifically, decision trees are a prominent class of machine-learning models and the main building blocks of tree-based ensemble models (e.g., random forests), which are commonly employed in resource-constrained embedded systems. In this paper, we develop a systematic approach for WCET optimization of decision tree implementations. To this end, we introduce a linear surrogate model that estimates the execution time of individual paths through a decision tree based on the path's length and the number of taken branches. We provide an optimization algorithm that constructively builds a WCET-optimal implementation of a given decision tree with respect to this surrogate model. We experimentally evaluate both the surrogate model and the WCET-optimization algorithm. The evaluation shows that the optimization algorithm improves analytically determined WCET by up to $17\%$ compared to an unoptimized implementation.
Language-specific Calibration for Pruning Multilingual Language Models
Aug 26, 2024Recent advances in large language model (LLM) pruning have shown state-of-the-art compression results in post-training and retraining-free settings while maintaining high predictive performance. However, such research mainly considers calibrating pruning using English text, despite the multilingual nature of modern LLMs and their frequent uses in non-English languages. In this paper, we set out to explore effective strategies for calibrating the pruning of multilingual language models. We present the first comprehensive empirical study, comparing different calibration languages for pruning multilingual models across diverse tasks, models, and state-of-the-art pruning techniques. Our results present practical suggestions, for example, calibrating in the target language can efficiently yield lower perplexity, but does not necessarily benefit downstream tasks. Our further analysis experiments unveil that calibration in the target language mainly contributes to preserving language-specific features related to fluency and coherence, but might not contribute to capturing language-agnostic features such as language understanding and reasoning. Last, we provide practical recommendations for future practitioners.
Bridging the Gap between ROS~2 and Classical Real-Time Scheduling for Periodic Tasks
Aug 07, 2024The Robot Operating System 2 (ROS~2) is a widely used middleware that provides software libraries and tools for developing robotic systems. In these systems, tasks are scheduled by ROS~2 executors. Since the scheduling behavior of the default ROS~2 executor is inherently different from classical real-time scheduling theory, dedicated analyses or alternative executors, requiring substantial changes to ROS~2, have been required. In 2023, the events executor, which features an events queue and allows the possibility to make scheduling decisions immediately after a job completes, was introduced into ROS~2. In this paper, we show that, with only minor modifications of the events executor, a large body of research results from classical real-time scheduling theory becomes applicable. Hence, this enables analytical bounds on the worst-case response time and the end-to-end latency, outperforming bounds for the default ROS 2 executor in many scenarios. Our solution is easy to integrate into existing ROS 2 systems since it requires only minor backend modifications of the events executor, which is natively included in ROS 2. The evaluation results show that our ROS~2 events executor with minor modifications can have significant improvement in terms of dropped jobs, worst-case response time, end-to-end latency, and performance compared to the default ROS~2 executor.
TREE: Tree Regularization for Efficient Execution
Jun 18, 2024
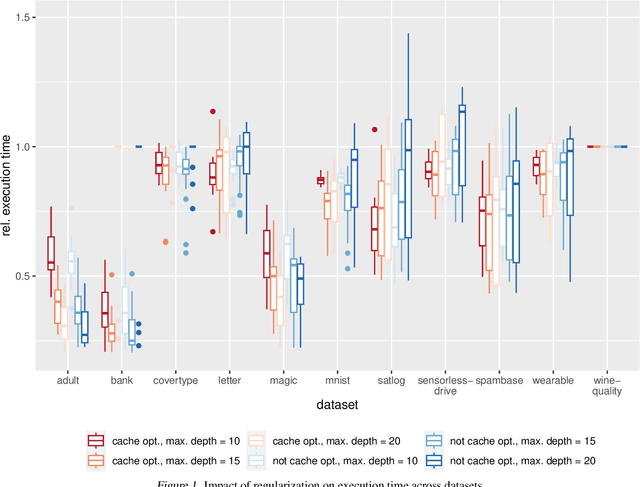
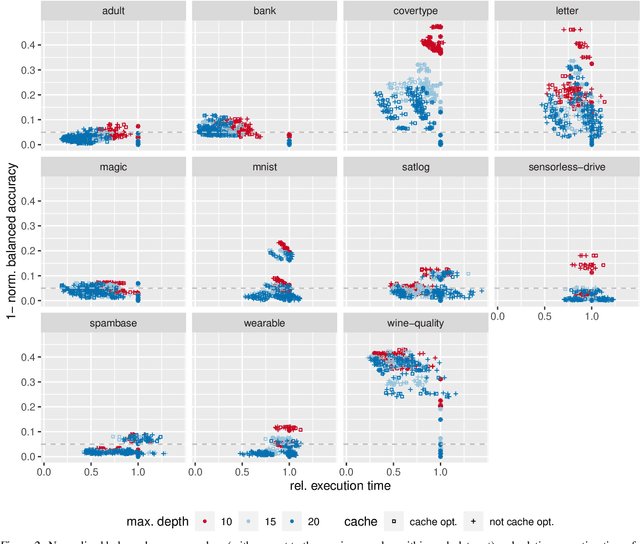

The rise of machine learning methods on heavily resource constrained devices requires not only the choice of a suitable model architecture for the target platform, but also the optimization of the chosen model with regard to execution time consumption for inference in order to optimally utilize the available resources. Random forests and decision trees are shown to be a suitable model for such a scenario, since they are not only heavily tunable towards the total model size, but also offer a high potential for optimizing their executions according to the underlying memory architecture. In addition to the straightforward strategy of enforcing shorter paths through decision trees and hence reducing the execution time for inference, hardware-aware implementations can optimize the execution time in an orthogonal manner. One particular hardware-aware optimization is to layout the memory of decision trees in such a way, that higher probably paths are less likely to be evicted from system caches. This works particularly well when splits within tree nodes are uneven and have a high probability to visit one of the child nodes. In this paper, we present a method to reduce path lengths by rewarding uneven probability distributions during the training of decision trees at the cost of a minimal accuracy degradation. Specifically, we regularize the impurity computation of the CART algorithm in order to favor not only low impurity, but also highly asymmetric distributions for the evaluation of split criteria and hence offer a high optimization potential for a memory architecture-aware implementation. We show that especially for binary classification data sets and data sets with many samples, this form of regularization can lead to an reduction of up to approximately four times in the execution time with a minimal accuracy degradation.
Register Your Forests: Decision Tree Ensemble Optimization by Explicit CPU Register Allocation
Apr 10, 2024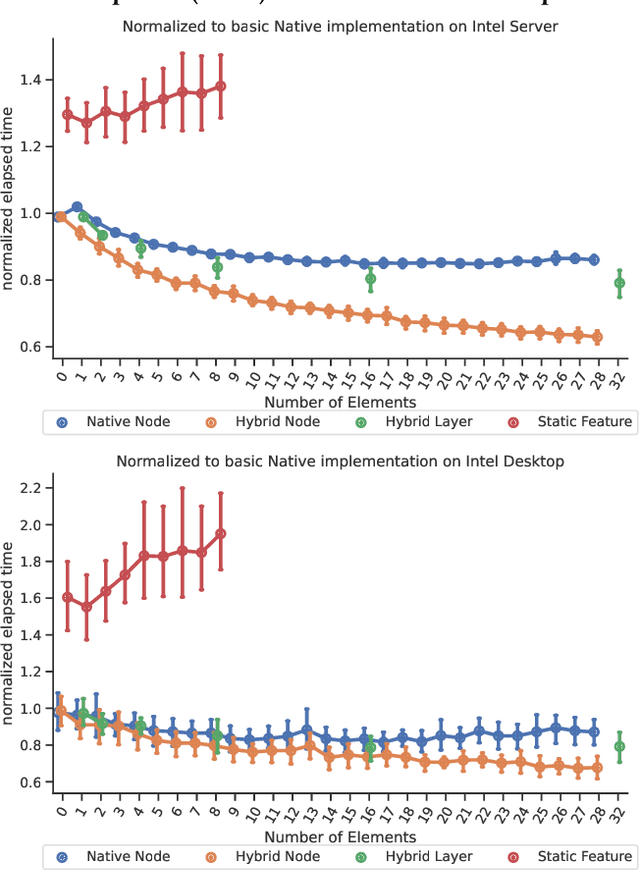

Bringing high-level machine learning models to efficient and well-suited machine implementations often invokes a bunch of tools, e.g.~code generators, compilers, and optimizers. Along such tool chains, abstractions have to be applied. This leads to not optimally used CPU registers. This is a shortcoming, especially in resource constrained embedded setups. In this work, we present a code generation approach for decision tree ensembles, which produces machine assembly code within a single conversion step directly from the high-level model representation. Specifically, we develop various approaches to effectively allocate registers for the inference of decision tree ensembles. Extensive evaluations of the proposed method are conducted in comparison to the basic realization of C code from the high-level machine learning model and succeeding compilation. The results show that the performance of decision tree ensemble inference can be significantly improved (by up to $\approx1.6\times$), if the methods are applied carefully to the appropriate scenario.
FLInt: Exploiting Floating Point Enabled Integer Arithmetic for Efficient Random Forest Inference
Sep 09, 2022
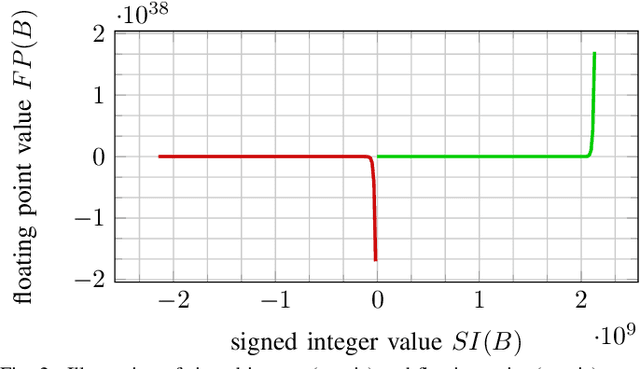
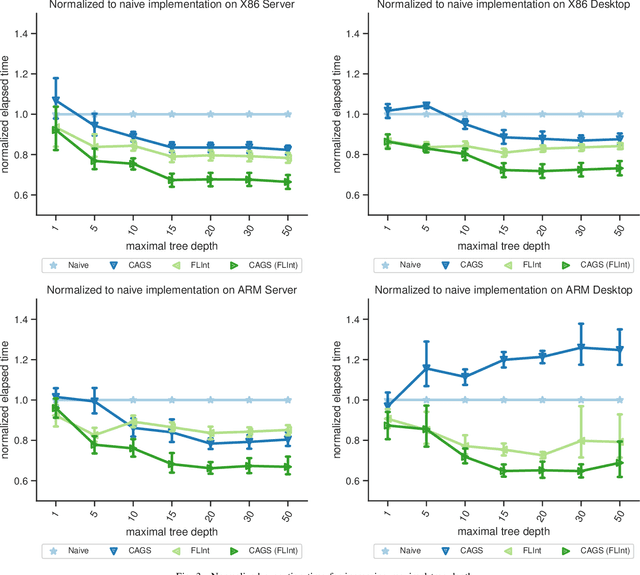
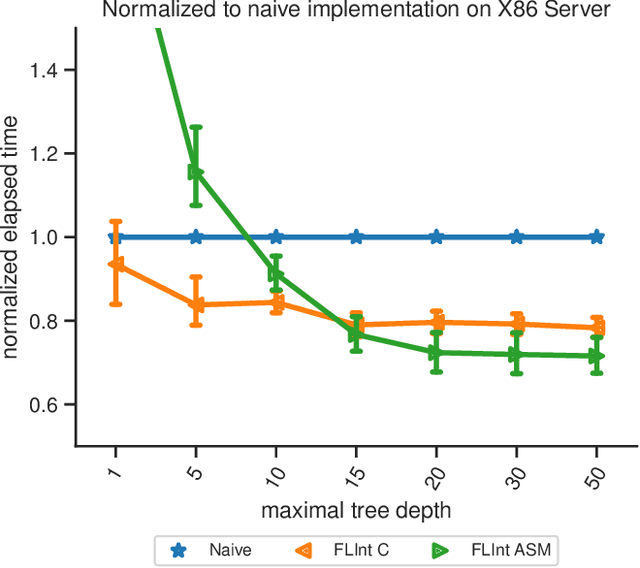
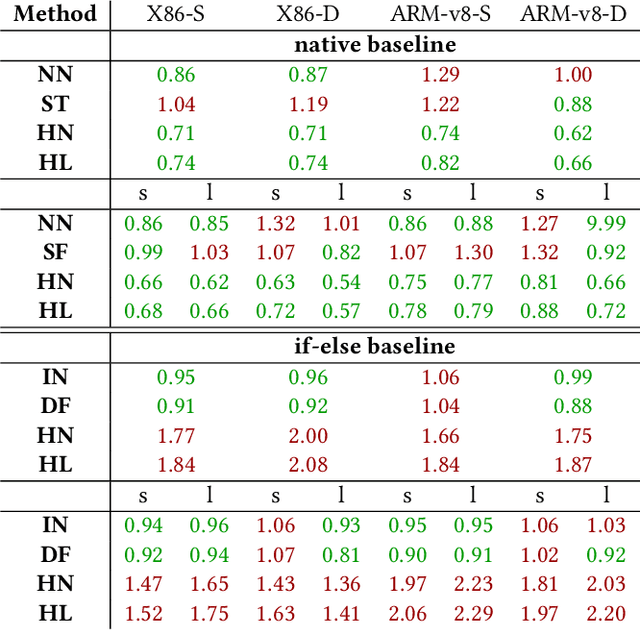
In many machine learning applications, e.g., tree-based ensembles, floating point numbers are extensively utilized due to their expressiveness. Nowadays performing data analysis on embedded devices from dynamic data masses becomes available, but such systems often lack hardware capabilities to process floating point numbers, introducing large overheads for their processing. Even if such hardware is present in general computing systems, using integer operations instead of floating point operations promises to reduce operation overheads and improve the performance. In this paper, we provide \mdname, a full precision floating point comparison for random forests, by only using integer and logic operations. To ensure the same functionality preserves, we formally prove the correctness of this comparison. Since random forests only require comparison of floating point numbers during inference, we implement \mdname~in low level realizations and therefore eliminate the need for floating point hardware entirely, by keeping the model accuracy unchanged. The usage of \mdname~basically boils down to a one-by-one replacement of conditions: For instance, a comparison statement in C: if(pX[3]<=(float)10.074347) becomes if((*(((int*)(pX))+3))<=((int)(0x41213087))). Experimental evaluation on X86 and ARMv8 desktop and server class systems shows that the execution time can be reduced by up to $\approx 30\%$ with our novel approach.
AuNa: Modularly Integrated Simulation Framework for Cooperative Autonomous Navigation
Jul 12, 2022
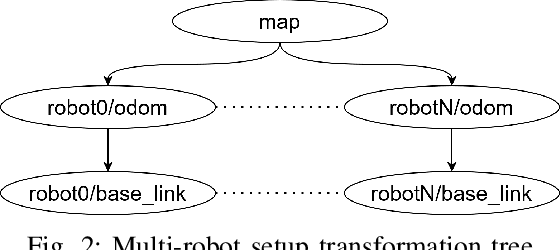


In the near future, the development of autonomous driving will get more complex as the vehicles will not only rely on their own sensors but also communicate with other vehicles and the infrastructure to cooperate and improve the driving experience. Towards this, several research areas, such as robotics, communication, and control, are required to collaborate in order to implement future-ready methods. However, each area focuses on the development of its own components first, while the effects the components may have on the whole system are only considered at a later stage. In this work, we integrate the simulation tools of robotics, communication and control namely ROS2, OMNeT++, and MATLAB to evaluate cooperative driving scenarios. The framework can be utilized to develop the individual components using the designated tools, while the final evaluation can be conducted in a complete scenario, enabling the simulation of advanced multi-robot applications for cooperative driving. Furthermore, it can be used to integrate additional tools, as the integration is done in a modular way. We showcase the framework by demonstrating a platooning scenario under cooperative adaptive cruise control (CACC) and the ETSI ITS-G5 communication architecture. Additionally, we compare the differences of the controller performance between the theoretical analysis and practical case study.