 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTevent: A Multi-Task Event Camera Dataset for 6D Pose Estimation and Moving Object Detection
May 16, 2025Mobile robots are reaching unprecedented speeds, with platforms like Unitree B2, and Fraunhofer O3dyn achieving maximum speeds between 5 and 10 m/s. However, effectively utilizing such speeds remains a challenge due to the limitations of RGB cameras, which suffer from motion blur and fail to provide real-time responsiveness. Event cameras, with their asynchronous operation, and low-latency sensing, offer a promising alternative for high-speed robotic perception. In this work, we introduce MTevent, a dataset designed for 6D pose estimation and moving object detection in highly dynamic environments with large detection distances. Our setup consists of a stereo-event camera and an RGB camera, capturing 75 scenes, each on average 16 seconds, and featuring 16 unique objects under challenging conditions such as extreme viewing angles, varying lighting, and occlusions. MTevent is the first dataset to combine high-speed motion, long-range perception, and real-world object interactions, making it a valuable resource for advancing event-based vision in robotics. To establish a baseline, we evaluate the task of 6D pose estimation using NVIDIA's FoundationPose on RGB images, achieving an Average Recall of 0.22 with ground-truth masks, highlighting the limitations of RGB-based approaches in such dynamic settings. With MTevent, we provide a novel resource to improve perception models and foster further research in high-speed robotic vision. The dataset is available for download https://huggingface.co/datasets/anas-gouda/MTevent
A Cautionary Tale About "Neutrally" Informative AI Tools Ahead of the 2025 Federal Elections in Germany
Feb 21, 2025In this study, we examine the reliability of AI-based Voting Advice Applications (VAAs) and large language models (LLMs) in providing objective political information. Our analysis is based upon a comparison with party responses to 38 statements of the Wahl-O-Mat, a well-established German online tool that helps inform voters by comparing their views with political party positions. For the LLMs, we identify significant biases. They exhibit a strong alignment (over 75% on average) with left-wing parties and a substantially lower alignment with center-right (smaller 50%) and right-wing parties (around 30%). Furthermore, for the VAAs, intended to objectively inform voters, we found substantial deviations from the parties' stated positions in Wahl-O-Mat: While one VAA deviated in 25% of cases, another VAA showed deviations in more than 50% of cases. For the latter, we even observed that simple prompt injections led to severe hallucinations, including false claims such as non-existent connections between political parties and right-wing extremist ties.
The Self-Perception and Political Biases of ChatGPT
Apr 14, 2023
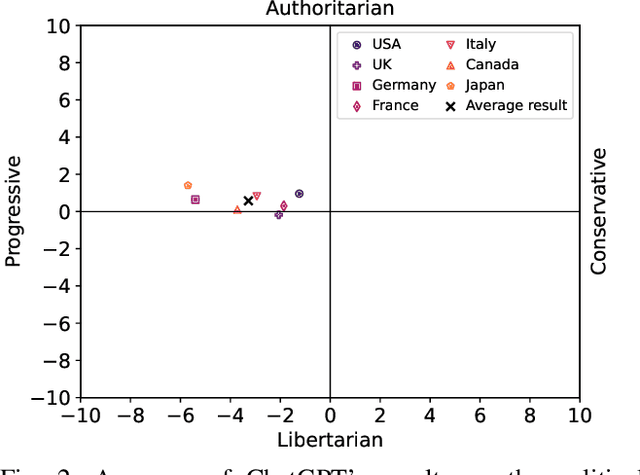


This contribution analyzes the self-perception and political biases of OpenAI's Large Language Model ChatGPT. Taking into account the first small-scale reports and studies that have emerged, claiming that ChatGPT is politically biased towards progressive and libertarian points of view, this contribution aims to provide further clarity on this subject. For this purpose, ChatGPT was asked to answer the questions posed by the political compass test as well as similar questionnaires that are specific to the respective politics of the G7 member states. These eight tests were repeated ten times each and revealed that ChatGPT seems to hold a bias towards progressive views. The political compass test revealed a bias towards progressive and libertarian views, with the average coordinates on the political compass being (-6.48, -5.99) (with (0, 0) the center of the compass, i.e., centrism and the axes ranging from -10 to 10), supporting the claims of prior research. The political questionnaires for the G7 member states indicated a bias towards progressive views but no significant bias between authoritarian and libertarian views, contradicting the findings of prior reports, with the average coordinates being (-3.27, 0.58). In addition, ChatGPT's Big Five personality traits were tested using the OCEAN test and its personality type was queried using the Myers-Briggs Type Indicator (MBTI) test. Finally, the maliciousness of ChatGPT was evaluated using the Dark Factor test. These three tests were also repeated ten times each, revealing that ChatGPT perceives itself as highly open and agreeable, has the Myers-Briggs personality type ENFJ, and is among the 15% of test-takers with the least pronounced dark traits.
Semi-Automated Computer Vision based Tracking of Multiple Industrial Entities -- A Framework and Dataset Creation Approach
Apr 03, 2023This contribution presents the TOMIE framework (Tracking Of Multiple Industrial Entities), a framework for the continuous tracking of industrial entities (e.g., pallets, crates, barrels) over a network of, in this example, six RGB cameras. This framework, makes use of multiple sensors, data pipelines and data annotation procedures, and is described in detail in this contribution. With the vision of a fully automated tracking system for industrial entities in mind, it enables researchers to efficiently capture high quality data in an industrial setting. Using this framework, an image dataset, the TOMIE dataset, is created, which at the same time is used to gauge the framework's validity. This dataset contains annotation files for 112,860 frames and 640,936 entity instances that are captured from a set of six cameras that perceive a large indoor space. This dataset out-scales comparable datasets by a factor of four and is made up of scenarios, drawn from industrial applications from the sector of warehousing. Three tracking algorithms, namely ByteTrack, Bot-Sort and SiamMOT are applied to this dataset, serving as a proof-of-concept and providing tracking results that are comparable to the state of the art.
Applications of human activity recognition in industrial processes -- Synergy of human and technology
Dec 05, 2022Human-technology collaboration relies on verbal and non-verbal communication. Machines must be able to detect and understand the movements of humans to facilitate non-verbal communication. In this article, we introduce ongoing research on human activity recognition in intralogistics, and show how it can be applied in industrial settings. We show how semantic attributes can be used to describe human activities flexibly and how context informantion increases the performance of classifiers to recognise them automatically. Beyond that, we present a concept based on a cyber-physical twin that can reduce the effort and time necessary to create a training dataset for human activity recognition. In the future, it will be possible to train a classifier solely with realistic simulation data, while maintaining or even increasing the classification performance.