 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Uniformly Scaling Flows: A Density-Aligned Approach to Deep One-Class Classification
Oct 10, 2025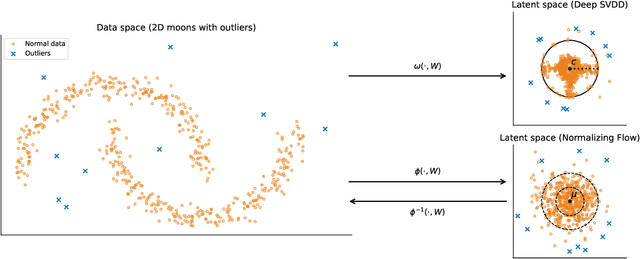
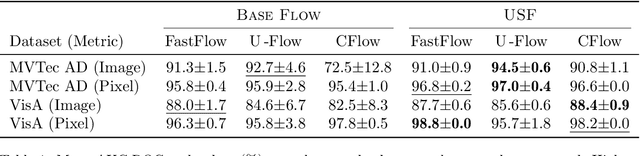
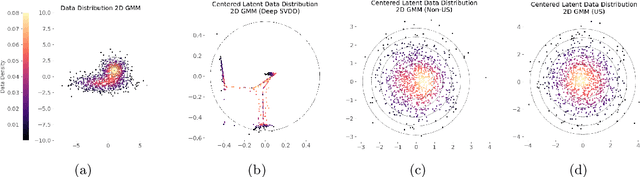
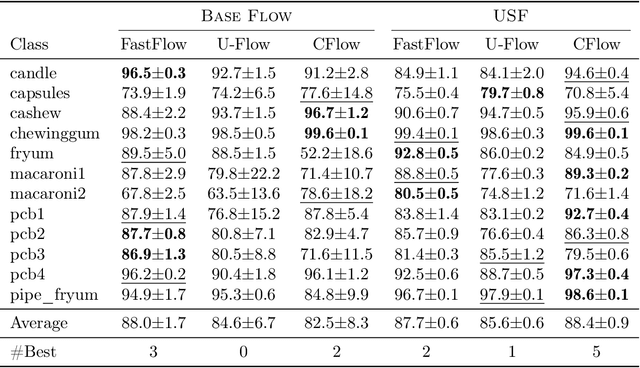
Unsupervised anomaly detection is often framed around two widely studied paradigms. Deep one-class classification, exemplified by Deep SVDD, learns compact latent representations of normality, while density estimators realized by normalizing flows directly model the likelihood of nominal data. In this work, we show that uniformly scaling flows (USFs), normalizing flows with a constant Jacobian determinant, precisely connect these approaches. Specifically, we prove how training a USF via maximum-likelihood reduces to a Deep SVDD objective with a unique regularization that inherently prevents representational collapse. This theoretical bridge implies that USFs inherit both the density faithfulness of flows and the distance-based reasoning of one-class methods. We further demonstrate that USFs induce a tighter alignment between negative log-likelihood and latent norm than either Deep SVDD or non-USFs, and how recent hybrid approaches combining one-class objectives with VAEs can be naturally extended to USFs. Consequently, we advocate using USFs as a drop-in replacement for non-USFs in modern anomaly detection architectures. Empirically, this substitution yields consistent performance gains and substantially improved training stability across multiple benchmarks and model backbones for both image-level and pixel-level detection. These results unify two major anomaly detection paradigms, advancing both theoretical understanding and practical performance.
sbi reloaded: a toolkit for simulation-based inference workflows
Nov 26, 2024
Scientists and engineers use simulators to model empirically observed phenomena. However, tuning the parameters of a simulator to ensure its outputs match observed data presents a significant challenge. Simulation-based inference (SBI) addresses this by enabling Bayesian inference for simulators, identifying parameters that match observed data and align with prior knowledge. Unlike traditional Bayesian inference, SBI only needs access to simulations from the model and does not require evaluations of the likelihood-function. In addition, SBI algorithms do not require gradients through the simulator, allow for massive parallelization of simulations, and can perform inference for different observations without further simulations or training, thereby amortizing inference. Over the past years, we have developed, maintained, and extended $\texttt{sbi}$, a PyTorch-based package that implements Bayesian SBI algorithms based on neural networks. The $\texttt{sbi}$ toolkit implements a wide range of inference methods, neural network architectures, sampling methods, and diagnostic tools. In addition, it provides well-tested default settings but also offers flexibility to fully customize every step of the simulation-based inference workflow. Taken together, the $\texttt{sbi}$ toolkit enables scientists and engineers to apply state-of-the-art SBI methods to black-box simulators, opening up new possibilities for aligning simulations with empirically observed data.
VeriFlow: Modeling Distributions for Neural Network Verification
Jun 20, 2024Formal verification has emerged as a promising method to ensure the safety and reliability of neural networks. Naively verifying a safety property amounts to ensuring the safety of a neural network for the whole input space irrespective of any training or test set. However, this also implies that the safety of the neural network is checked even for inputs that do not occur in the real-world and have no meaning at all, often resulting in spurious errors. To tackle this shortcoming, we propose the VeriFlow architecture as a flow based density model tailored to allow any verification approach to restrict its search to the some data distribution of interest. We argue that our architecture is particularly well suited for this purpose because of two major properties. First, we show that the transformation and log-density function that are defined by our model are piece-wise affine. Therefore, the model allows the usage of verifiers based on SMT with linear arithmetic. Second, upper density level sets (UDL) of the data distribution take the shape of an $L^p$-ball in the latent space. As a consequence, representations of UDLs specified by a given probability are effectively computable in latent space. This allows for SMT and abstract interpretation approaches with fine-grained, probabilistically interpretable, control regarding on how (a)typical the inputs subject to verification are.