 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRangeAD: Fast On-Model Anomaly Detection
Mar 18, 2026In practice, machine learning methods commonly require anomaly detection (AD) to filter inputs or detect distributional shifts. Typically, this is implemented by running a separate AD model alongside the primary model. However, this separation ignores the fact that the primary model already encodes substantial information about the target distribution. In this paper, we introduce On-Model AD, a setting for anomaly detection that explicitly leverages access to a related machine learning model. Within this setting, we propose RangeAD, an algorithm that utilizes neuron-wise output ranges derived from the primary model. RangeAD achieves superior performance even on high-dimensional tasks while incurring substantially lower inference costs. Our results demonstrate the potential of the On-Model AD setting as a practical framework for efficient anomaly detection.
Unsupervised Symbolic Anomaly Detection
Mar 18, 2026We propose SYRAN, an unsupervised anomaly detection method based on symbolic regression. Instead of encoding normal patterns in an opaque, high-dimensional model, our method learns an ensemble of human-readable equations that describe symbolic invariants: functions that are approximately constant on normal data. Deviations from these invariants yield anomaly scores, so that the detection logic is interpretable by construction, rather than via post-hoc explanation. Experimental results demonstrate that SYRAN is highly interpretable, providing equations that correspond to known scientific or medical relationships, and maintains strong anomaly detection performance comparable to that of state-of-the-art methods.
FoMo X: Modular Explainability Signals for Outlier Detection Foundation Models
Mar 18, 2026Tabular foundation models, specifically Prior-Data Fitted Networks (PFNs), have revolutionized outlier detection (OD) by enabling unsupervised zero-shot adaptation to new datasets without training. However, despite their predictive power, these models typically function as opaque black boxes, outputting scalar outlier scores that lack the operational context required for safety-critical decision-making. Existing post-hoc explanation methods are often computationally prohibitive for real-time deployment or fail to capture the epistemic uncertainty inherent in zero-shot inference. In this work, we introduce FoMo-X, a modular framework that equips OD foundation models with intrinsic, lightweight diagnostic capabilities. We leverage the insight that the frozen embeddings of a pretrained PFN backbone already encode rich, context-conditioned relational information. FoMo-X attaches auxiliary diagnostic heads to these embeddings, trained offline using the same generative simulator prior as the backbone. This allows us to distill computationally expensive properties, such as Monte Carlo dropout based epistemic uncertainty, into a deterministic, single-pass inference. We instantiate FoMo-X with two novel heads: a Severity Head that discretizes deviations into interpretable risk tiers, and an Uncertainty Head that provides calibrated confidence measures. Extensive evaluation on synthetic and real-world benchmarks (ADBench) demonstrates that FoMo-X recovers ground-truth diagnostic signals with high fidelity and negligible inference overhead. By bridging the gap between foundation model performance and operational explainability, FoMo-X offers a scalable path toward trustworthy, zero-shot outlier detection.
Towards Foundation Models for Consensus Rank Aggregation
Mar 16, 2026Aggregating a consensus ranking from multiple input rankings is a fundamental problem with applications in recommendation systems, search engines, job recruitment, and elections. Despite decades of research in consensus ranking aggregation, minimizing the Kemeny distance remains computationally intractable. Specifically, determining an optimal aggregation of rankings with respect to the Kemeny distance is an NP-hard problem, limiting its practical application to relatively small-scale instances. We propose the Kemeny Transformer, a novel Transformer-based algorithm trained via reinforcement learning to efficiently approximate the Kemeny optimal ranking. Experimental results demonstrate that our model outperforms classical majority-heuristic and Markov-chain approaches, achieving substantially faster inference than integer linear programming solvers. Our approach thus offers a practical, scalable alternative for real-world ranking-aggregation tasks.
On Uniformly Scaling Flows: A Density-Aligned Approach to Deep One-Class Classification
Oct 10, 2025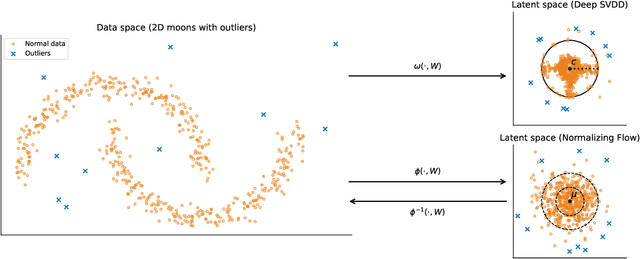
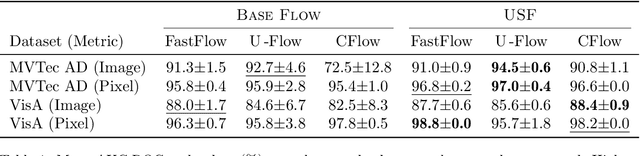
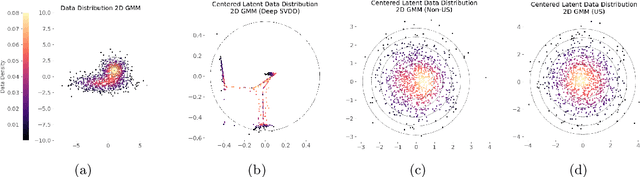
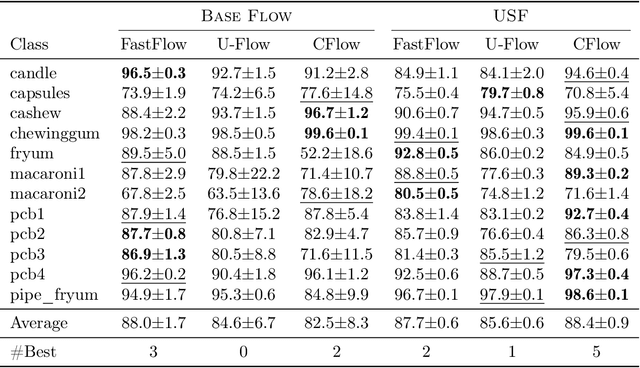
Unsupervised anomaly detection is often framed around two widely studied paradigms. Deep one-class classification, exemplified by Deep SVDD, learns compact latent representations of normality, while density estimators realized by normalizing flows directly model the likelihood of nominal data. In this work, we show that uniformly scaling flows (USFs), normalizing flows with a constant Jacobian determinant, precisely connect these approaches. Specifically, we prove how training a USF via maximum-likelihood reduces to a Deep SVDD objective with a unique regularization that inherently prevents representational collapse. This theoretical bridge implies that USFs inherit both the density faithfulness of flows and the distance-based reasoning of one-class methods. We further demonstrate that USFs induce a tighter alignment between negative log-likelihood and latent norm than either Deep SVDD or non-USFs, and how recent hybrid approaches combining one-class objectives with VAEs can be naturally extended to USFs. Consequently, we advocate using USFs as a drop-in replacement for non-USFs in modern anomaly detection architectures. Empirically, this substitution yields consistent performance gains and substantially improved training stability across multiple benchmarks and model backbones for both image-level and pixel-level detection. These results unify two major anomaly detection paradigms, advancing both theoretical understanding and practical performance.
Uncertainty Awareness and Trust in Explainable AI- On Trust Calibration using Local and Global Explanations
Sep 10, 2025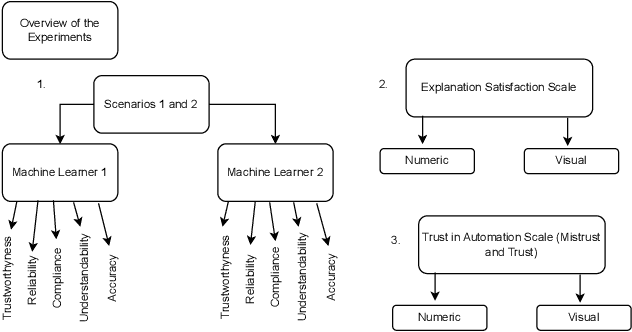


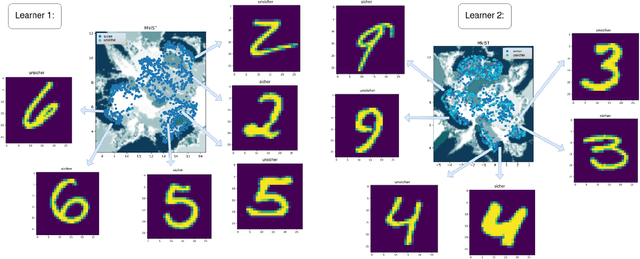
Explainable AI has become a common term in the literature, scrutinized by computer scientists and statisticians and highlighted by psychological or philosophical researchers. One major effort many researchers tackle is constructing general guidelines for XAI schemes, which we derived from our study. While some areas of XAI are well studied, we focus on uncertainty explanations and consider global explanations, which are often left out. We chose an algorithm that covers various concepts simultaneously, such as uncertainty, robustness, and global XAI, and tested its ability to calibrate trust. We then checked whether an algorithm that aims to provide more of an intuitive visual understanding, despite being complicated to understand, can provide higher user satisfaction and human interpretability.
Rare anomalies require large datasets: About proving the existence of anomalies
Aug 13, 2025
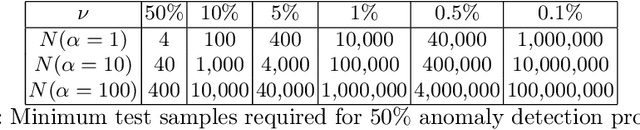
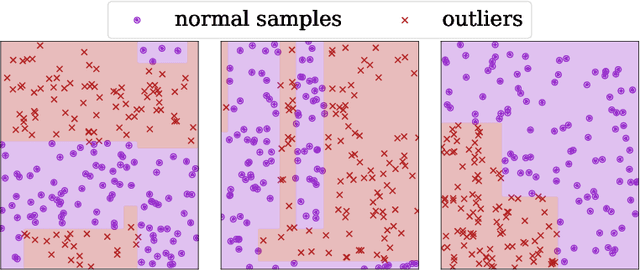
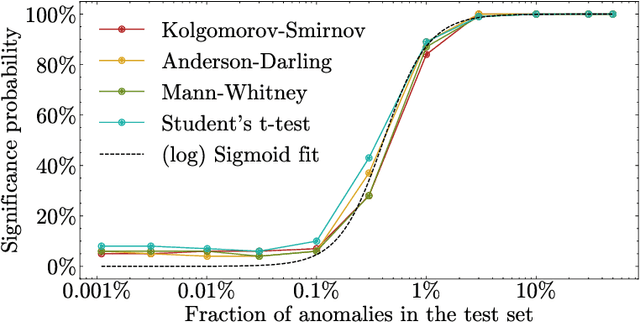
Detecting whether any anomalies exist within a dataset is crucial for effective anomaly detection, yet it remains surprisingly underexplored in anomaly detection literature. This paper presents a comprehensive study that addresses the fundamental question: When can we conclusively determine that anomalies are present? Through extensive experimentation involving over three million statistical tests across various anomaly detection tasks and algorithms, we identify a relationship between the dataset size, contamination rate, and an algorithm-dependent constant $ \alpha_{\text{algo}} $. Our results demonstrate that, for an unlabeled dataset of size $ N $ and contamination rate $ \nu $, the condition $ N \ge \frac{\alpha_{\text{algo}}}{\nu^2} $ represents a lower bound on the number of samples required to confirm anomaly existence. This threshold implies a limit to how rare anomalies can be before proving their existence becomes infeasible.
Polyra Swarms: A Shape-Based Approach to Machine Learning
Jun 16, 2025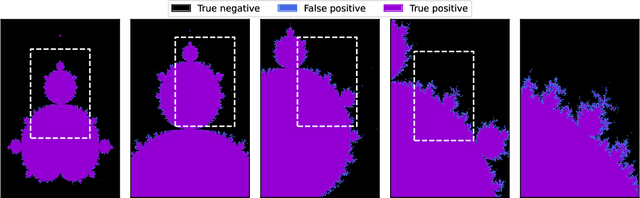



We propose Polyra Swarms, a novel machine-learning approach that approximates shapes instead of functions. Our method enables general-purpose learning with very low bias. In particular, we show that depending on the task, Polyra Swarms can be preferable compared to neural networks, especially for tasks like anomaly detection. We further introduce an automated abstraction mechanism that simplifies the complexity of a Polyra Swarm significantly, enhancing both their generalization and transparency. Since Polyra Swarms operate on fundamentally different principles than neural networks, they open up new research directions with distinct strengths and limitations.
Do you see what I see? An Ambiguous Optical Illusion Dataset exposing limitations of Explainable AI
May 27, 2025



From uncertainty quantification to real-world object detection, we recognize the importance of machine learning algorithms, particularly in safety-critical domains such as autonomous driving or medical diagnostics. In machine learning, ambiguous data plays an important role in various machine learning domains. Optical illusions present a compelling area of study in this context, as they offer insight into the limitations of both human and machine perception. Despite this relevance, optical illusion datasets remain scarce. In this work, we introduce a novel dataset of optical illusions featuring intermingled animal pairs designed to evoke perceptual ambiguity. We identify generalizable visual concepts, particularly gaze direction and eye cues, as subtle yet impactful features that significantly influence model accuracy. By confronting models with perceptual ambiguity, our findings underscore the importance of concepts in visual learning and provide a foundation for studying bias and alignment between human and machine vision. To make this dataset useful for general purposes, we generate optical illusions systematically with different concepts discussed in our bias mitigation section. The dataset is accessible in Kaggle via https://kaggle.com/datasets/693bf7c6dd2cb45c8a863f9177350c8f9849a9508e9d50526e2ffcc5559a8333. Our source code can be found at https://github.com/KDD-OpenSource/Ambivision.git.
Unsupervised Surrogate Anomaly Detection
Apr 29, 2025In this paper, we study unsupervised anomaly detection algorithms that learn a neural network representation, i.e. regular patterns of normal data, which anomalies are deviating from. Inspired by a similar concept in engineering, we refer to our methodology as surrogate anomaly detection. We formalize the concept of surrogate anomaly detection into a set of axioms required for optimal surrogate models and propose a new algorithm, named DEAN (Deep Ensemble ANomaly detection), designed to fulfill these criteria. We evaluate DEAN on 121 benchmark datasets, demonstrating its competitive performance against 19 existing methods, as well as the scalability and reliability of our method.