 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-centering 3-DOF feet controller for hands-free locomotion control in telepresence and virtual reality
Aug 05, 2024



We present a novel seated foot controller for handling 3-DOF aimed to control locomotion for telepresence robotics and virtual reality environments. Tilting the feet on two axes yields in forward, backward and sideways motion. In addition, a separate rotary joint allows for rotation around the vertical axis. Attached springs on all joints self-center the controller. The HTC Vive tracker is used to translate the trackers' orientation into locomotion commands. The proposed self-centering foot controller was used successfully for the ANA Avatar XPRIZE competition, where a naive operator traversed the robot through a longer distance, surpassing obstacles while solving various interaction and manipulation tasks in between. We publicly provide the models of the mostly 3D-printed feet controller for reproduction.
FSRT: Facial Scene Representation Transformer for Face Reenactment from Factorized Appearance, Head-pose, and Facial Expression Features
Apr 15, 2024The task of face reenactment is to transfer the head motion and facial expressions from a driving video to the appearance of a source image, which may be of a different person (cross-reenactment). Most existing methods are CNN-based and estimate optical flow from the source image to the current driving frame, which is then inpainted and refined to produce the output animation. We propose a transformer-based encoder for computing a set-latent representation of the source image(s). We then predict the output color of a query pixel using a transformer-based decoder, which is conditioned with keypoints and a facial expression vector extracted from the driving frame. Latent representations of the source person are learned in a self-supervised manner that factorize their appearance, head pose, and facial expressions. Thus, they are perfectly suited for cross-reenactment. In contrast to most related work, our method naturally extends to multiple source images and can thus adapt to person-specific facial dynamics. We also propose data augmentation and regularization schemes that are necessary to prevent overfitting and support generalizability of the learned representations. We evaluated our approach in a randomized user study. The results indicate superior performance compared to the state-of-the-art in terms of motion transfer quality and temporal consistency.
Learning Embeddings with Centroid Triplet Loss for Object Identification in Robotic Grasping
Apr 09, 2024Foundation models are a strong trend in deep learning and computer vision. These models serve as a base for applications as they require minor or no further fine-tuning by developers to integrate into their applications. Foundation models for zero-shot object segmentation such as Segment Anything (SAM) output segmentation masks from images without any further object information. When they are followed in a pipeline by an object identification model, they can perform object detection without training. Here, we focus on training such an object identification model. A crucial practical aspect for an object identification model is to be flexible in input size. As object identification is an image retrieval problem, a suitable method should handle multi-query multi-gallery situations without constraining the number of input images (e.g. by having fixed-size aggregation layers). The key solution to train such a model is the centroid triplet loss (CTL), which aggregates image features to their centroids. CTL yields high accuracy, avoids misleading training signals and keeps the model input size flexible. In our experiments, we establish a new state of the art on the ArmBench object identification task, which shows general applicability of our model. We furthermore demonstrate an integrated unseen object detection pipeline on the challenging HOPE dataset, which requires fine-grained detection. There, our pipeline matches and surpasses related methods which have been trained on dataset-specific data.
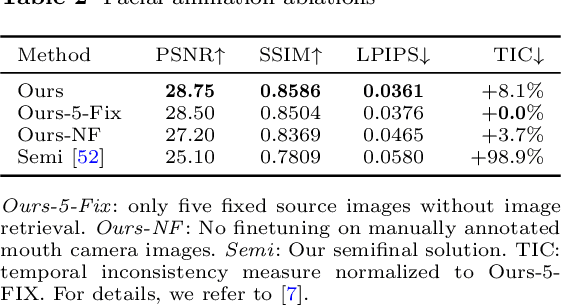
Attention-Based VR Facial Animation with Visual Mouth Camera Guidance for Immersive Telepresence Avatars
Dec 15, 2023Facial animation in virtual reality environments is essential for applications that necessitate clear visibility of the user's face and the ability to convey emotional signals. In our scenario, we animate the face of an operator who controls a robotic Avatar system. The use of facial animation is particularly valuable when the perception of interacting with a specific individual, rather than just a robot, is intended. Purely keypoint-driven animation approaches struggle with the complexity of facial movements. We present a hybrid method that uses both keypoints and direct visual guidance from a mouth camera. Our method generalizes to unseen operators and requires only a quick enrolment step with capture of two short videos. Multiple source images are selected with the intention to cover different facial expressions. Given a mouth camera frame from the HMD, we dynamically construct the target keypoints and apply an attention mechanism to determine the importance of each source image. To resolve keypoint ambiguities and animate a broader range of mouth expressions, we propose to inject visual mouth camera information into the latent space. We enable training on large-scale speaking head datasets by simulating the mouth camera input with its perspective differences and facial deformations. Our method outperforms a baseline in quality, capability, and temporal consistency. In addition, we highlight how the facial animation contributed to our victory at the ANA Avatar XPRIZE Finals.
Learning from SAM: Harnessing a Segmentation Foundation Model for Sim2Real Domain Adaptation through Regularization
Sep 27, 2023



Domain adaptation is especially important for robotics applications, where target domain training data is usually scarce and annotations are costly to obtain. We present a method for self-supervised domain adaptation for the scenario where annotated source domain data (e.g. from synthetic generation) is available, but the target domain data is completely unannotated. Our method targets the semantic segmentation task and leverages a segmentation foundation model (Segment Anything Model) to obtain segment information on unannotated data. We take inspiration from recent advances in unsupervised local feature learning and propose an invariance-variance loss structure over the detected segments for regularizing feature representations in the target domain. Crucially, this loss structure and network architecture can handle overlapping segments and oversegmentation as produced by Segment Anything. We demonstrate the advantage of our method on the challenging YCB-Video and HomebrewedDB datasets and show that it outperforms prior work and, on YCB-Video, even a network trained with real annotations.
NimbRo wins ANA Avatar XPRIZE Immersive Telepresence Competition: Human-Centric Evaluation and Lessons Learned
Aug 28, 2023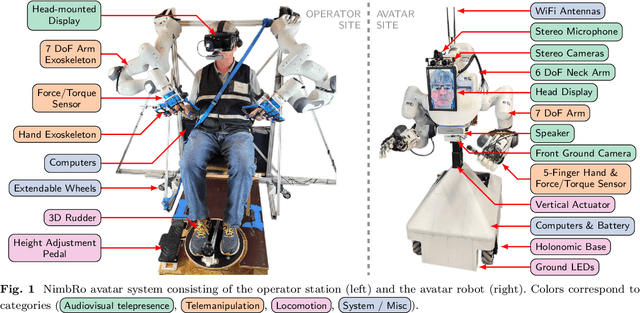


Robotic avatar systems can enable immersive telepresence with locomotion, manipulation, and communication capabilities. We present such an avatar system, based on the key components of immersive 3D visualization and transparent force-feedback telemanipulation. Our avatar robot features an anthropomorphic upper body with dexterous hands. The remote human operator drives the arms and fingers through an exoskeleton-based operator station, which provides force feedback both at the wrist and for each finger. The robot torso is mounted on a holonomic base, providing omnidirectional locomotion on flat floors, controlled using a 3D rudder device. Finally, the robot features a 6D movable head with stereo cameras, which stream images to a VR display worn by the operator. Movement latency is hidden using spherical rendering. The head also carries a telepresence screen displaying an animated image of the operator's face, enabling direct interaction with remote persons. Our system won the \$10M ANA Avatar XPRIZE competition, which challenged teams to develop intuitive and immersive avatar systems that could be operated by briefly trained judges. We analyze our successful participation in the semifinals and finals and provide insight into our operator training and lessons learned. In addition, we evaluate our system in a user study that demonstrates its intuitive and easy usability.
VR Facial Animation for Immersive Telepresence Avatars
Apr 24, 2023VR Facial Animation is necessary in applications requiring clear view of the face, even though a VR headset is worn. In our case, we aim to animate the face of an operator who is controlling our robotic avatar system. We propose a real-time capable pipeline with very fast adaptation for specific operators. In a quick enrollment step, we capture a sequence of source images from the operator without the VR headset which contain all the important operator-specific appearance information. During inference, we then use the operator keypoint information extracted from a mouth camera and two eye cameras to estimate the target expression and head pose, to which we map the appearance of a source still image. In order to enhance the mouth expression accuracy, we dynamically select an auxiliary expression frame from the captured sequence. This selection is done by learning to transform the current mouth keypoints into the source camera space, where the alignment can be determined accurately. We, furthermore, demonstrate an eye tracking pipeline that can be trained in less than a minute, a time efficient way to train the whole pipeline given a dataset that includes only complete faces, show exemplary results generated by our method, and discuss performance at the ANA Avatar XPRIZE semifinals.
Audio-based Roughness Sensing and Tactile Feedback for Haptic Perception in Telepresence
Mar 13, 2023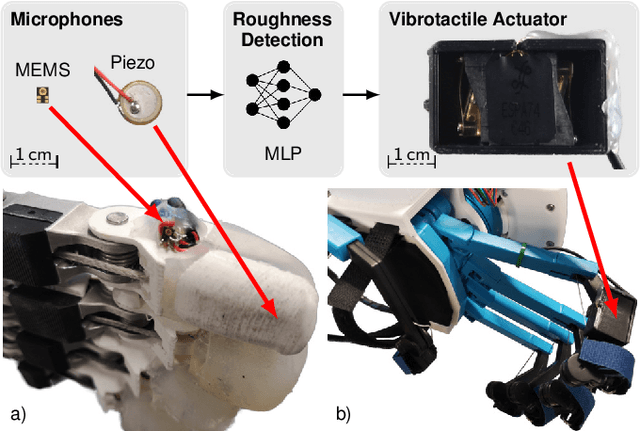
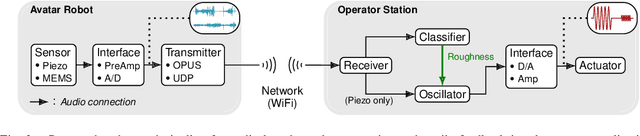
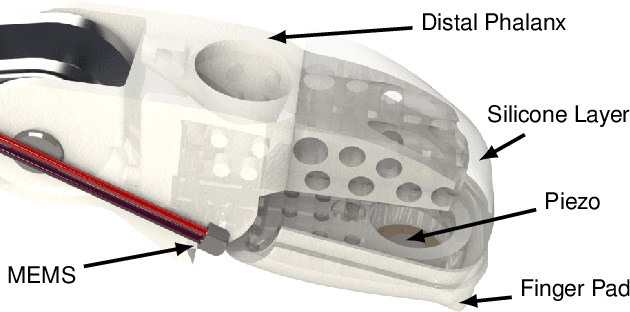

Haptic perception is incredibly important for immersive teleoperation of robots, especially for accomplishing manipulation tasks. We propose a low-cost haptic sensing and rendering system, which is capable of detecting and displaying surface roughness. As the robot fingertip moves across a surface of interest, two microphones capture sound coupled directly through the fingertip and through the air, respectively. A learning-based detector system analyzes the data in real-time and gives roughness estimates with both high temporal resolution and low latency. Finally, an audio-based haptic actuator displays the result to the human operator. We demonstrate the effectiveness of our system through experiments and our winning entry in the ANA Avatar XPRIZE competition finals, where impartial judges solved a roughness-based selection task even without additional vision feedback. We publish our dataset used for training and evaluation together with our trained models to enable reproducibility.
Robust Immersive Telepresence and Mobile Telemanipulation: NimbRo wins ANA Avatar XPRIZE Finals
Mar 06, 2023
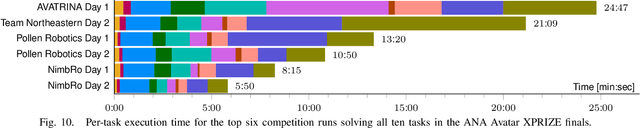
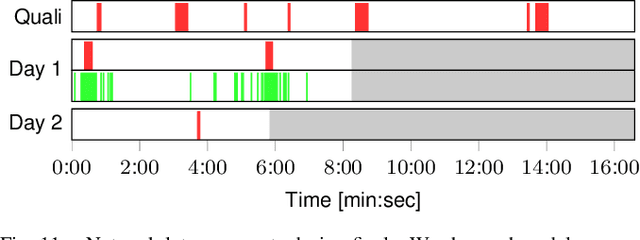

Robotic avatar systems promise to bridge distances and reduce the need for travel. We present the updated NimbRo avatar system, winner of the $5M grand prize at the international ANA Avatar XPRIZE competition, which required participants to build intuitive and immersive telepresence robots that could be operated by briefly trained operators. We describe key improvements for the finals compared to the system used in the semifinals: To operate without a power- and communications tether, we integrate a battery and a robust redundant wireless communication system. Video and audio data are compressed using low-latency HEVC and Opus codecs. We propose a new locomotion control device with tunable resistance force. To increase flexibility, the robot's upper-body height can be adjusted by the operator. We describe essential monitoring and robustness tools which enabled the success at the competition. Finally, we analyze our performance at the competition finals and discuss lessons learned.
Predicting Physical Object Properties from Video
Jun 02, 2022

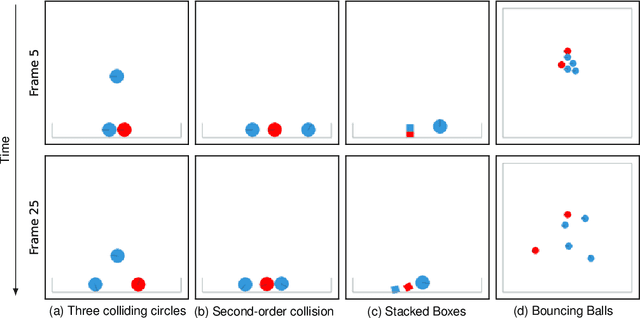
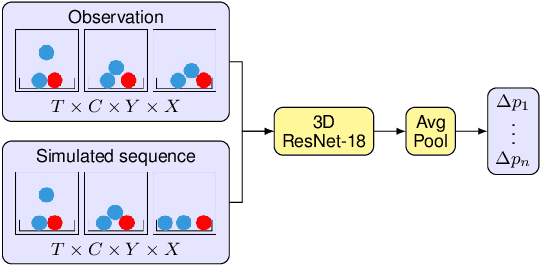
We present a novel approach to estimating physical properties of objects from video. Our approach consists of a physics engine and a correction estimator. Starting from the initial observed state, object behavior is simulated forward in time. Based on the simulated and observed behavior, the correction estimator then determines refined physical parameters for each object. The method can be iterated for increased precision. Our approach is generic, as it allows for the use of an arbitrary - not necessarily differentiable - physics engine and correction estimator. For the latter, we evaluate both gradient-free hyperparameter optimization and a deep convolutional neural network. We demonstrate faster and more robust convergence of the learned method in several simulated 2D scenarios focusing on bin situations.