 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTevent: A Multi-Task Event Camera Dataset for 6D Pose Estimation and Moving Object Detection
May 16, 2025Mobile robots are reaching unprecedented speeds, with platforms like Unitree B2, and Fraunhofer O3dyn achieving maximum speeds between 5 and 10 m/s. However, effectively utilizing such speeds remains a challenge due to the limitations of RGB cameras, which suffer from motion blur and fail to provide real-time responsiveness. Event cameras, with their asynchronous operation, and low-latency sensing, offer a promising alternative for high-speed robotic perception. In this work, we introduce MTevent, a dataset designed for 6D pose estimation and moving object detection in highly dynamic environments with large detection distances. Our setup consists of a stereo-event camera and an RGB camera, capturing 75 scenes, each on average 16 seconds, and featuring 16 unique objects under challenging conditions such as extreme viewing angles, varying lighting, and occlusions. MTevent is the first dataset to combine high-speed motion, long-range perception, and real-world object interactions, making it a valuable resource for advancing event-based vision in robotics. To establish a baseline, we evaluate the task of 6D pose estimation using NVIDIA's FoundationPose on RGB images, achieving an Average Recall of 0.22 with ground-truth masks, highlighting the limitations of RGB-based approaches in such dynamic settings. With MTevent, we provide a novel resource to improve perception models and foster further research in high-speed robotic vision. The dataset is available for download https://huggingface.co/datasets/anas-gouda/MTevent
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
Learning Embeddings with Centroid Triplet Loss for Object Identification in Robotic Grasping
Apr 09, 2024Foundation models are a strong trend in deep learning and computer vision. These models serve as a base for applications as they require minor or no further fine-tuning by developers to integrate into their applications. Foundation models for zero-shot object segmentation such as Segment Anything (SAM) output segmentation masks from images without any further object information. When they are followed in a pipeline by an object identification model, they can perform object detection without training. Here, we focus on training such an object identification model. A crucial practical aspect for an object identification model is to be flexible in input size. As object identification is an image retrieval problem, a suitable method should handle multi-query multi-gallery situations without constraining the number of input images (e.g. by having fixed-size aggregation layers). The key solution to train such a model is the centroid triplet loss (CTL), which aggregates image features to their centroids. CTL yields high accuracy, avoids misleading training signals and keeps the model input size flexible. In our experiments, we establish a new state of the art on the ArmBench object identification task, which shows general applicability of our model. We furthermore demonstrate an integrated unseen object detection pipeline on the challenging HOPE dataset, which requires fine-grained detection. There, our pipeline matches and surpasses related methods which have been trained on dataset-specific data.
Event Camera as Region Proposal Network
May 01, 2023The human eye consists of two types of photoreceptors, rods and cones. Rods are responsible for monochrome vision, and cones for color vision. The number of rods is much higher than the cones, which means that most human vision processing is done in monochrome. An event camera reports the change in pixel intensity and is analogous to rods. Event and color cameras in computer vision are like rods and cones in human vision. Humans can notice objects moving in the peripheral vision (far right and left), but we cannot classify them (think of someone passing by on your far left or far right, this can trigger your attention without knowing who they are). Thus, rods act as a region proposal network (RPN) in human vision. Therefore, an event camera can act as a region proposal network in deep learning Two-stage object detectors in deep learning, such as Mask R-CNN, consist of a backbone for feature extraction and a RPN. Currently, RPN uses the brute force method by trying out all the possible bounding boxes to detect an object. This requires much computation time to generate region proposals making two-stage detectors inconvenient for fast applications. This work replaces the RPN in Mask-RCNN of detectron2 with an event camera for generating proposals for moving objects. Thus, saving time and being computationally less expensive. The proposed approach is faster than the two-stage detectors with comparable accuracy
DoUnseen: Zero-Shot Object Detection for Robotic Grasping
Apr 06, 2023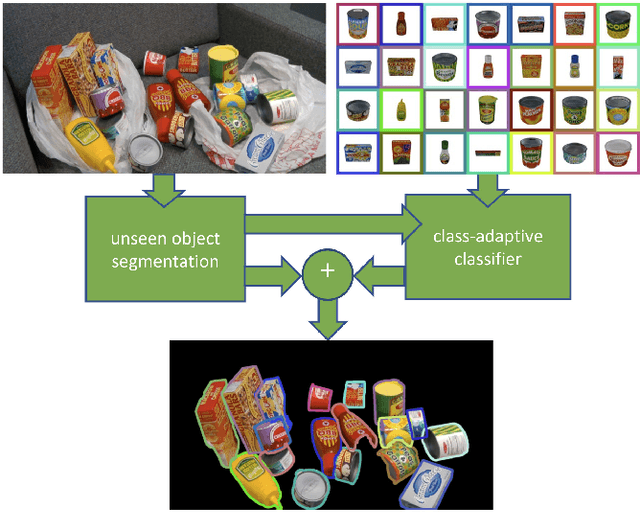
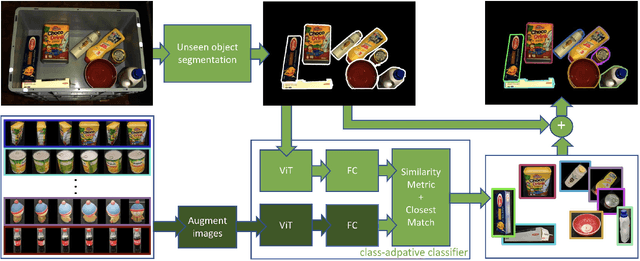

How can we segment varying numbers of objects where each specific object represents its own separate class? To make the problem even more realistic, how can we add and delete classes on the fly without retraining? This is the case of robotic applications where no datasets of the objects exist or application that includes thousands of objects (E.g., in logistics) where it is impossible to train a single model to learn all of the objects. Most current research on object segmentation for robotic grasping focuses on class-level object segmentation (E.g., box, cup, bottle), closed sets (specific objects of a dataset; for example, YCB dataset), or deep learning-based template matching. In this work, we are interested in open sets where the number of classes is unknown, varying, and without pre-knowledge about the objects' types. We consider each specific object as its own separate class. Our goal is to develop a zero-shot object detector that requires no training and can add any object as a class just by capturing a few images of the object. Our main idea is to break the segmentation pipelines into two steps by combining unseen object segmentation networks cascaded by zero-shot classifiers. We evaluate our zero-shot object detector on unseen datasets and compare it to a trained Mask R-CNN on those datasets. The results show that the performance varies from practical to unsuitable depending on the environment setup and the objects being handled. The code is available in our DoUnseen library repository.
A Grid-based Sensor Floor Platform for Robot Localization using Machine Learning
Dec 09, 2022Wireless Sensor Network (WSN) applications reshape the trend of warehouse monitoring systems allowing them to track and locate massive numbers of logistic entities in real-time. To support the tasks, classic Radio Frequency (RF)-based localization approaches (e.g. triangulation and trilateration) confront challenges due to multi-path fading and signal loss in noisy warehouse environment. In this paper, we investigate machine learning methods using a new grid-based WSN platform called Sensor Floor that can overcome the issues. Sensor Floor consists of 345 nodes installed across the floor of our logistic research hall with dual-band RF and Inertial Measurement Unit (IMU) sensors. Our goal is to localize all logistic entities, for this study we use a mobile robot. We record distributed sensing measurements of Received Signal Strength Indicator (RSSI) and IMU values as the dataset and position tracking from Vicon system as the ground truth. The asynchronous collected data is pre-processed and trained using Random Forest and Convolutional Neural Network (CNN). The CNN model with regularization outperforms the Random Forest in terms of localization accuracy with aproximate 15 cm. Moreover, the CNN architecture can be configured flexibly depending on the scenario in the warehouse. The hardware, software and the CNN architecture of the Sensor Floor are open-source under https://github.com/FLW-TUDO/sensorfloor.
Category-agnostic Segmentation for Robotic Grasping
Apr 28, 2022



In this work we introduce DoPose, a dataset of highly cluttered and closely stacked objects for segmentation and 6D pose estimation. We show how using careful choice of synthetic data and fine-tuning on our real dataset along with a rational training can boost the performance of already existing CNN architectures to generalize on real data and produce comparable results to SOTA methods even without post-processing or refinements. Our DoPose dataset, network models, pipeline code and ROS driver are available online.