 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Guide to Estimating Conditional Average Treatment Effects in Competing Risks Settings
Jun 08, 2026Conditional average treatment effects (CATEs) are central to treatment decision-making in personalized medicine. In competing risks settings, estimating CATEs from survival data allows for patient-specific assessments of treatment effectiveness for a specific event of interest while properly accounting for alternative event types. This distinction is essential in the presence of comorbidities, where competing causes of death may otherwise confound the therapeutic benefit. Focusing on right-censored survival times with binary treatment, we examine CATEs defined as covariate-conditional differences in the absolute risk for the event of interest at a fixed time. To this end, we study meta-learners which adapt machine learning algorithms for CATE estimation in competing risks scenarios. We systematically compare six meta-learners, combining Cox regression or random survival forests for risk modeling with elastic net regression or random forests for direct CATE modeling. To provide practical guidance on model selection, we evaluate their performance in multiple simulation settings, that differ in hazard complexity, treatment heterogeneity, treatment assignment, event type distribution and censoring. To facilitate applied use, we provide the R package, crsurvlearners, which implements all considered approaches.
Choosing a Model, Shaping a Future: Comparing LLM Perspectives on Sustainability and its Relationship with AI
May 20, 2025As organizations increasingly rely on AI systems for decision support in sustainability contexts, it becomes critical to understand the inherent biases and perspectives embedded in Large Language Models (LLMs). This study systematically investigates how five state-of-the-art LLMs -- Claude, DeepSeek, GPT, LLaMA, and Mistral - conceptualize sustainability and its relationship with AI. We administered validated, psychometric sustainability-related questionnaires - each 100 times per model -- to capture response patterns and variability. Our findings revealed significant inter-model differences: For example, GPT exhibited skepticism about the compatibility of AI and sustainability, whereas LLaMA demonstrated extreme techno-optimism with perfect scores for several Sustainable Development Goals (SDGs). Models also diverged in attributing institutional responsibility for AI and sustainability integration, a results that holds implications for technology governance approaches. Our results demonstrate that model selection could substantially influence organizational sustainability strategies, highlighting the need for awareness of model-specific biases when deploying LLMs for sustainability-related decision-making.
A Cautionary Tale About "Neutrally" Informative AI Tools Ahead of the 2025 Federal Elections in Germany
Feb 21, 2025In this study, we examine the reliability of AI-based Voting Advice Applications (VAAs) and large language models (LLMs) in providing objective political information. Our analysis is based upon a comparison with party responses to 38 statements of the Wahl-O-Mat, a well-established German online tool that helps inform voters by comparing their views with political party positions. For the LLMs, we identify significant biases. They exhibit a strong alignment (over 75% on average) with left-wing parties and a substantially lower alignment with center-right (smaller 50%) and right-wing parties (around 30%). Furthermore, for the VAAs, intended to objectively inform voters, we found substantial deviations from the parties' stated positions in Wahl-O-Mat: While one VAA deviated in 25% of cases, another VAA showed deviations in more than 50% of cases. For the latter, we even observed that simple prompt injections led to severe hallucinations, including false claims such as non-existent connections between political parties and right-wing extremist ties.
Which Imputation Fits Which Feature Selection Method? A Survey-Based Simulation Study
Dec 18, 2024



Tree-based learning methods such as Random Forest and XGBoost are still the gold-standard prediction methods for tabular data. Feature importance measures are usually considered for feature selection as well as to assess the effect of features on the outcome variables in the model. This also applies to survey data, which are frequently encountered in the social sciences and official statistics. These types of datasets often present the challenge of missing values. The typical solution is to impute the missing data before applying the learning method. However, given the large number of possible imputation methods available, the question arises as to which should be chosen to achieve the 'best' reflection of feature importance and feature selection in subsequent analyses. In the present paper, we investigate this question in a survey-based simulation study for eight state-of-the art imputation methods and three learners. The imputation methods comprise listwise deletion, three MICE options, four \texttt{missRanger} options as well as the recently proposed mixGBoost imputation approach. As learners, we consider the two most common tree-based methods, Random Forest and XGBoost, and an interpretable linear model with regularization.
A Central Limit Theorem for the permutation importance measure
Dec 17, 2024Random Forests have become a widely used tool in machine learning since their introduction in 2001, known for their strong performance in classification and regression tasks. One key feature of Random Forests is the Random Forest Permutation Importance Measure (RFPIM), an internal, non-parametric measure of variable importance. While widely used, theoretical work on RFPIM is sparse, and most research has focused on empirical findings. However, recent progress has been made, such as establishing consistency of the RFPIM, although a mathematical analysis of its asymptotic distribution is still missing. In this paper, we provide a formal proof of a Central Limit Theorem for RFPIM using U-Statistics theory. Our approach deviates from the conventional Random Forest model by assuming a random number of trees and imposing conditions on the regression functions and error terms, which must be bounded and additive, respectively. Our result aims at improving the theoretical understanding of RFPIM rather than conducting comprehensive hypothesis testing. However, our contributions provide a solid foundation and demonstrate the potential for future work to extend to practical applications which we also highlight with a small simulation study.
Is GPT-4 Less Politically Biased than GPT-3.5? A Renewed Investigation of ChatGPT's Political Biases
Oct 28, 2024



This work investigates the political biases and personality traits of ChatGPT, specifically comparing GPT-3.5 to GPT-4. In addition, the ability of the models to emulate political viewpoints (e.g., liberal or conservative positions) is analyzed. The Political Compass Test and the Big Five Personality Test were employed 100 times for each scenario, providing statistically significant results and an insight into the results correlations. The responses were analyzed by computing averages, standard deviations, and performing significance tests to investigate differences between GPT-3.5 and GPT-4. Correlations were found for traits that have been shown to be interdependent in human studies. Both models showed a progressive and libertarian political bias, with GPT-4's biases being slightly, but negligibly, less pronounced. Specifically, on the Political Compass, GPT-3.5 scored -6.59 on the economic axis and -6.07 on the social axis, whereas GPT-4 scored -5.40 and -4.73. In contrast to GPT-3.5, GPT-4 showed a remarkable capacity to emulate assigned political viewpoints, accurately reflecting the assigned quadrant (libertarian-left, libertarian-right, authoritarian-left, authoritarian-right) in all four tested instances. On the Big Five Personality Test, GPT-3.5 showed highly pronounced Openness and Agreeableness traits (O: 85.9%, A: 84.6%). Such pronounced traits correlate with libertarian views in human studies. While GPT-4 overall exhibited less pronounced Big Five personality traits, it did show a notably higher Neuroticism score. Assigned political orientations influenced Openness, Agreeableness, and Conscientiousness, again reflecting interdependencies observed in human studies. Finally, we observed that test sequencing affected ChatGPT's responses and the observed correlations, indicating a form of contextual memory.
AR-Sieve Bootstrap for the Random Forest and a simulation-based comparison with rangerts time series prediction
Oct 01, 2024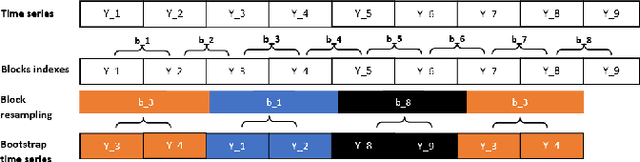
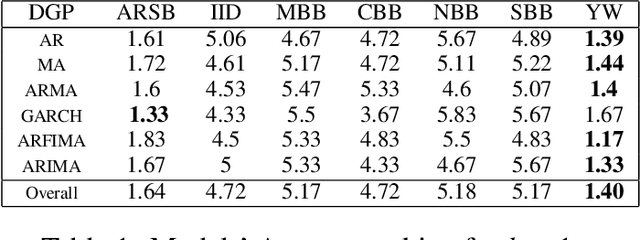
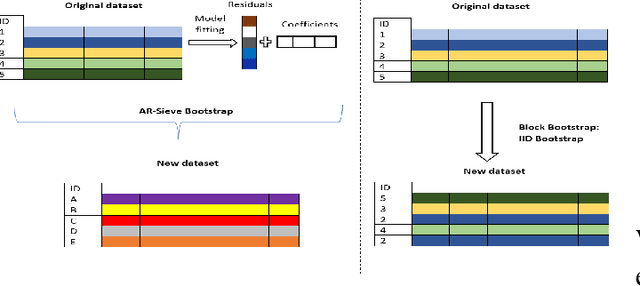
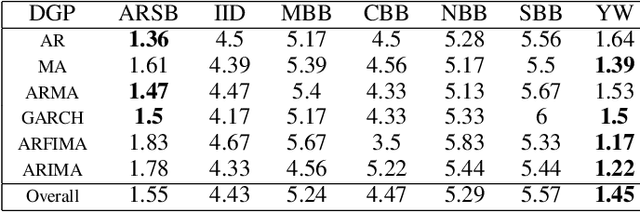
The Random Forest (RF) algorithm can be applied to a broad spectrum of problems, including time series prediction. However, neither the classical IID (Independent and Identically distributed) bootstrap nor block bootstrapping strategies (as implemented in rangerts) completely account for the nature of the Data Generating Process (DGP) while resampling the observations. We propose the combination of RF with a residual bootstrapping technique where we replace the IID bootstrap with the AR-Sieve Bootstrap (ARSB), which assumes the DGP to be an autoregressive process. To assess the new model's predictive performance, we conduct a simulation study using synthetic data generated from different types of DGPs. It turns out that ARSB provides more variation amongst the trees in the forest. Moreover, RF with ARSB shows greater accuracy compared to RF with other bootstrap strategies. However, these improvements are achieved at some efficiency costs.
TREE: Tree Regularization for Efficient Execution
Jun 18, 2024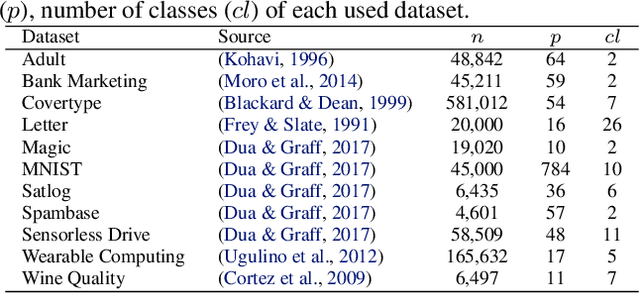
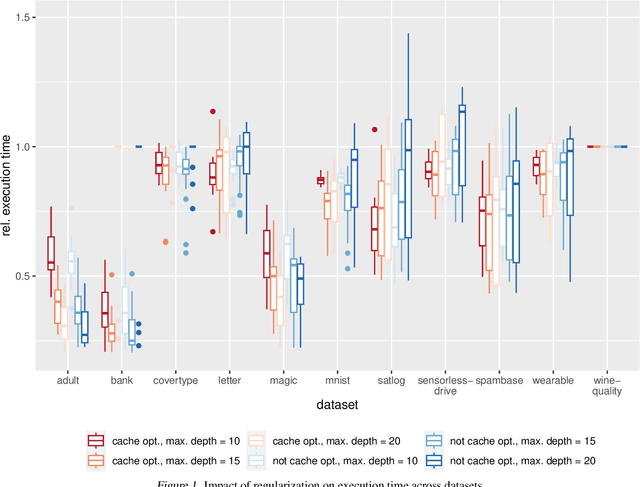
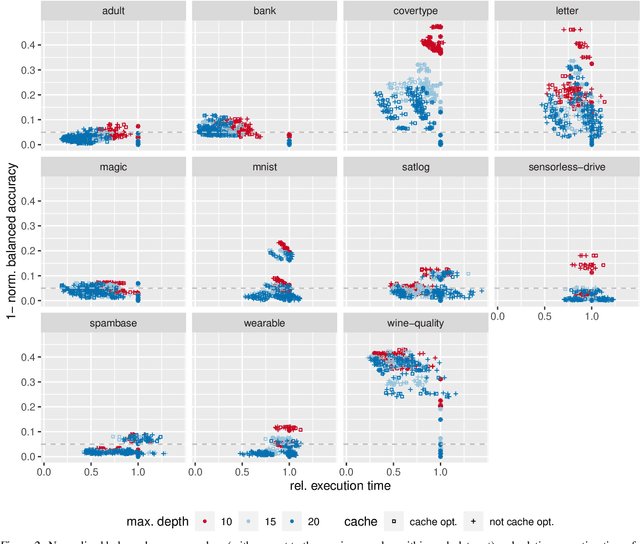

The rise of machine learning methods on heavily resource constrained devices requires not only the choice of a suitable model architecture for the target platform, but also the optimization of the chosen model with regard to execution time consumption for inference in order to optimally utilize the available resources. Random forests and decision trees are shown to be a suitable model for such a scenario, since they are not only heavily tunable towards the total model size, but also offer a high potential for optimizing their executions according to the underlying memory architecture. In addition to the straightforward strategy of enforcing shorter paths through decision trees and hence reducing the execution time for inference, hardware-aware implementations can optimize the execution time in an orthogonal manner. One particular hardware-aware optimization is to layout the memory of decision trees in such a way, that higher probably paths are less likely to be evicted from system caches. This works particularly well when splits within tree nodes are uneven and have a high probability to visit one of the child nodes. In this paper, we present a method to reduce path lengths by rewarding uneven probability distributions during the training of decision trees at the cost of a minimal accuracy degradation. Specifically, we regularize the impurity computation of the CART algorithm in order to favor not only low impurity, but also highly asymmetric distributions for the evaluation of split criteria and hence offer a high optimization potential for a memory architecture-aware implementation. We show that especially for binary classification data sets and data sets with many samples, this form of regularization can lead to an reduction of up to approximately four times in the execution time with a minimal accuracy degradation.
Behind the Screen: Investigating ChatGPT's Dark Personality Traits and Conspiracy Beliefs
Feb 06, 2024ChatGPT is notorious for its intransparent behavior. This paper tries to shed light on this, providing an in-depth analysis of the dark personality traits and conspiracy beliefs of GPT-3.5 and GPT-4. Different psychological tests and questionnaires were employed, including the Dark Factor Test, the Mach-IV Scale, the Generic Conspiracy Belief Scale, and the Conspiracy Mentality Scale. The responses were analyzed computing average scores, standard deviations, and significance tests to investigate differences between GPT-3.5 and GPT-4. For traits that have shown to be interdependent in human studies, correlations were considered. Additionally, system roles corresponding to groups that have shown distinct answering behavior in the corresponding questionnaires were applied to examine the models' ability to reflect characteristics associated with these roles in their responses. Dark personality traits and conspiracy beliefs were not particularly pronounced in either model with little differences between GPT-3.5 and GPT-4. However, GPT-4 showed a pronounced tendency to believe in information withholding. This is particularly intriguing given that GPT-4 is trained on a significantly larger dataset than GPT-3.5. Apparently, in this case an increased data exposure correlates with a greater belief in the control of information. An assignment of extreme political affiliations increased the belief in conspiracy theories. Test sequencing affected the models' responses and the observed correlations, indicating a form of contextual memory.
Evaluating tree-based imputation methods as an alternative to MICE PMM for drawing inference in empirical studies
Jan 17, 2024Dealing with missing data is an important problem in statistical analysis that is often addressed with imputation procedures. The performance and validity of such methods are of great importance for their application in empirical studies. While the prevailing method of Multiple Imputation by Chained Equations (MICE) with Predictive Mean Matching (PMM) is considered standard in the social science literature, the increase in complex datasets may require more advanced approaches based on machine learning. In particular, tree-based imputation methods have emerged as very competitive approaches. However, the performance and validity are not completely understood, particularly compared to the standard MICE PMM. This is especially true for inference in linear models. In this study, we investigate the impact of various imputation methods on coefficient estimation, Type I error, and power, to gain insights that can help empirical researchers deal with missingness more effectively. We explore MICE PMM alongside different tree-based methods, such as MICE with Random Forest (RF), Chained Random Forests with and without PMM (missRanger), and Extreme Gradient Boosting (MIXGBoost), conducting a realistic simulation study using the German National Educational Panel Study (NEPS) as the original data source. Our results reveal that Random Forest-based imputations, especially MICE RF and missRanger with PMM, consistently perform better in most scenarios. Standard MICE PMM shows partially increased bias and overly conservative test decisions, particularly with non-true zero coefficients. Our results thus underscore the potential advantages of tree-based imputation methods, albeit with a caveat that all methods perform worse with an increased missingness, particularly missRanger.