 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSRT: Facial Scene Representation Transformer for Face Reenactment from Factorized Appearance, Head-pose, and Facial Expression Features
Apr 15, 2024The task of face reenactment is to transfer the head motion and facial expressions from a driving video to the appearance of a source image, which may be of a different person (cross-reenactment). Most existing methods are CNN-based and estimate optical flow from the source image to the current driving frame, which is then inpainted and refined to produce the output animation. We propose a transformer-based encoder for computing a set-latent representation of the source image(s). We then predict the output color of a query pixel using a transformer-based decoder, which is conditioned with keypoints and a facial expression vector extracted from the driving frame. Latent representations of the source person are learned in a self-supervised manner that factorize their appearance, head pose, and facial expressions. Thus, they are perfectly suited for cross-reenactment. In contrast to most related work, our method naturally extends to multiple source images and can thus adapt to person-specific facial dynamics. We also propose data augmentation and regularization schemes that are necessary to prevent overfitting and support generalizability of the learned representations. We evaluated our approach in a randomized user study. The results indicate superior performance compared to the state-of-the-art in terms of motion transfer quality and temporal consistency.
Attention-Based VR Facial Animation with Visual Mouth Camera Guidance for Immersive Telepresence Avatars
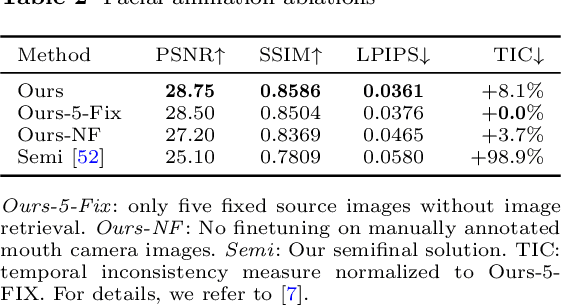
Dec 15, 2023Facial animation in virtual reality environments is essential for applications that necessitate clear visibility of the user's face and the ability to convey emotional signals. In our scenario, we animate the face of an operator who controls a robotic Avatar system. The use of facial animation is particularly valuable when the perception of interacting with a specific individual, rather than just a robot, is intended. Purely keypoint-driven animation approaches struggle with the complexity of facial movements. We present a hybrid method that uses both keypoints and direct visual guidance from a mouth camera. Our method generalizes to unseen operators and requires only a quick enrolment step with capture of two short videos. Multiple source images are selected with the intention to cover different facial expressions. Given a mouth camera frame from the HMD, we dynamically construct the target keypoints and apply an attention mechanism to determine the importance of each source image. To resolve keypoint ambiguities and animate a broader range of mouth expressions, we propose to inject visual mouth camera information into the latent space. We enable training on large-scale speaking head datasets by simulating the mouth camera input with its perspective differences and facial deformations. Our method outperforms a baseline in quality, capability, and temporal consistency. In addition, we highlight how the facial animation contributed to our victory at the ANA Avatar XPRIZE Finals.
NimbRo wins ANA Avatar XPRIZE Immersive Telepresence Competition: Human-Centric Evaluation and Lessons Learned
Aug 28, 2023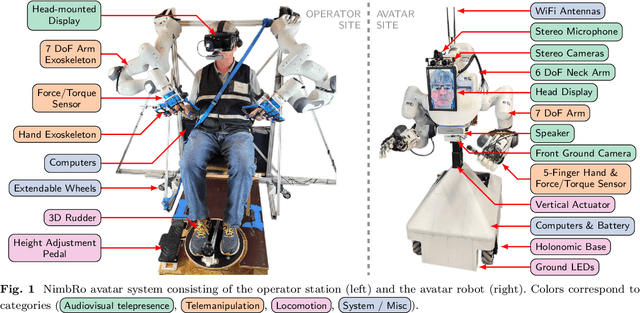


Robotic avatar systems can enable immersive telepresence with locomotion, manipulation, and communication capabilities. We present such an avatar system, based on the key components of immersive 3D visualization and transparent force-feedback telemanipulation. Our avatar robot features an anthropomorphic upper body with dexterous hands. The remote human operator drives the arms and fingers through an exoskeleton-based operator station, which provides force feedback both at the wrist and for each finger. The robot torso is mounted on a holonomic base, providing omnidirectional locomotion on flat floors, controlled using a 3D rudder device. Finally, the robot features a 6D movable head with stereo cameras, which stream images to a VR display worn by the operator. Movement latency is hidden using spherical rendering. The head also carries a telepresence screen displaying an animated image of the operator's face, enabling direct interaction with remote persons. Our system won the \$10M ANA Avatar XPRIZE competition, which challenged teams to develop intuitive and immersive avatar systems that could be operated by briefly trained judges. We analyze our successful participation in the semifinals and finals and provide insight into our operator training and lessons learned. In addition, we evaluate our system in a user study that demonstrates its intuitive and easy usability.
VR Facial Animation for Immersive Telepresence Avatars
Apr 24, 2023VR Facial Animation is necessary in applications requiring clear view of the face, even though a VR headset is worn. In our case, we aim to animate the face of an operator who is controlling our robotic avatar system. We propose a real-time capable pipeline with very fast adaptation for specific operators. In a quick enrollment step, we capture a sequence of source images from the operator without the VR headset which contain all the important operator-specific appearance information. During inference, we then use the operator keypoint information extracted from a mouth camera and two eye cameras to estimate the target expression and head pose, to which we map the appearance of a source still image. In order to enhance the mouth expression accuracy, we dynamically select an auxiliary expression frame from the captured sequence. This selection is done by learning to transform the current mouth keypoints into the source camera space, where the alignment can be determined accurately. We, furthermore, demonstrate an eye tracking pipeline that can be trained in less than a minute, a time efficient way to train the whole pipeline given a dataset that includes only complete faces, show exemplary results generated by our method, and discuss performance at the ANA Avatar XPRIZE semifinals.
Audio-based Roughness Sensing and Tactile Feedback for Haptic Perception in Telepresence
Mar 13, 2023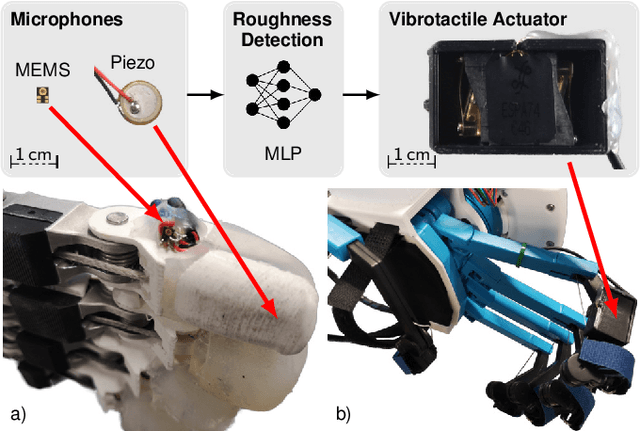
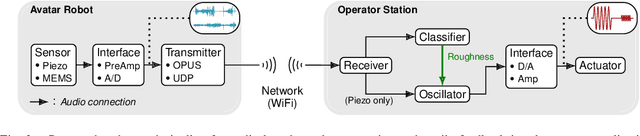
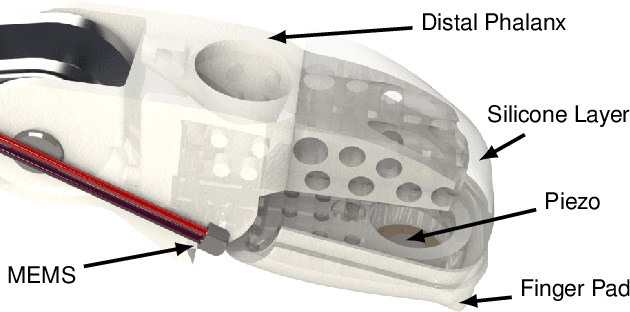

Haptic perception is incredibly important for immersive teleoperation of robots, especially for accomplishing manipulation tasks. We propose a low-cost haptic sensing and rendering system, which is capable of detecting and displaying surface roughness. As the robot fingertip moves across a surface of interest, two microphones capture sound coupled directly through the fingertip and through the air, respectively. A learning-based detector system analyzes the data in real-time and gives roughness estimates with both high temporal resolution and low latency. Finally, an audio-based haptic actuator displays the result to the human operator. We demonstrate the effectiveness of our system through experiments and our winning entry in the ANA Avatar XPRIZE competition finals, where impartial judges solved a roughness-based selection task even without additional vision feedback. We publish our dataset used for training and evaluation together with our trained models to enable reproducibility.
Robust Immersive Telepresence and Mobile Telemanipulation: NimbRo wins ANA Avatar XPRIZE Finals
Mar 06, 2023
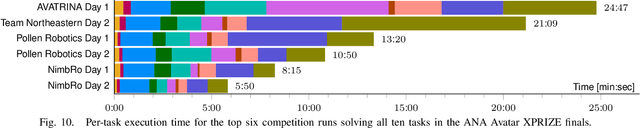
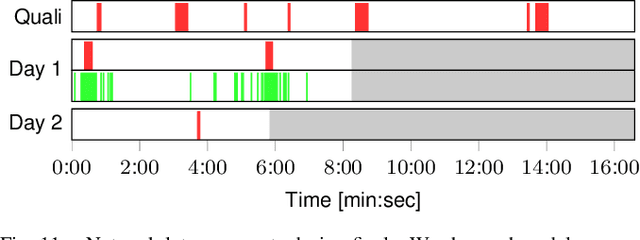

Robotic avatar systems promise to bridge distances and reduce the need for travel. We present the updated NimbRo avatar system, winner of the $5M grand prize at the international ANA Avatar XPRIZE competition, which required participants to build intuitive and immersive telepresence robots that could be operated by briefly trained operators. We describe key improvements for the finals compared to the system used in the semifinals: To operate without a power- and communications tether, we integrate a battery and a robust redundant wireless communication system. Video and audio data are compressed using low-latency HEVC and Opus codecs. We propose a new locomotion control device with tunable resistance force. To increase flexibility, the robot's upper-body height can be adjusted by the operator. We describe essential monitoring and robustness tools which enabled the success at the competition. Finally, we analyze our performance at the competition finals and discuss lessons learned.
Target Chase, Wall Building, and Fire Fighting: Autonomous UAVs of Team NimbRo at MBZIRC 2020
Jan 11, 2022

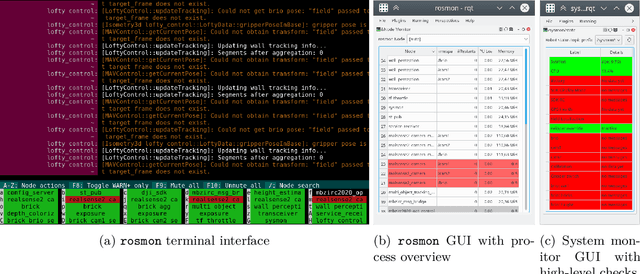

The Mohamed Bin Zayed International Robotics Challenge (MBZIRC) 2020 posed diverse challenges for unmanned aerial vehicles (UAVs). We present our four tailored UAVs, specifically developed for individual aerial-robot tasks of MBZIRC, including custom hardware- and software components. In Challenge 1, a target UAV is pursued using a high-efficiency, onboard object detection pipeline to capture a ball from the target UAV. A second UAV uses a similar detection method to find and pop balloons scattered throughout the arena. For Challenge 2, we demonstrate a larger UAV capable of autonomous aerial manipulation: Bricks are found and tracked from camera images. Subsequently, they are approached, picked, transported, and placed on a wall. Finally, in Challenge 3, our UAV autonomously finds fires using LiDAR and thermal cameras. It extinguishes the fires with an onboard fire extinguisher. While every robot features task-specific subsystems, all UAVs rely on a standard software stack developed for this particular and future competitions. We present our mostly open-source software solutions, including tools for system configuration, monitoring, robust wireless communication, high-level control, and agile trajectory generation. For solving the MBZIRC 2020 tasks, we advanced the state of the art in multiple research areas like machine vision and trajectory generation. We present our scientific contributions that constitute the foundation for our algorithms and systems and analyze the results from the MBZIRC competition 2020 in Abu Dhabi, where our systems reached second place in the Grand Challenge. Furthermore, we discuss lessons learned from our participation in this complex robotic challenge.
NimbRo Avatar: Interactive Immersive Telepresence with Force-Feedback Telemanipulation
Sep 28, 2021

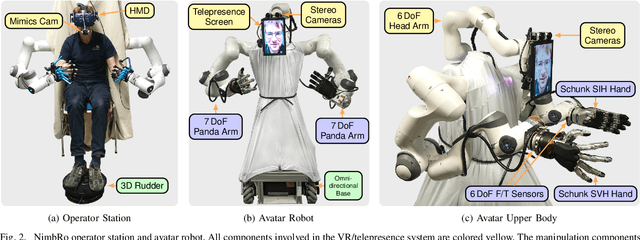
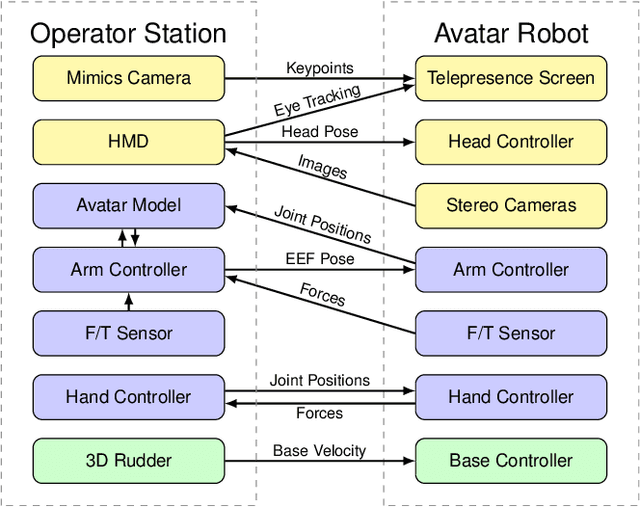
Robotic avatars promise immersive teleoperation with human-like manipulation and communication capabilities. We present such an avatar system, based on the key components of immersive 3D visualization and transparent force-feedback telemanipulation. Our avatar robot features an anthropomorphic bimanual arm configuration with dexterous hands. The remote human operator drives the arms and fingers through an exoskeleton-based operator station, which provides force feedback both at the wrist and for each finger. The robot torso is mounted on a holonomic base, providing locomotion capability in typical indoor scenarios, controlled using a 3D rudder device. Finally, the robot features a 6D movable head with stereo cameras, which stream images to a VR HMD worn by the operator. Movement latency is hidden using spherical rendering. The head also carries a telepresence screen displaying a synthesized image of the operator with facial animation, which enables direct interaction with remote persons. We evaluate our system successfully both in a user study with untrained operators as well as a longer and more complex integrated mission. We discuss lessons learned from the trials and possible improvements.
FaDIV-Syn: Fast Depth-Independent View Synthesis
Jun 24, 2021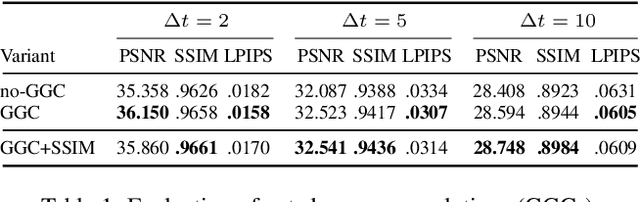
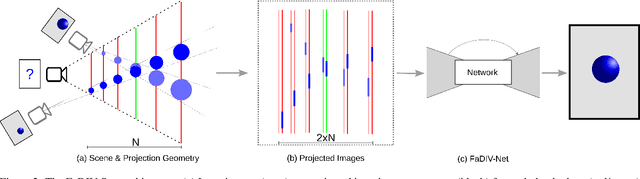
We introduce FaDIV-Syn, a fast depth-independent view synthesis method. Our multi-view approach addresses the problem that view synthesis methods are often limited by their depth estimation stage, where incorrect depth predictions can lead to large projection errors. To avoid this issue, we efficiently warp multiple input images into the target frame for a range of assumed depth planes. The resulting tensor representation is fed into a U-Net-like CNN with gated convolutions, which directly produces the novel output view. We therefore side-step explicit depth estimation. This improves efficiency and performance on transparent, reflective, and feature-less scene parts. FaDIV-Syn can handle both interpolation and extrapolation tasks and outperforms state-of-the-art extrapolation methods on the large-scale RealEstate10k dataset. In contrast to comparable methods, it is capable of real-time operation due to its lightweight architecture. We further demonstrate data efficiency of FaDIV-Syn by training from fewer examples as well as its generalization to higher resolutions and arbitrary depth ranges under severe depth discretization.
Team NimbRo's UGV Solution for Autonomous Wall Building and Fire Fighting at MBZIRC 2020
May 27, 2021
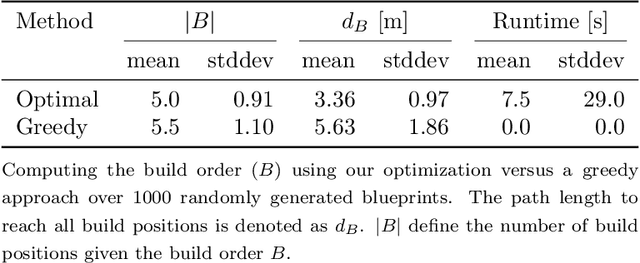

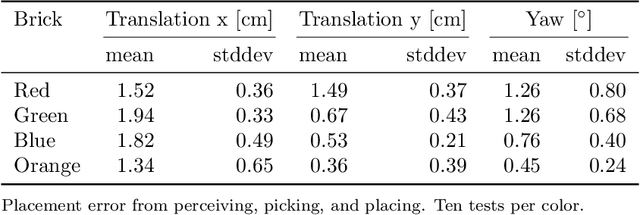
Autonomous robotic systems for various applications including transport, mobile manipulation, and disaster response are becoming more and more complex. Evaluating and analyzing such systems is challenging. Robotic competitions are designed to benchmark complete robotic systems on complex state-of-the-art tasks. Participants compete in defined scenarios under equal conditions. We present our UGV solution developed for the Mohamed Bin Zayed International Robotics Challenge 2020. Our hard- and software components to address the challenge tasks of wall building and fire fighting are integrated into a fully autonomous system. The robot consists of a wheeled omnidirectional base, a 6 DoF manipulator arm equipped with a magnetic gripper, a highly efficient storage system to transport box-shaped objects, and a water spraying system to fight fires. The robot perceives its environment using 3D LiDAR as well as RGB and thermal camera-based perception modules, is capable of picking box-shaped objects and constructing a pre-defined wall structure, as well as detecting and localizing heat sources in order to extinguish potential fires. A high-level planner solves the challenge tasks using the robot skills. We analyze and discuss our successful participation during the MBZIRC 2020 finals, present further experiments, and provide insights to our lessons learned.